延世大学、NAVER AI LAB和韩国科学技术研究院的研究人员推出一种新的数据增强方法,名为MaskRIS(Masked Referring Image Segmentation),它用于改进指代表像分割(Referring Image Segmentation, RIS)任务的性能。RIS是一种高级的视觉-语言任务,目标是根据自由形式的文本描述在图像中识别和分割出特定的对象。
例如,你有一张公园的图片和一段文本描述:“坐在长椅上的穿红衣服的女人”。RIS任务的目标就是自动识别并分割出符合这段描述的具体人物。MaskRIS通过引入图像和文本的掩码(masking)策略,增强模型对不完整信息和遮挡情况的处理能力,从而提高分割的准确性。
主要功能
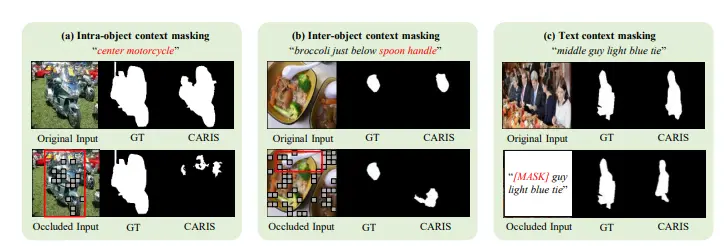
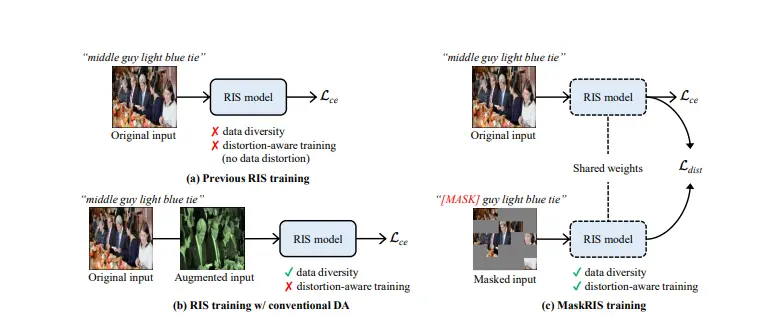
MaskRIS的主要功能是提供一种有效的数据增强框架,以改善RIS模型的训练效果。它通过图像和文本掩码,结合扭曲感知上下文学习(Distortion-aware Contextual Learning, DCL),来增强模型对遮挡、不完整信息和各种语言复杂性的鲁棒性。
主要特点
- 图像和文本掩码:MaskRIS不仅对图像应用掩码,还对文本描述进行掩码,以增强模型处理视觉和语言复杂性的能力。
- 扭曲感知上下文学习(DCL):通过原始输入和掩码输入的两个互补路径来处理输入,增强模型对掩码输入的特征鲁棒性。
- 自蒸馏框架:利用原始输入的软目标来减少训练复杂性,增强模型泛化能力。
- 与现有方法的兼容性:MaskRIS可以轻松应用于各种RIS模型,并在全监督和弱监督设置中都取得了性能提升。
工作原理
MaskRIS的工作原理包括以下几个步骤:
- 输入掩码:对图像和文本描述应用掩码,以保留关键的空间信息和属性细节,同时扩大数据多样性。
- DCL框架:通过原始输入和掩码输入的两个路径来处理输入,其中主路径确保训练稳定性,次路径增强数据多样性和鲁棒性。
- 蒸馏损失:通过原始输入和掩码输入的预测之间的二元交叉熵损失来对齐,鼓励模型在原始和掩码输入上做出一致的预测。
具体应用场景
MaskRIS的应用场景包括但不限于:
- 人机交互:在语言驱动的人类-机器人交互中,RIS可以帮助机器人根据人类的自然语言指令识别和操作特定对象。
- 图像编辑:在高级图像编辑应用中,RIS可以让用户通过描述来选择和编辑图像中的特定区域。
- 辅助视觉:对于视觉障碍人士,RIS可以提供一种通过语音命令识别和解释周围环境的方式。
- 自动驾驶:在自动驾驶车辆中,RIS可以帮助车辆理解和响应交通指示牌或道路标志上的文本指令。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











