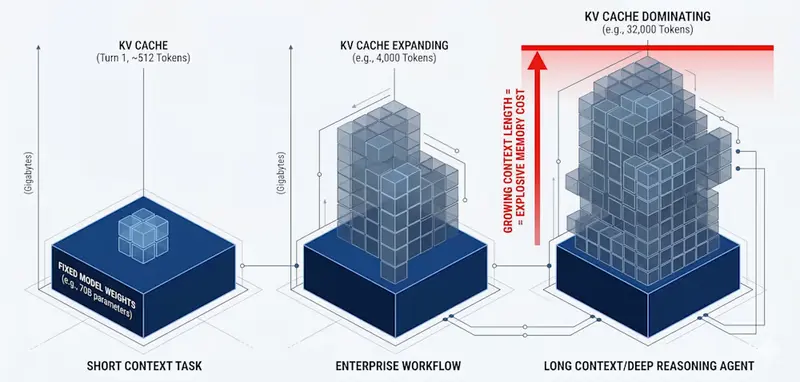
在大语言模型(LLM)的推理过程中,有一个长期存在的痛点:随着对话变长,显存占用呈线性甚至指数级增长。这就是著名的 KV 缓存(Key-Value Cache) 瓶颈。
现在,英伟达(NVIDIA)的研究人员提出了一种革命性的解决方案——KV 缓存变换编码(KVTC, Key-Value Cache Transform Coding)。这项技术能在不修改模型权重的前提下,将 LLM 追踪对话历史所需的内存占用最高缩小 20 倍,同时将首 token 响应时间(Time to First Token, TTFT)缩短至原来的 1/8。
核心突破:像压缩 JPEG 图片一样压缩 AI 记忆
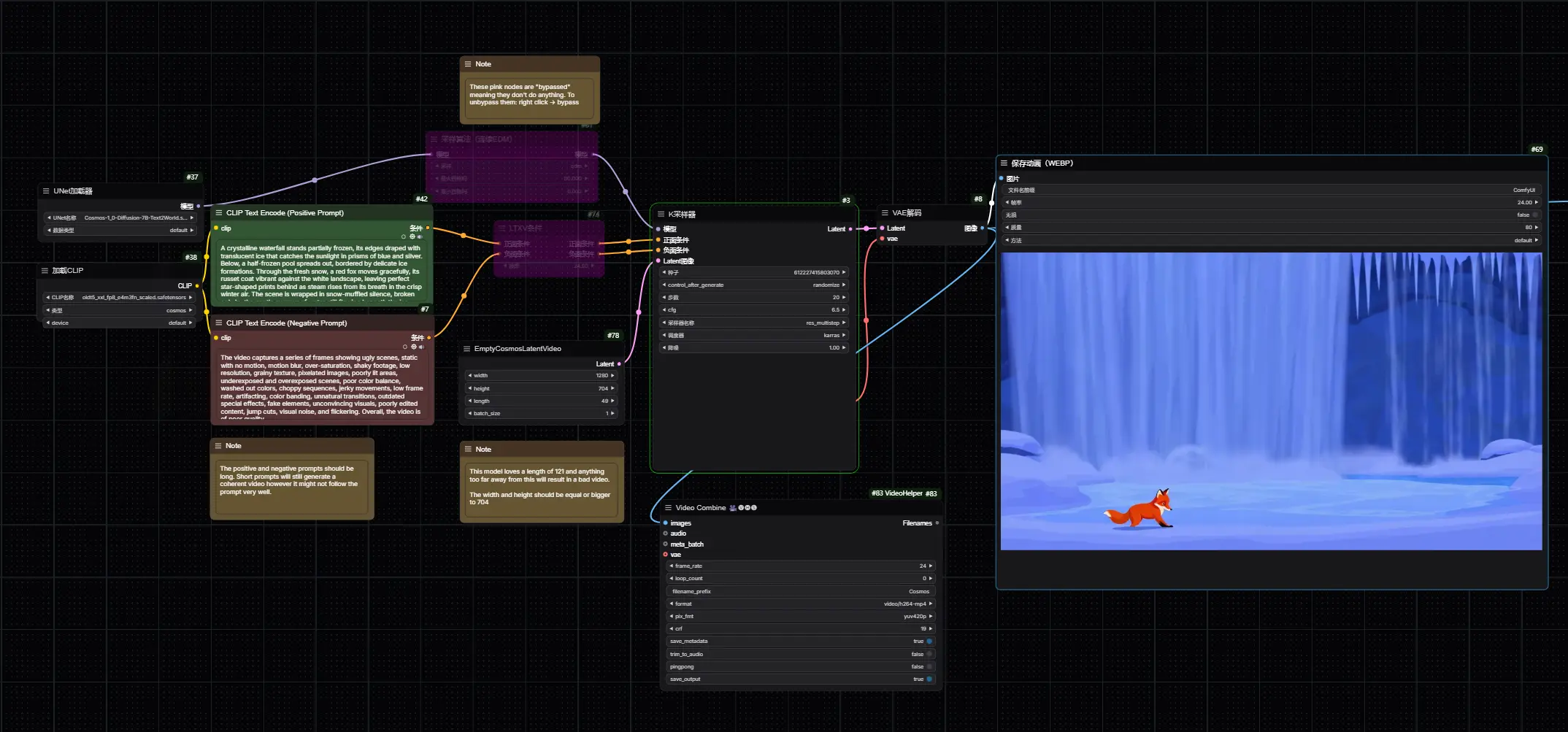
1. 为什么 KV 缓存是瓶颈?
在多轮对话或长上下文编程中,LLM 需要记住之前的所有内容,以避免重复计算。这些“记忆”存储在 KV 缓存中。
- 问题:随着上下文变长,KV 缓存迅速膨胀至数 GB,导致 GPU 显存耗尽,成为限制并发用户数和响应速度的最大障碍。
- 现有方案局限:传统的量化、稀疏化往往需要修改模型权重,或者在压缩时引入高延迟和精度损失。
2. KVTC 是如何工作的?
英伟达借鉴了经典媒体压缩(如 JPEG)中的变换编码思想,利用 KV 张量天然的低秩结构(即数据高度相关,冗余度大),通过三步走实现高效压缩:
- PCA 对齐(离线):使用主成分分析(PCA)识别数据中最关键的特征,剔除冗余。这一步只需在模型校准阶段做一次,不影响推理速度。
- 动态比特分配:自动为关键主成分分配高精度,为次要成分分配低精度甚至直接丢弃(零比特)。
- GPU 并行熵编码:利用英伟达 nvCOMP 库,在 GPU 上并行执行 DEFLATE 熵编码,将数据打包成紧凑的字节数组。
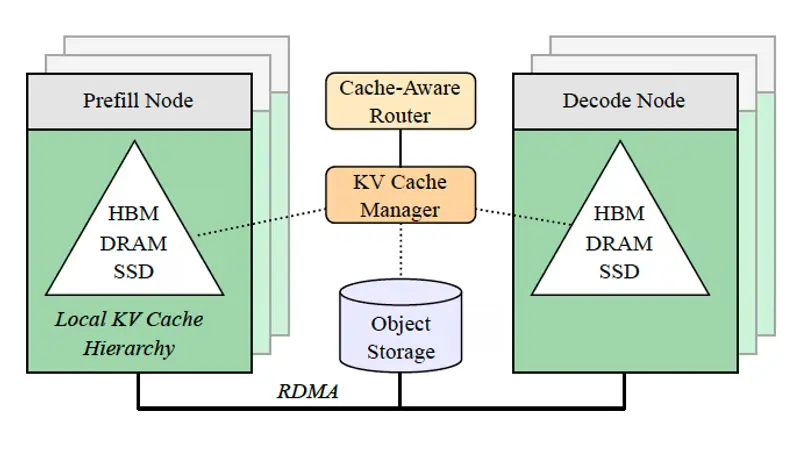
关键优势:整个过程是非侵入式的。它运行在传输层附近,无需更改模型权重或代码,即插即用。
性能实测:20 倍压缩,精度几乎无损
英伟达在多种主流模型(Llama 3 系列、Mistral NeMo、Qwen 2.5 等)上进行了广泛测试,结果令人惊叹:
| 指标 | KVTC 表现 | 对比传统方案 (KIVI/GEAR/H2O) |
|---|---|---|
| 压缩率 | 最高 20 倍 (极端可达 64 倍) | 通常仅 4-5 倍,再高则崩溃 |
| 精度损失 | < 1% (几乎不可感知) | 5 倍压缩时即出现严重下降 |
| 首字延迟 | 降低 8 倍 (3s → 380ms) | 解压慢或需重新计算,延迟高 |
| 适用性 | 长上下文、多轮对话、智能体 | 短对话尚可,长文本失效 |
- 案例:对于 Qwen 2.5 1.5B 模型,单 token 内存从 29 KB 降至 3.2 KB(8 倍压缩),编码能力几乎无损。
- 长文本优势:在处理 8000 token 提示时,原始模型重算需 3 秒,而 KVTC 解压仅需 380 毫秒,极大提升了用户体验。
商业价值:为企业 AI 降本增效
对于依赖智能体(Agent)和长上下文的企业应用,KVTC 意味着:
- 显存成本骤降:同样的 GPU 可以服务更多用户,或运行更长的上下文窗口。
- 延迟大幅降低:避免重新计算被丢弃的缓存,响应速度提升至原来的 8 倍。
- 提示复用增强:高效的缓存管理使得复杂工作流(如迭代式代码生成、RAG 检索)更加流畅。
- 无缝集成:即将集成到 Dynamo 框架的 KV 块管理器中,并与 vLLM 等开源推理引擎兼容,部署门槛极低。
未来展望:AI 基础设施的标准化一层
英伟达高级深度学习工程师 Adrian Lancucki 指出:“鉴于各种模型架构中 KV 缓存的结构相似性,未来很可能出现一个专用的、标准化的压缩层。”
这就好比今天的视频流媒体离不开 H.264/H.265 压缩一样,未来的 AI 推理基础设施也将把 KV 缓存压缩 视为标配。
- 最佳场景:编码助手、迭代式智能体推理、长文档检索增强生成(RAG)。
- 互补技术:KVTC 可与令牌驱逐方法(如 DMS)结合使用,前者压缩空间维度,后者优化时间维度,进一步挖掘性能潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...