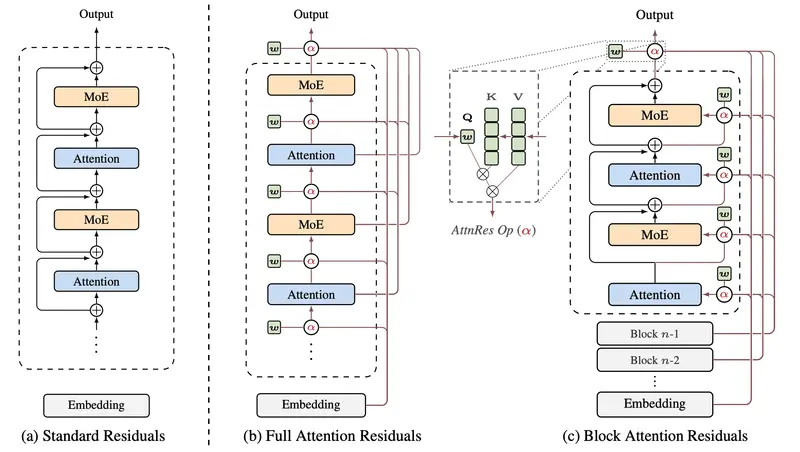
在现代 Transformer 架构中,残差连接(Residual Connection)一直是维持深层网络训练稳定的基石。然而,月之暗面(Moonshot AI)的研究人员指出,这种沿用多年的标准机制存在结构性缺陷:它强制所有先前层的输出以固定权重累积,导致深层网络中单层贡献被逐渐“稀释”。
- GitHub:https://github.com/MoonshotAI/Attention-Residuals
- 论文地址:https://github.com/MoonshotAI/Attention-Residuals/blob/master/Attention_Residuals.pdf
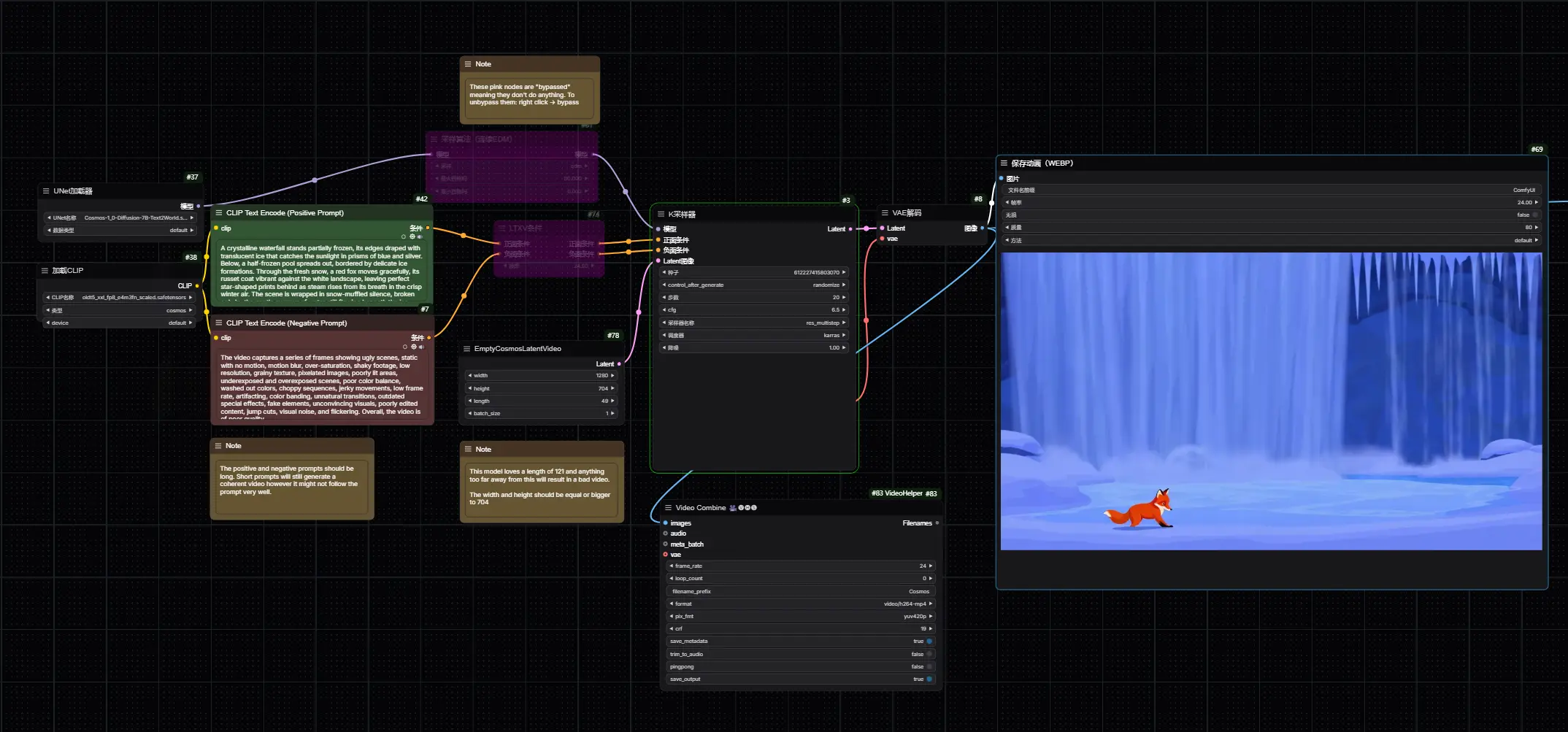
为了解决这一问题,月之暗面正式提出了 Attention Residuals (AttnRes) —— 一种用深度维度注意力替代固定残差混合的全新机制。该成果已集成至其最新 MoE 架构 Kimi Linear 中,并在多项权威基准测试中取得了显著进步。
为什么标准残差成了瓶颈?
研究团队指出了传统 PreNorm 残差连接的三大痛点:
- 缺乏选择性访问:所有层接收相同的聚合状态,无法根据当前层需求(如注意力层 vs 前馈层)动态调整信息来源。
- 信息不可逆损失:一旦信息混入单一残差流,后续层无法 selectively 恢复特定的早期表示。
- 输出增长失衡:为了在不断膨胀的累积状态中保持影响力,较深层被迫产生更大的输出,导致训练不稳定。
核心洞察:如果注意力机制能通过取代时间上的固定循环来改进序列建模,那么同样的逻辑也应适用于网络的深度维度。
核心方案:Attention Residuals (AttnRes)
AttnRes 的核心思想非常优雅:让每一层通过对“深度维度”进行 Softmax 注意力,来动态聚合先前层的表示。
- 工作机制:第 $l$ 层的输入不再是简单的“嵌入 + 之前所有层输出之和”,而是“嵌入 + 之前层输出的加权和”。
- 权重计算:权重是在深度维度(即层与层之间)计算的,而非序列维度。
- 伪查询向量:默认设计中,每一层拥有一个可学习的、特定于层的伪查询向量 ($w_l$),用于查询之前层的关键值(Key/Value)。
- RMSNorm 保护:引入 RMSNorm 防止大幅度的层输出主导注意力权重,确保稳定性。
工程落地:块注意力残差 (Block Attention Residuals)
全量注意力残差虽然强大,但会带来 $O(L^2d)$ 的计算成本和 $O(Ld)$ 的内存开销。为了让其在大规模模型中实用,月之暗面提出了块注意力残差:
- 分块策略:将 $L$ 层划分为 $N$ 个块。
- 块内累积:块内输出先累积成一个代表向量。
- 块间注意力:注意力仅在块级表示上计算。
- 效果:内存和通信开销从 $O(Ld)$ 降至 $O(Nd)$。
- 训练开销:流水线并行下增加 < 4%。
- 推理延迟:典型负载下增加 < 2%。
扩展规律与性能实测
研究团队在五种不同模型规模下进行了严格对比(基线 vs 全注意力 vs 块注意力),结果令人振奋:
1. 缩放定律 (Scaling Laws)
拟合结果显示,AttnRes 实现了更低的验证损失:
- 基线 (PreNorm):L = 1.891 x C-0.057
- 块注意力残差: L = 1.870 x C-0.058
- 全注意力残差: L = 1.865 x C-0.057
结论:在整个计算范围内,块注意力残差达到了相当于基线模型花费 1.25 倍计算量才能达到的损失水平。这意味着用极小的额外开销,换取了显著的等效算力提升。
2. Kimi Linear 实战表现
月之暗面将 AttnRes 集成到了拥有 480 亿总参数 / 30 亿激活参数 的 Kimi Linear MoE 模型中,并在 1.4T token 上预训练。下游任务评估显示全面进步:
| 基准测试 | 基线得分 | AttnRes 得分 | 提升幅度 |
|---|---|---|---|
| MMLU (综合知识) | 73.5 | 74.6 | +1.1 |
| GPQA-Diamond (高难科学) | 36.9 | 44.4 | +7.5 🚀 |
| BBH (复杂推理) | 76.3 | 78.0 | +1.7 |
| Math (数学解题) | 53.5 | 57.1 | +3.6 |
| HumanEval (代码生成) | 59.1 | 62.2 | +3.1 |
| MBPP (代码编程) | 72.0 | 73.9 | +1.9 |
| CMMLU (中文知识) | 82.0 | 82.9 | +0.9 |
| C-Eval (中文评估) | 79.6 | 82.5 | +2.9 |
特别是在 GPQA-Diamond(高难度科学问答)和 Math(数学)领域,提升尤为显著,证明了 AttnRes 在增强深层推理能力方面的巨大潜力。
关键实现细节
- 初始化技巧:所有伪查询向量初始化为零。这使得训练初期的注意力权重在各层间均匀分布,等同于标准的等权平均残差,从而避免了训练早期的不稳定性。
- 梯度分布:AttnRes 使输出幅度在深度上更受约束,并在各层间更均匀地分布梯度,有效缓解了 PreNorm 的梯度消失/爆炸问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...