
Reka于3月10日开源了Reka Flash 3的最新研究预览版,这是一个拥有210亿参数的模型。Reka Flash 3是一款紧凑的通用模型,擅长通用聊天、编码、指令遵循和函数调用。当前版本在性能上可与OpenAI o1-mini等专有模型竞争,是构建需要低延迟或设备端部署应用的理想选择。它目前是同尺寸类别中最好的模型。
训练过程:该模型从零开始在多样化的公开可用和合成数据集上进行预训练。我们对基础模型使用精选的高质量数据进行指令调整,以优化其性能。在最后阶段,我们使用带有模型和规则奖励的REINFORCE Leave One-Out(RLOO)方法进行强化学习,以提升能力。我们在强化学习阶段注重通用改进,而不是专注于数学或编码的专用模型。我们发布的版本拥有32k的上下文长度。作为早期研究预览版与社区分享,我们的内部版本仍在通过更多训练步骤不断改进。此模型可作为构建领域特定模型或您自己的推理引擎的良好基础。
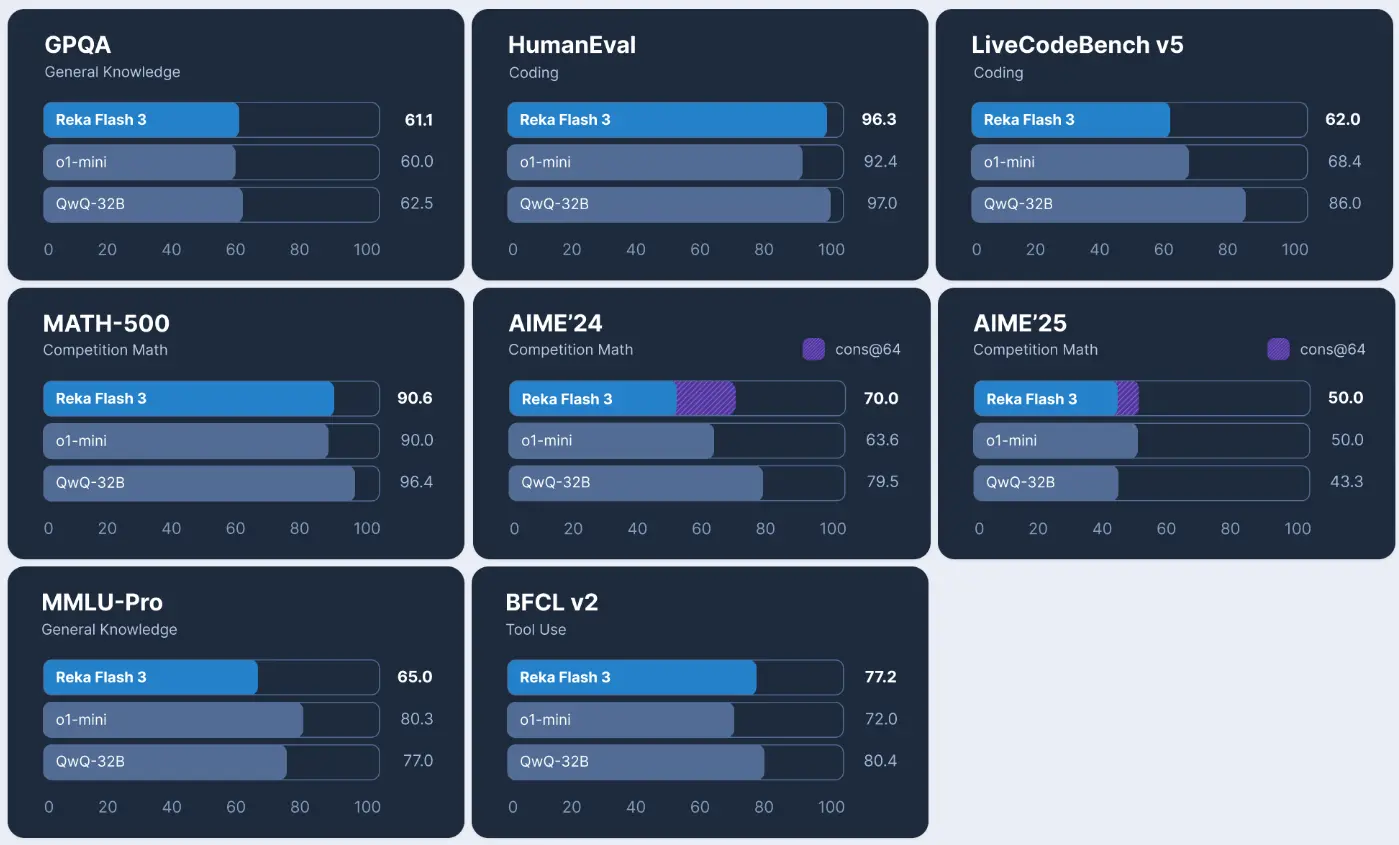
Reka Flash 3与o1-mini和QwQ-32B的性能比较。 我们注意到,尽管QwQ-32B在AIME’24上的表现远超Reka Flash 3,但在AIME’25上二者相当。此外,QwQ-32B可能存在LiveCodeBench-v5数据(2023年5月1日至2025年2月1日)的污染,因为其86.0的得分优于任何现有模型。
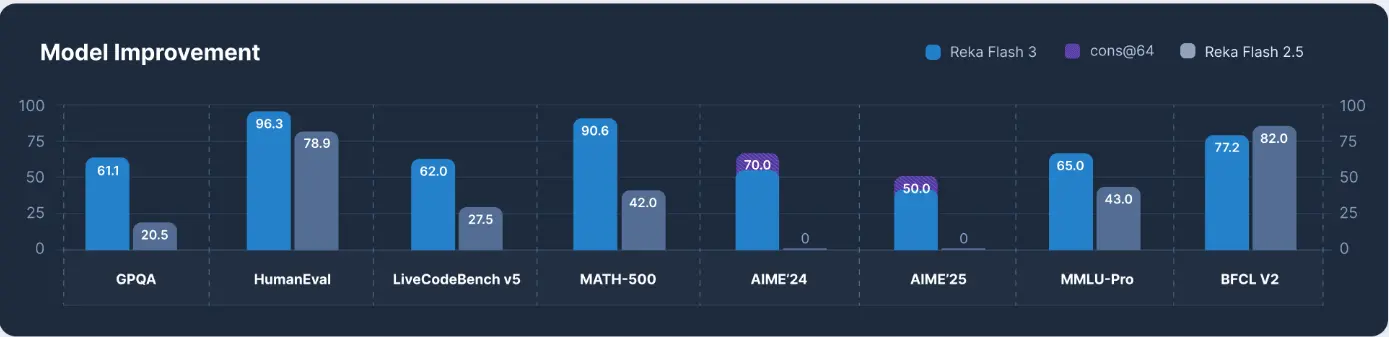
Reka Flash 3相比上一代Reka Flash 2.5有了显著提升
设备端部署:Reka Flash 3是需要低延迟或本地部署的成本效益高应用的绝佳选择。作为一个210亿参数的模型,Reka Flash 3比QwQ-32B少35%的参数。Reka Flash 3的完整精度版本占用39GB(fp16)。通过4位量化压缩,可在保持性能的同时缩小至11GB。相比之下,QwQ-32B在bf16下需要64GB,4位量化后需要18GB。
预算强制:Reka Flash 3会在生成输出前进行思考。我们使用<reasoning> </reasoning>标签标记其思考过程的开始和结束。对于某些问题,模型可能思考较长时间。您可以通过在一定步骤后强制输出</reasoning>来停止其思考过程。我们观察到这种预算强制机制仍能产生合理输出。以下展示了在AIME-2024(cons@16)上不同预算下的性能。
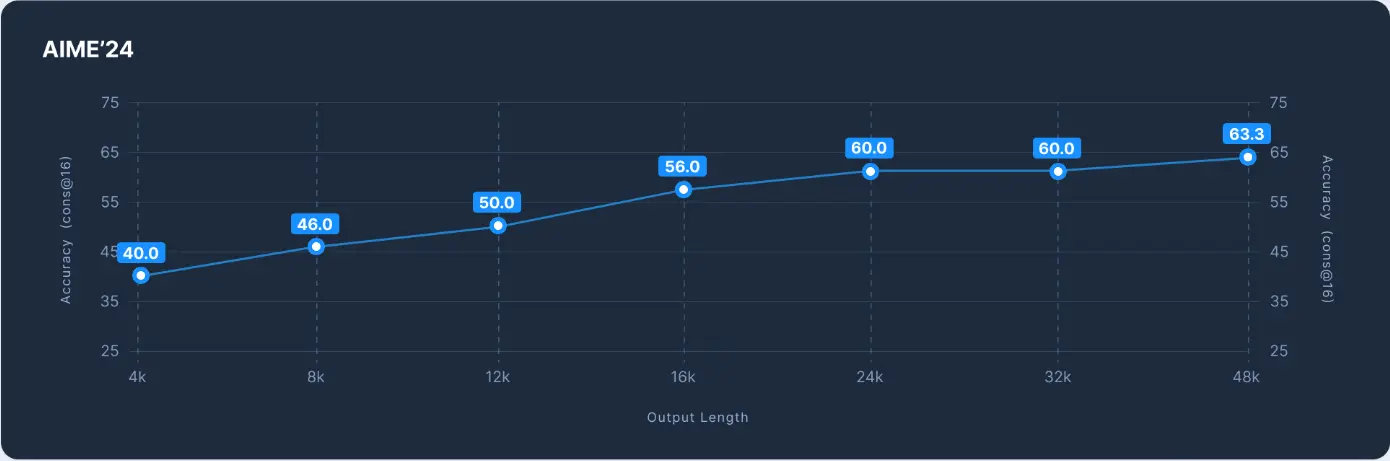
尽管Reka Flash 3的性能随推理时间增加而提升,但可以将其控制在预设预算内
语言支持:此版本主要为英语设计,因此应视为英语专用模型。然而,该模型能在一定程度上理解其他语言,如其在BeleBele上的表现所示。在WMT’23中,该模型获得83.2的COMET评分(涵盖所有语言)。
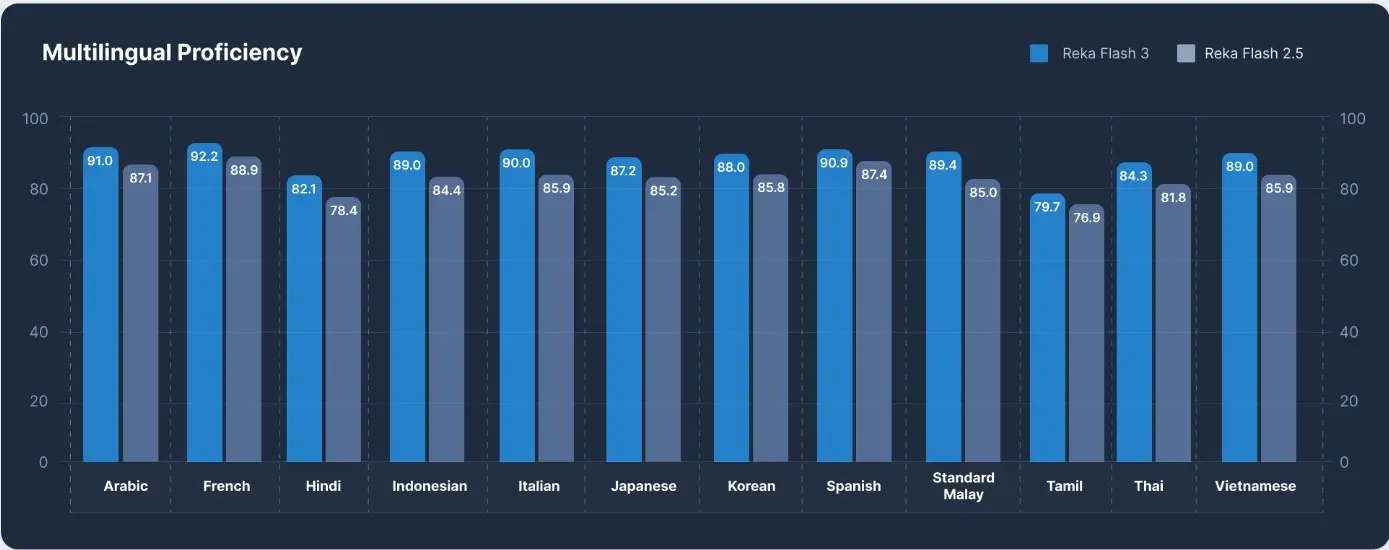
相比上一代Reka Flash,在多语言理解上的改进通过Belebele评分体现
发布说明:
- 作为一个较小的模型,它并非知识密集型任务的最佳选择,其MMLU-Pro得分仅为65.0(尽管仍优于许多更大的模型)。我们建议将Reka Flash 3与网络搜索结合用于知识相关任务。
- 当使用非英语语言提问时,模型常以英语思考。我们观察到这有时会影响非英语输出的质量。
- 该模型未经过广泛的对齐或角色训练。
Reka Flash 3可在Reka Space上试用。我们使用经过改进的版本,与Reka Nexus的首方工具协同工作。
模型权重可根据Apache 2.0许可下载和修改。对于需要强大但轻量级模型的开发者和研究人员来说,这是一个理想选择。需要更长上下文、定制化、多模态,或通过我们的量化方法实现更高速、低内存需求的本地或设备端安全部署的企业可以联系我们。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











