在基于扩散模型的视频生成系统中,视频变分自编码器(VAE) 扮演着关键角色:它将像素空间视频压缩到潜在空间,供扩散模型高效训练。然而,现有视频 VAE 的设计往往过度聚焦于重建保真度,却忽视了一个更根本的问题:潜在空间的结构是否“适合扩散训练”?
智谱AI的研究团队发现:更强的重建能力并不总能带来更好的生成效果。根本原因在于,潜空间的统计特性(尤其是其频谱结构)直接影响扩散模型的收敛速度与生成质量。
- 项目主页:https://zhazhan.github.io/ssvae.github.io
- GitHub:https://github.com/zai-org/SSVAE
- 模型:https://huggingface.co/zai-org/SSVAE
为此,团队提出了 SSVAE(Spectral-Structured VAE) —— 一种通过显式优化潜空间谱特性来提升“可扩散性”的新一代视频 VAE。
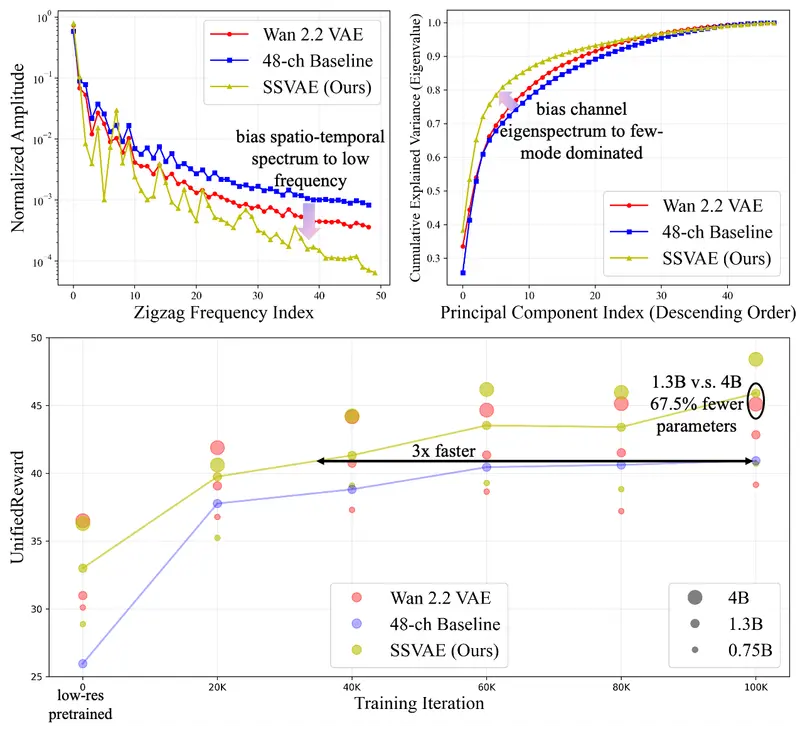
核心发现:什么样的潜空间更适合扩散训练?
通过对多个 SOTA 视频 VAE 的潜变量进行统计分析,研究识别出两类关键频谱特性:
- 低频偏置的时空频率谱
- 潜在表示中应包含更多低频时空信号(对应平滑运动、整体结构);
- 高频噪声成分越少,扩散模型在去噪过程中越容易恢复细节,优化路径更平滑。
- 少数模式偏置的通道特征谱
- 潜在通道应呈现低有效秩(即由少数基向量主导);
- 这种“稀疏模式”结构使扩散模型能更快学习到语义动作规律,而非拟合噪声。
关键技术:轻量级正则化,无需修改架构
SSVAE 并未重新设计 VAE 主干,而是引入两个轻量、通用、可插拔的正则化机制:
1. 局部相关性正则化(Local Correlation Regularization, LCR)
- 在标准化后的潜空间中,计算局部时空窗口内特征向量的平均成对相关性;
- 通过 hinge loss 最大化该相关性,从而增强局部平滑性,诱导低频偏置;
- 开销极低,仅增加少量计算,不影响主干训练流程。
2. 潜变量掩码重建(Latent Masked Reconstruction, LMR)
- 在训练时,随机将部分潜向量替换为可学习的掩码标记;
- 解码器需在缺失信息下重建原视频,这迫使潜空间压缩为少数有效模式;
- 同时提升了解码器对潜空间噪声的鲁棒性,间接改善生成稳定性。
两大机制均不依赖特定 VAE 架构,可直接集成到 CogVideoX、Wan 等现有模型中。
实验结果:更快、更好、更小
在 17×512×512 分辨率的文生视频任务上,SSVAE 表现如下:
- 🚀 3 倍收敛加速:达到相同训练损失所需步数仅为基线的 1/3;
- 📈 10% 生成质量提升:在 UnifiedReward(综合视频奖励)上显著领先;
- 🏆 超越 SOTA,参数更少:
- SSVAE(1.3B 参数)在 FVD、VideoAlign 等指标上优于 Wan 2.2 VAE(4B 参数);
- 生成视频在时间连贯性、动作合理性、文本对齐方面更优,伪影更少。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











