生成式 AI 的基石——Transformer 架构,自 2017 年诞生以来统治了行业近十年。然而,其高昂的计算成本和线性增长的内存需求,让大规模推理变得极其昂贵。
现在,挑战者来了。
由卡内基梅隆大学 Albert Gu 和普林斯顿大学 Tri Dao 领衔的原始团队,正式发布了 Mamba-3。这是一个全新的状态空间模型(SSM)架构,不仅在语言建模性能上超越了 Transformer,更实现了推理优先的范式转变。
- GitHub:https://github.com/state-spaces/mamba
- 论文:https://arxiv.org/abs/2603.15569
- 官方介绍:https://goombalab.github.io/blog/2026/mamba3-part1
最关键的是:Mamba-3 已采用宽松的 Apache 2.0 许可证开源,允许任何人免费用于商业用途。
核心突破:从“训练优先”到“推理优先”
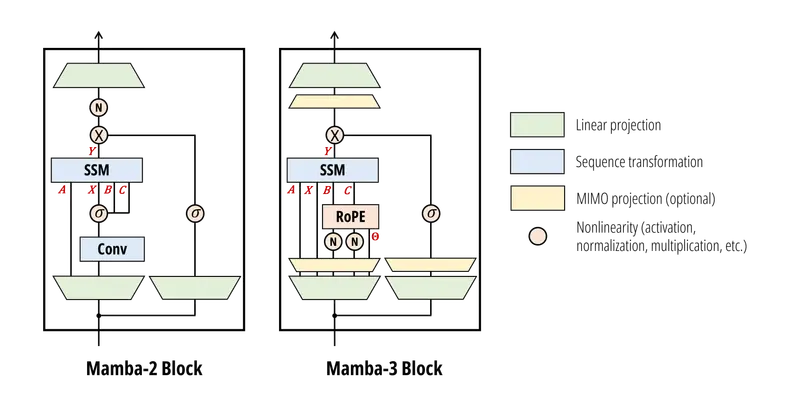
Mamba-2 曾专注于打破预训练速度的瓶颈,而 Mamba-3 的目标直指 “冷 GPU”问题:
- 痛点:在传统模型解码过程中,GPU 的计算核心常常处于闲置状态,等待数据从内存搬运过来(内存受限)。
- 解决方案:Mamba-3 引入了 多输入多输出 (MIMO) 机制。通过在每一步并行执行多达 4 倍的数学运算,它充分利用了那些曾经“闲置”的算力。
- 结果:模型在生成每个 token 时能进行更多的“思考”,却不增加用户的等待时间。这就是真正的“免费性能”。
性能实测:更小、更快、更聪明
在语言建模领域,每一个百分点的提升都来之不易。Mamba-3 交出了一份惊人的成绩单:
| 指标 | Mamba-3 表现 | 对比优势 |
|---|---|---|
| 语言建模能力 | 相对提升 近 4% | 在 15 亿参数规模下,准确率比标准 Transformer 高出 2.2 个百分点 |
| 显存效率 | 状态大小减半 | 在使用只有 Mamba-2 一半 内部状态大小的情况下,实现了相当的困惑度(智能水平) |
| 推理吞吐量 | 翻倍 | 相同硬件条件下,推理速度理论上可提升一倍 |
| 逻辑推理 | 完美解决 | 修复了前代无法处理的状态跟踪任务,逻辑能力媲美最先进系统 |
什么是困惑度 (Perplexity)?
把它想象成模型的“惊讶程度”。困惑度越低,模型对下一个词的预测越确定,代表它越“聪明”。Mamba-3 用更少的资源达到了更低的困惑度,意味着更高的智商,更低的成本。
三大技术飞跃:如何做到?
Mamba-3 并非简单的修补,而是进行了底层的数学重构:
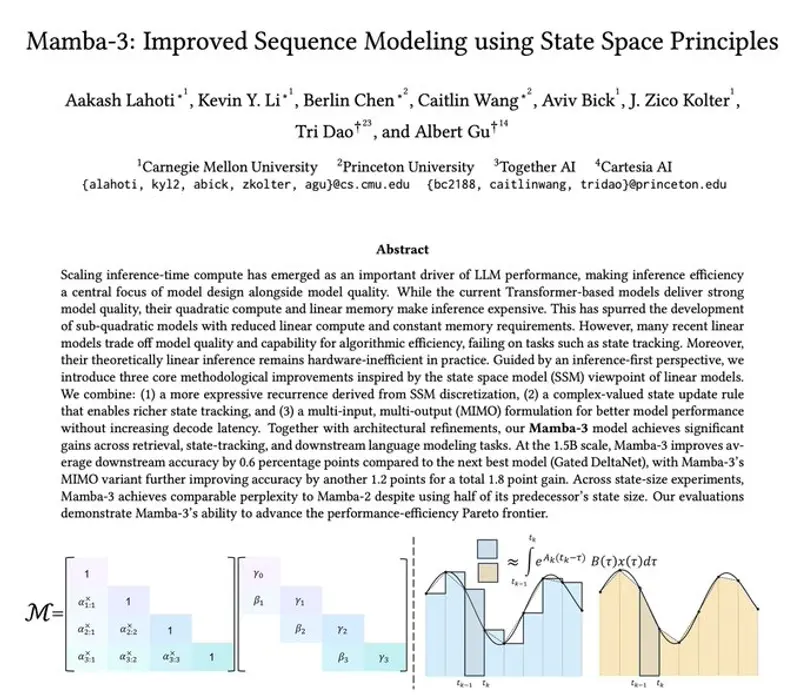
1. 指数梯形离散化 (Exponential Trapezoidal Discretization)
- 升级:从一阶近似升级为二阶精确近似。
- 效果:在核心循环中引入了“隐式卷积”,移除了困扰循环架构多年的短因果卷积限制,使模型更稳定、更精准。
2. 复数值 SSM 与 "RoPE 技巧"
- 痛点:以前的线性模型因使用实数矩阵,无法表示“旋转”逻辑,导致在简单推理任务上翻车。
- 突破:Mamba-3 将状态空间升级为复数值。利用 "RoPE 技巧",模型能像拥有“内部指南针”一样处理旋转动态,完美解决状态跟踪和逻辑难题。
3. MIMO:提高算术强度
- 原理:从单输入单输出 (SISO) 转变为 多输入多输出 (MIMO)。
- 效果:将原本受限于内存带宽的操作,转化为高密度的矩阵乘法。这极大地提高了 FLOPs/内存流量 的比率,让 GPU 的算力不再被内存带宽“卡脖子”。
对企业与开发者的意义
Mamba-3 的发布,不仅仅是学术论文的更新,更是 AI 部署成本的战略转折点:
- 总拥有成本 (TCO) 骤降:在同等性能下,显存占用减半意味着你可以用更便宜的显卡,或在一块卡上跑两倍的并发量。
- 智能体 (Agent) 的福音:随着 AI 应用从单次问答转向复杂的长程智能体工作流,低延迟和高吞吐成为刚需。Mamba-3 专为防止 GPU“冷却”而设计,是运行实时智能体的理想底座。
- 混合架构未来:业界趋势已不再是“二选一”,而是“混合”。利用 Mamba-3 处理长上下文记忆(高效),结合 Transformer 处理精准检索(准确),将是未来企业 AI 的最佳实践。
可用性与许可
- 开源地址:代码已在 GitHub 发布,模型权重可用。
- 许可证:Apache 2.0。
- ✅ 免费商用
- ✅ 可修改
- ✅ 可分发
- ✅ 无需公开专有源码
- 适用场景:长上下文应用、实时推理智能体、高吞吐生产环境、边缘设备部署。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...