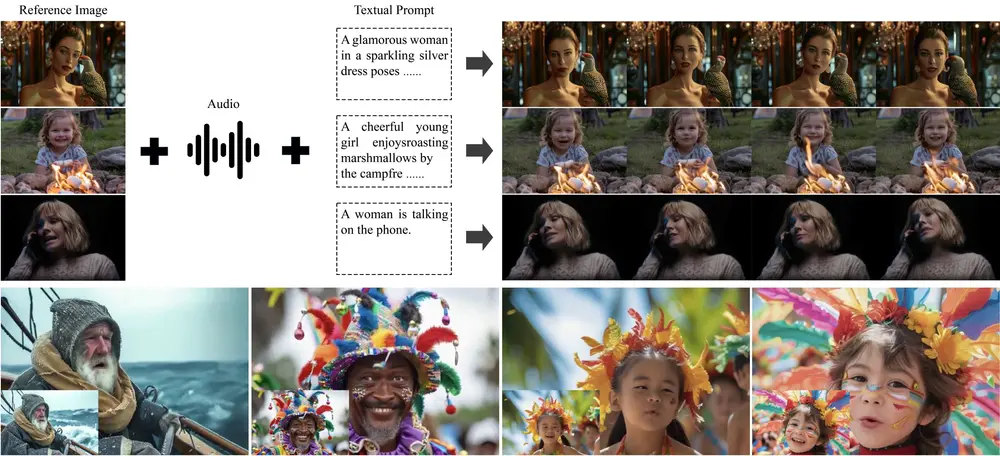
在主体到视频(Subject-to-Video, S2V)生成任务中,目标是根据用户提供的多张目标主体参考图像和文本提示,合成一段主体身份一致、动作自然、背景可控的视频。尽管近期 S2V 模型取得进展,但现有方法仍面临两大核心挑战:
- 多主体混淆:当输入多张参考图时,模型难以区分“同一个主体的不同视角”与“多个不同主体”,导致身份漂移;
- 背景泄漏:参考图像中的背景细节被错误地复制到生成视频中,破坏场景一致性。
为系统性解决这些问题,智谱AI推出了 Kaleido —— 一个从数据构建到模型注入机制全面优化的 S2V 生成框架。它在主体一致性、背景解耦、跨姿态泛化方面显著优于现有方法。
- 项目主页:https://criliasmiller.github.io/Kaleido_Project
- GitHub:https://github.com/zai-org/Kaleido
- 模型:https://huggingface.co/zai-org/Kaleido-14B-S2V
问题根源与解决方案
问题 1:训练数据质量与多样性不足
现有 S2V 数据集普遍存在:
- 高质量主体视频稀缺;
- 缺乏“跨配对”样本(即主体来自同一身份但背景/姿态不同);
- 背景与主体高度耦合,模型难以学习解耦表示。
Kaleido 的应对:构建专用数据管道
- 从大规模视频中切分片段,自动生成字幕;
- 基于主体分类体系(如“人物”“动物”“物体”)自动识别候选主体;
- 使用 Grounding DINO + SAM 精确分割主体区域;
- 通过 CLIP 分类、IoU 过滤、尺寸阈值、人工质量检查四重过滤,剔除低质样本;
- 背景填充增强:将参考图像背景替换为纯色或噪声,迫使模型从文本提示中合成背景,而非复制参考图;
- 姿态增强:利用 Flux Redux 为同一主体生成新姿态图像,提升模型对身份而非姿态的泛化能力。
问题 2:多参考图注入机制不鲁棒
传统方法将多张参考图简单拼接或平均融合,易导致特征混淆。
Kaleido 的应对:参考旋转位置编码(R-RoPE)
- 在扩散 Transformer 的输入序列中,将参考图像特征与视频噪声序列沿序列维度拼接;
- 为参考图像引入空间偏移的位置编码,使其在时空嵌入空间中与视频帧可区分但关联;
- 该机制使模型能稳定对齐多视角参考图,同时避免身份混合。
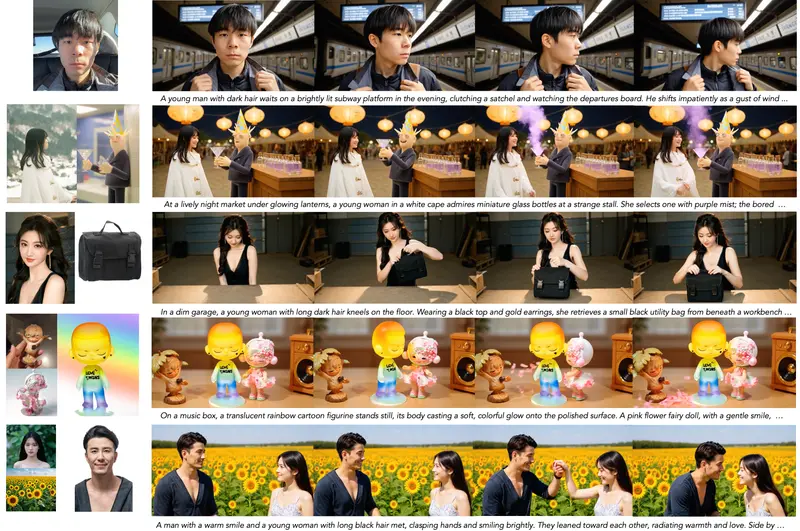
主要功能与优势
✅ 多主体一致性
- 支持单主体或多主体场景;
- 即使输入包含不同姿态、光照、背景的参考图,仍能保持身份稳定;
- 在多人交互场景中,各主体身份互不干扰。
✅ 背景解耦
- 生成背景完全由文本提示控制,不复制参考图背景;
- 可实现“同一角色在不同场景中行动”的灵活创作。
✅ 高质量生成
- 在时间连贯性、动作自然度、文本对齐方面表现优异;
- 支持复杂动作(如转身、跳跃)与精细细节(如服装纹理、面部表情)。
实验结果
在多个 S2V 基准上的测试表明:
- 量化指标:Kaleido 在主体一致性(S2V Consistency)上达到 0.723,显著优于开源(如 Wan、CogVideoX)与闭源模型;
- 用户研究:在视频质量、身份保真、背景合理、文本对齐四项指标上,Kaleido 均获最高偏好率;
- 定性对比:在多主体、复杂背景、跨姿态等挑战性场景中,Kaleido 无明显身份漂移或背景泄漏,而基线模型常出现“半人半兽”或“背景粘连”现象。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











