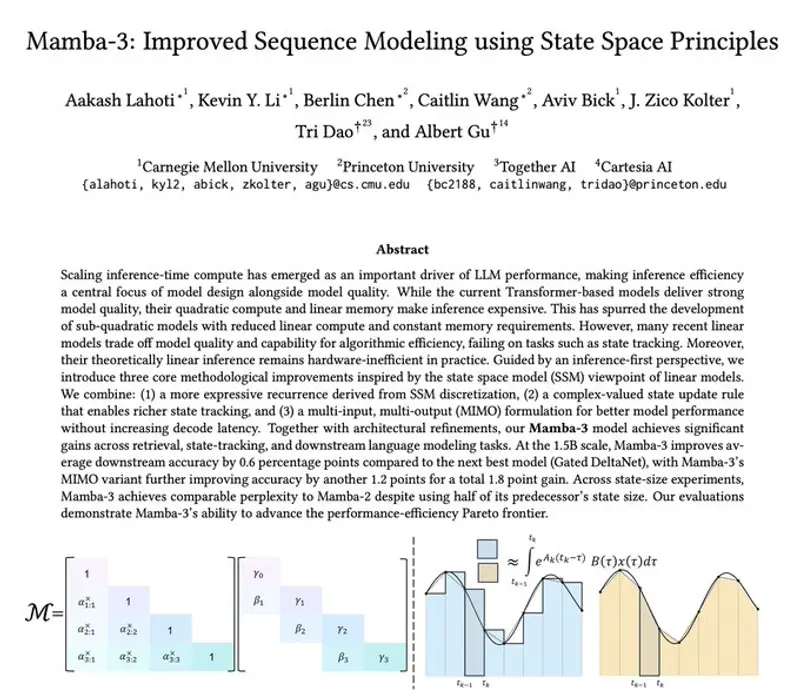
开源架构 Mamba-3 正式发布:推理速度超越 Transformer,同性能下显存占用减半,Apache 2.0 许可商用免费生成式 AI 的基石——Transformer 架构,自 2017 年诞生以来统治了行业近十年。然而,其高昂的计算成本和线性增长的内存需求,让大规模推理变得极其昂贵。 现在,挑战者来了。 由卡内基梅隆...新技术# Mamba-3# Transformer1周前0210
基于Transformer架构的新型视频生成模型Snap Video来自Snap、特伦托大学、加州大学默塞德分校、布鲁诺·凯斯勒基金会的研究人员推出新型视频生成模型Snap Video,此模型基于Transformer架构,目标是将文本描述转换成高质量的视频内容。 项...新技术# Snap Video# Transformer# 视频生成模型2年前06210
新型图像生成模型FiT:基于Transformer架构,可以生成无限制分辨率和长宽比的图像FiT(Flexible Vision Transformer)是一款新型图像生成模型,基于Transformer架构,旨在生成具有无限制分辨率和长宽比的图像。 GitHub 论文 模型 传统的图像生...新技术# FiT# Transformer# 图像生成模型2年前08290