
阿里通义团队开源了其最新代码模型Qwen2.5-Coder,这是一个从其前身CodeQwen1.5显著升级的代码特定模型系列,这个系列包括六个模型:Qwen2.5-Coder-(0.5B/1.5B/3B/7B/14B/32B)。Qwen2.5-Coder是基于Qwen2.5架构构建的,并在超过5.5万亿个token的庞大语料库上继续预训练。通过精心的数据清洗、可扩展的合成数据生成和平衡的数据混合,Qwen2.5-Coder在保持通用和数学技能的同时,展现出了令人印象深刻的代码生成能力。
- GitHub:https://github.com/QwenLM/Qwen2.5-Coder
- 模型:HUGGING FACE/魔塔
- Demo:Qwen2.5-Coder-demo/Qwen2.5-Coder-Artifacts
- 官方介绍:https://qwenlm.github.io/zh/blog/qwen2.5-coder-family
在上个月释出 1.5B、7B 两个尺寸后,此次释出了0.5B、3B、14B、32B 四个尺寸,其中32B超越了一众开源模型,甚至比肩 GPT4o 和 Claude 3.5 Sonnet。官方还演示了如何结合 Cursor 在 1 分钟内实现一个贪吃蛇游戏,并通过 Open WebUI 实现了类似 Claude Artifacts 的功能。此外,通义官网还即将上线代码模式,支持一句话生成网站、小游戏和数据图表等各类可视化应用。
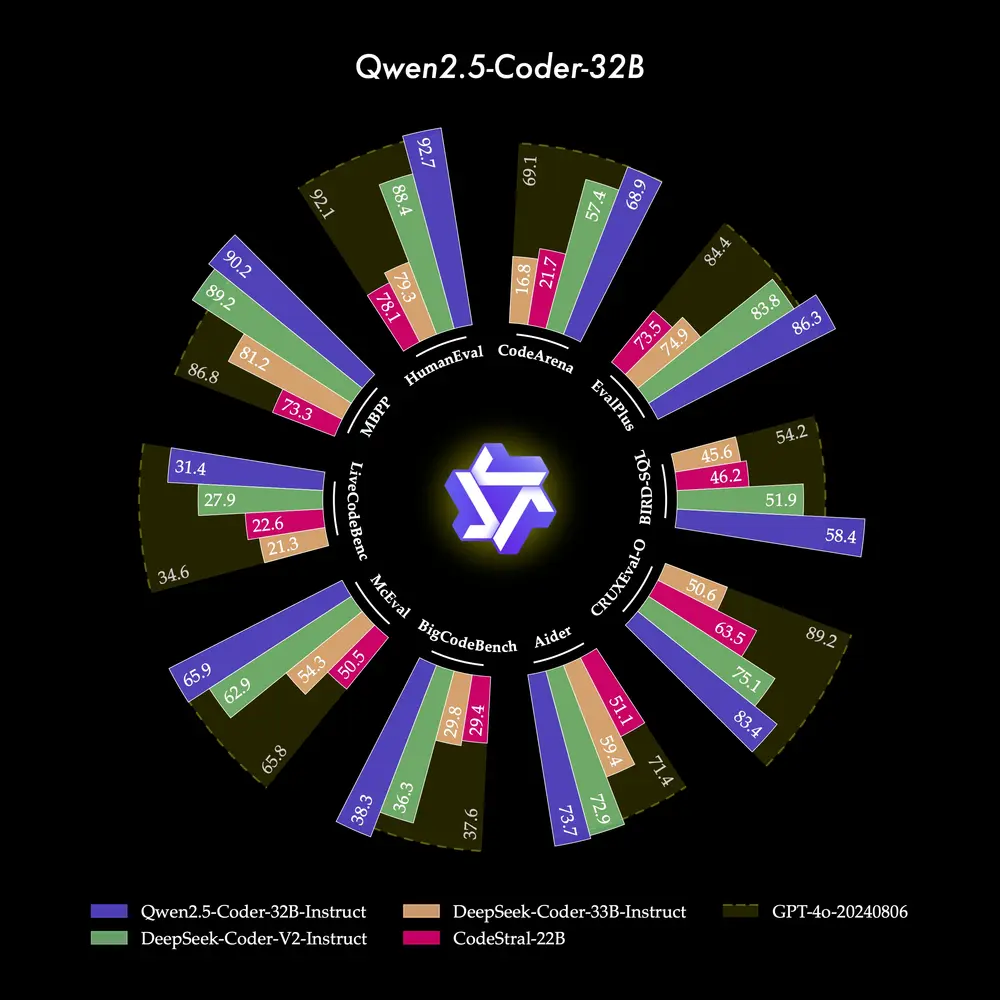
- 强大:Qwen2.5-Coder-32B-Instruct 成为目前 SOTA 的开源代码模型,代码能力追平 GPT-4o,展现出强大且全面的代码能力,同时具备良好的通用和数学能力。
- 多样:上个月我们开源了 1.5B、7B 两个尺寸,本次开源又带来 0.5B、3B、14B、32B 四个尺寸,截至目前, Qwen2.5-Coder 已经覆盖了主流的六个模型尺寸,以满足不同开发者的需要。
- 实用:通义团队探索了 Qwen2.5-Coder 在代码助手和 Artifacts 两种场景下的实用性,并用一些样例来展示 Qwen2.5-Coder 在实际场景中的应用潜力。
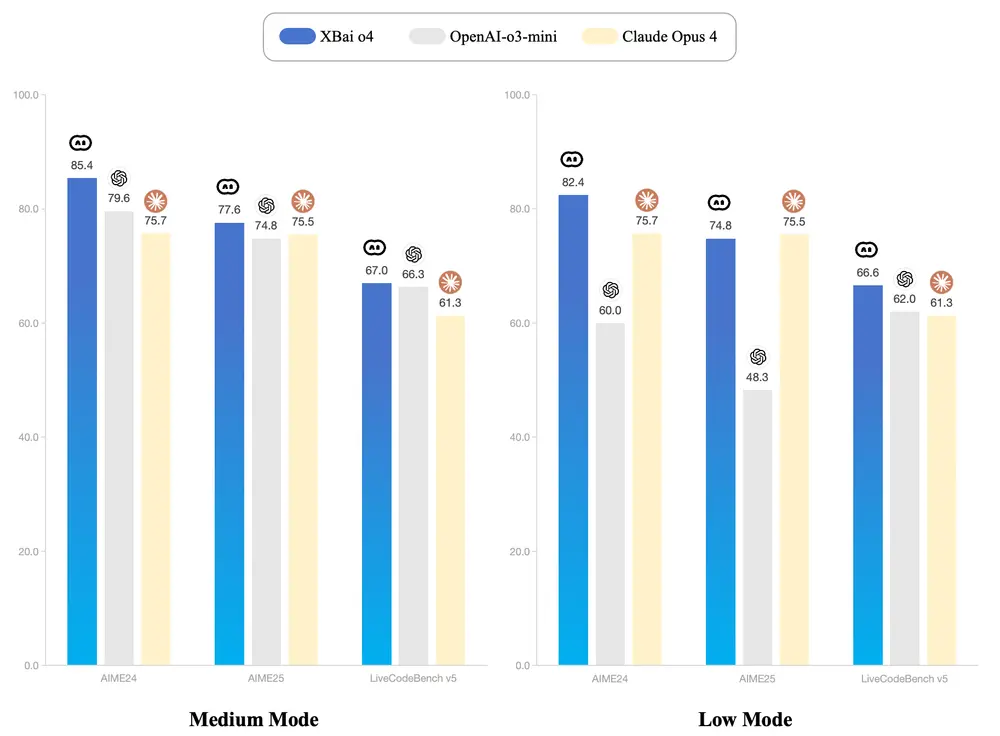
强大:代码能力达到开源模型 SOTA

- 代码生成:Qwen2.5-Coder-32B-Instruct 作为本次开源的旗舰模型,在多个流行的代码生成基准(如EvalPlus、LiveCodeBench、BigCodeBench)上都取得了开源模型中的最佳表现,并且达到和 GPT-4o 有竞争力的表现。
- 代码修复:代码修复是一个重要的编程能力。Qwen2.5-Coder-32B-Instruct 可以帮助用户修复代码中的错误,让编程更加高效。Aider 是流行的代码修复的基准,Qwen2.5-Coder-32B-Instruct 达到 73.7 分,在 Aider 上的表现与 GPT-4o 相当。
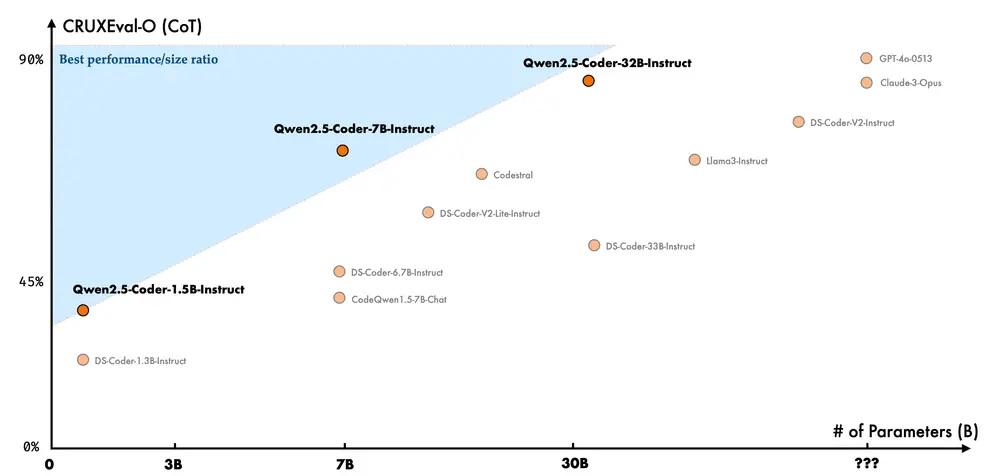
- 代码推理:代码推理是指模型能否学习代码执行的过程,准确地预测模型的输入与输出。上个月发布的 Qwen2.5-Coder-7B-Instruct 已经在代码推理能力上展现出了不俗的表现,32B 模型的表现更进一步。
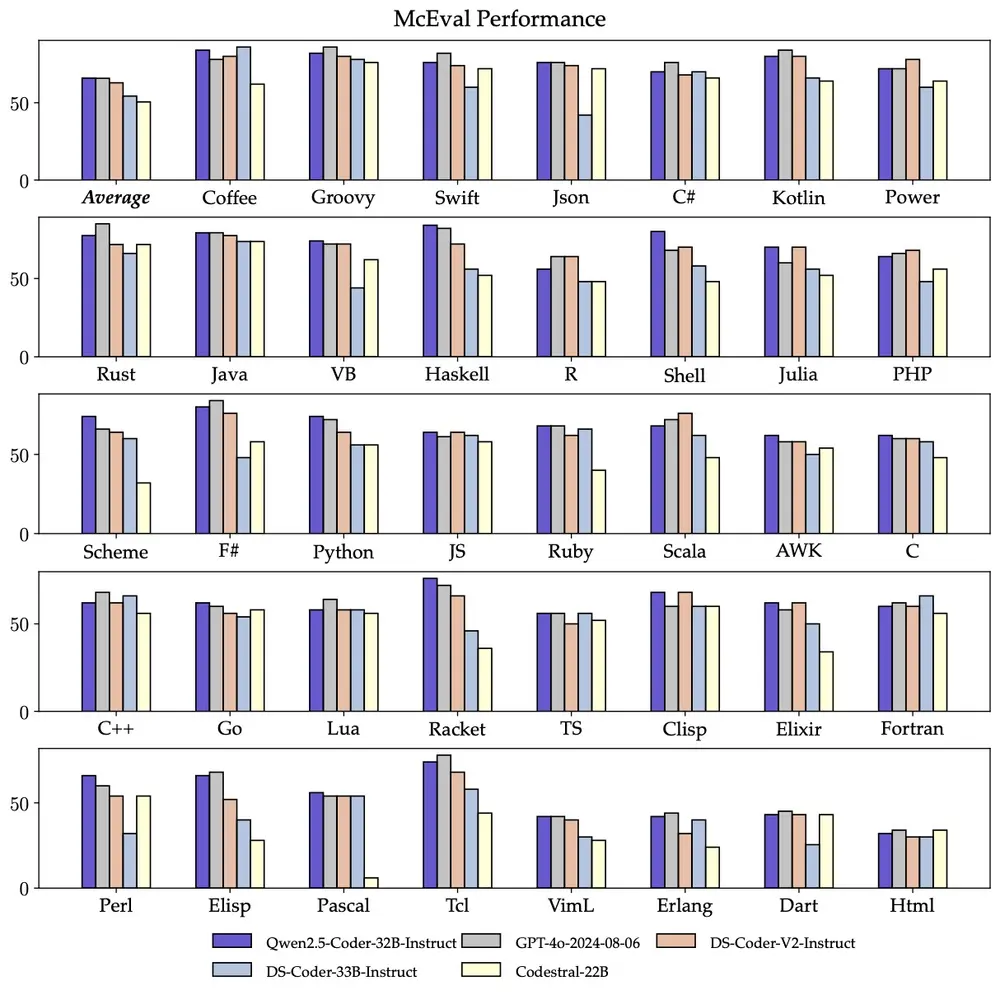
- 多编程语言:智能编程助手应该熟悉所有编程语言,Qwen2.5-Coder-32B-Instruct 在 40 多种编程语言上表现出色,在 McEval 上取得了 65.9 分,其中 Haskell、Racket 等语言表现令人印象深刻,这得益于我们在预训练阶段独特的数据清洗和配比。
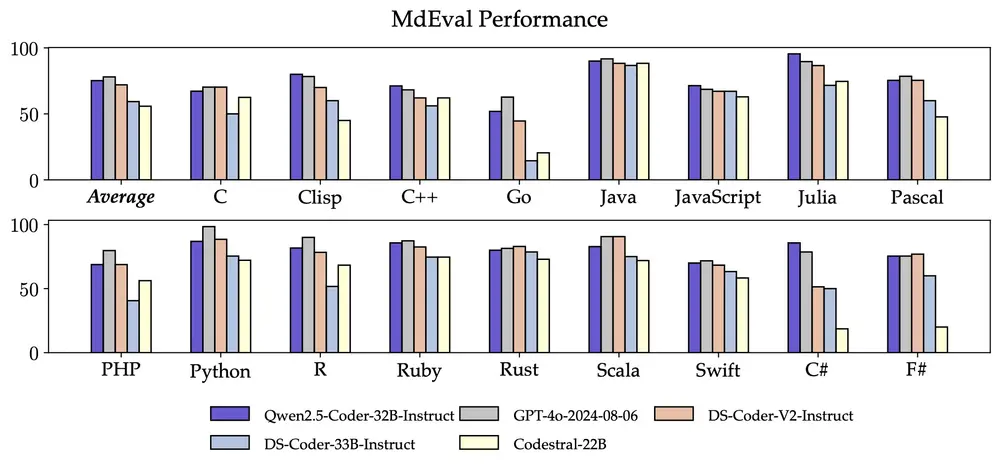
另外,Qwen2.5-Coder-32B-Instruct 的多编程语言代码修复能力同样令人惊喜,这将有助于用户理解和修改自己熟悉的编程语言,极大缓解陌生语言的学习成本。
与 McEval 类似,MdEval 是多编程语言的代码修复基准,Qwen2.5-Coder-32B-Instruct 在 MdEval 上取得了 75.2 分,在所有开源模型中排名第一。
- 人类偏好对齐:为了检验 Qwen2.5-Coder-32B-Instruct 在人类偏好上的对齐表现,我们构建了一个来自内部标注的代码偏好评估基准 Code Arena(类似 Arena Hard)。我们采用 GPT-4o 作为偏好对齐的评测模型,采用 “A vs. B win” 的评测方式——即在测试集实例中,模型 A 的分数超过模型 B 的百分比。下图结果表现出 Qwen2.5-Coder-32B-Instruct 在偏好对齐方面的优势。
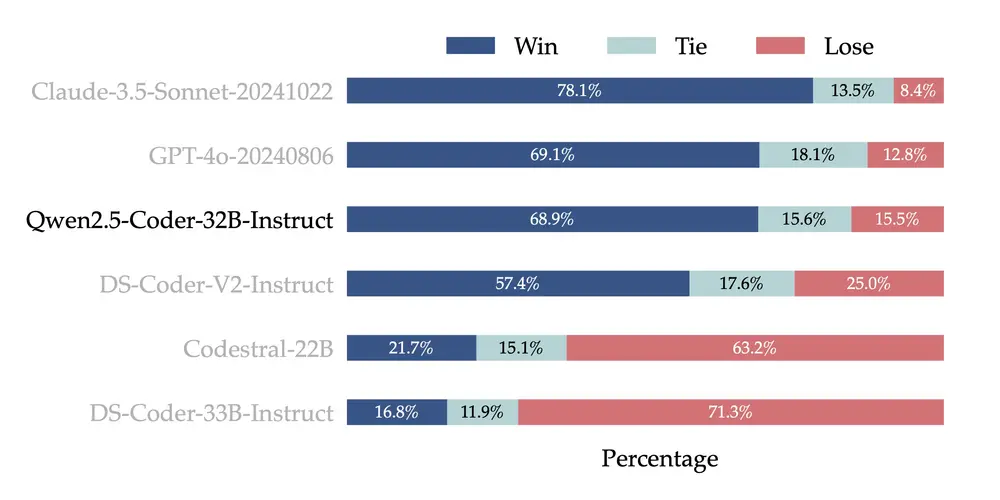
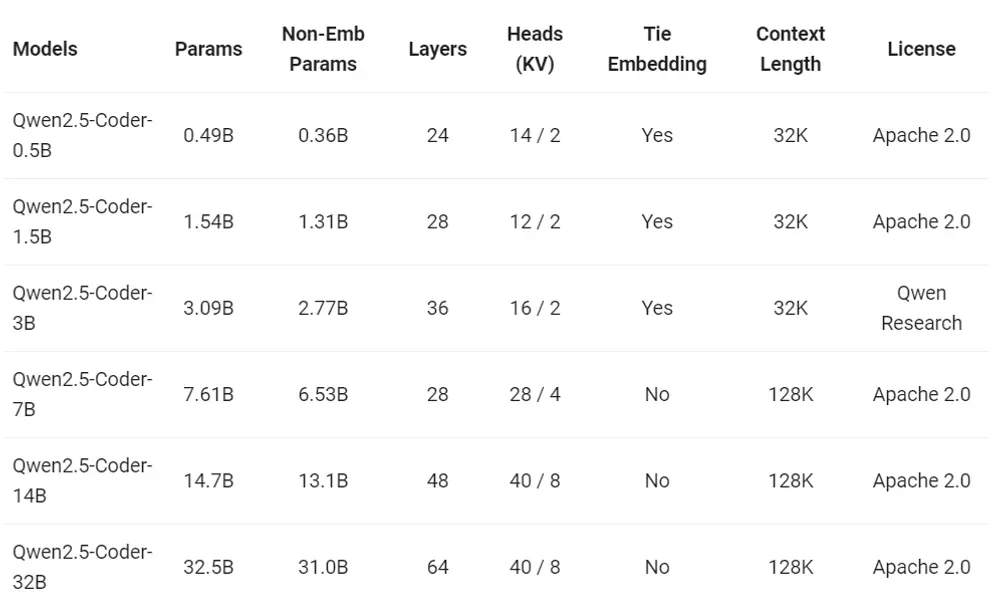
多样:丰富的模型尺寸
Qwen2.5-Coder 开源模型家族包含 0.5B、1.5B、3B、7B、14B、32B 六个尺寸,不仅能够满足开发者在不同资源场景下的需求,还能给研究社区提供良好的实验场。下表是详细的模型信息:
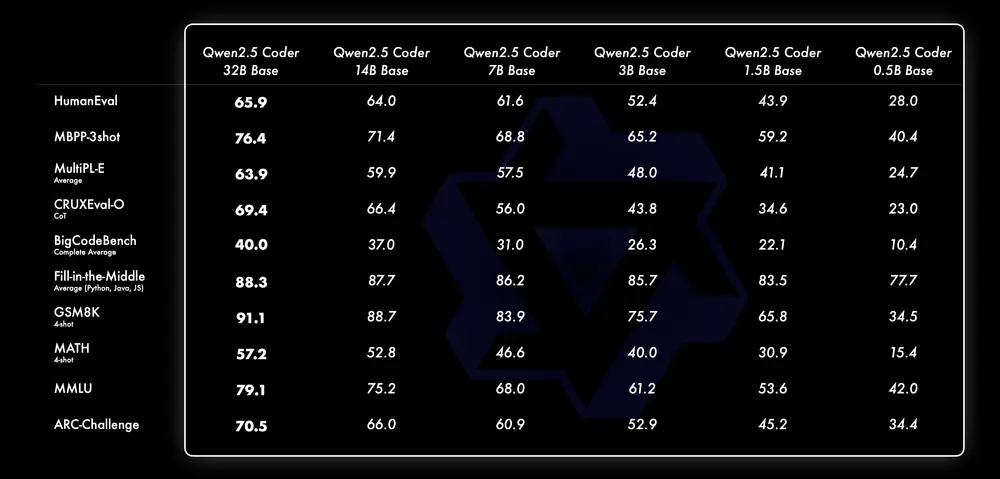
我们一直相信 Scaling Law 哲学。我们评估了不同尺寸的 Qwen2.5-Coder 模型在所有数据集上的表现,以验证 Scaling 在 Code LLMs 上的有效性。
对于每一个尺寸,我们都开源了 Base 和 Instruct 模型,其中, Base 模型可作为开发者微调模型的基座,Instruct 模型是可以直接聊天的官方对齐模型,
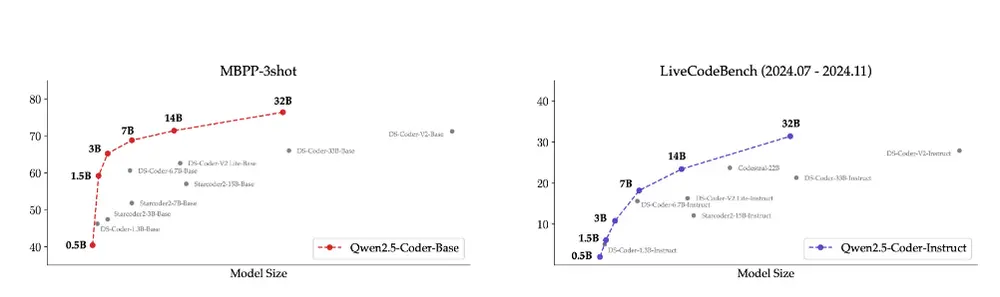
下面是不同尺寸 Base 模型的表现:
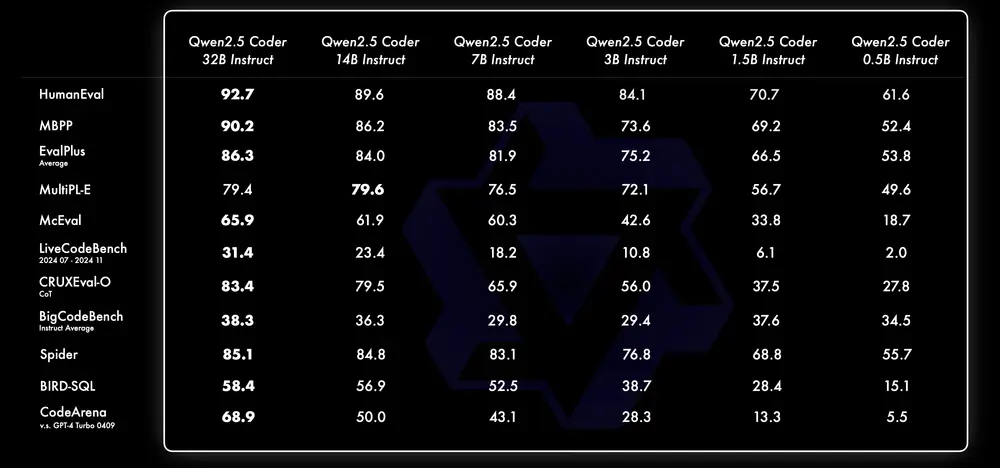
下面是不同尺寸 Instruct 模型的表现:
为了更加直观,我们展示了不同尺寸 Qwen2.5-Coder 模型和其他开源模型在核心数据集上的对比。
- 针对 Base 模型,我们选择 MBPP-3shot 作为评估指标,我们大量的实验表明,MBPP-3shot 更适合评估基础模型,且能够和模型的真实效果有较好的相关性。
- 针对 Instruct 模型,我们选择 LiveCodeBench 最近 4 个月(2024.07 - 2024.11)的题目作为评估,这些最新公布的、不可能泄露到训练集的题目能够反映模型的 OOD 能力。
模型尺寸和模型效果之间存在预期中的正相关关系,并且, Qwen2.5-Coder 在所有尺寸下都取得了 SOTA 表现,这鼓励我们继续探索更大尺寸的 Coder 模型。
实用:遇见 Cursor 和 Artifacts
实用的 Coder 一直是我们的愿景。为此,我们探索了 Qwen2.5-Coder 模型在代码助手和 Artifacts 场景下的实际应用。
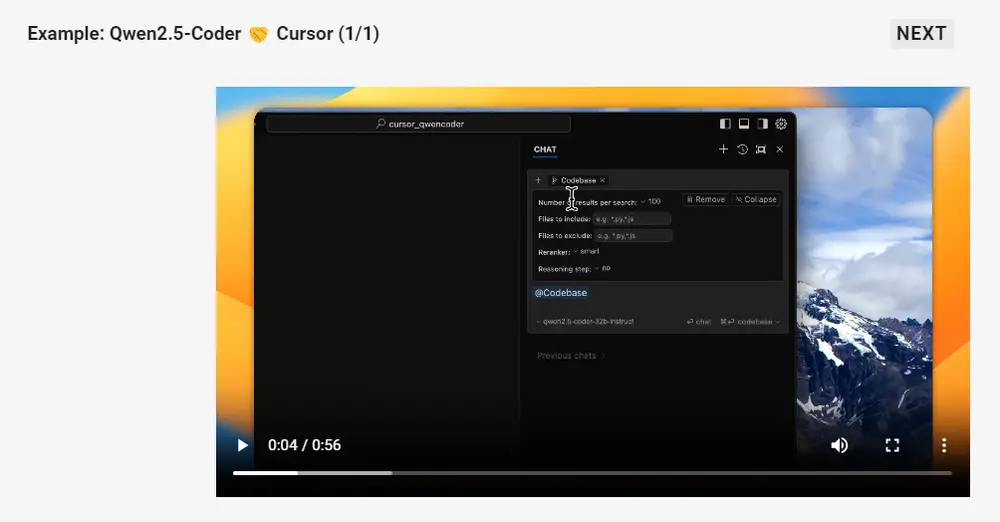
Qwen2.5-Coder 🤝 Cursor
智能代码助手已经得到广泛应用,但目前大多依赖闭源模型,我们希望 Qwen2.5-Coder 的出现能够为开发者提供一个友好且强大的选择。下面是 Qwen2.5-Coder 在 Cursor 场景下的一个例子。
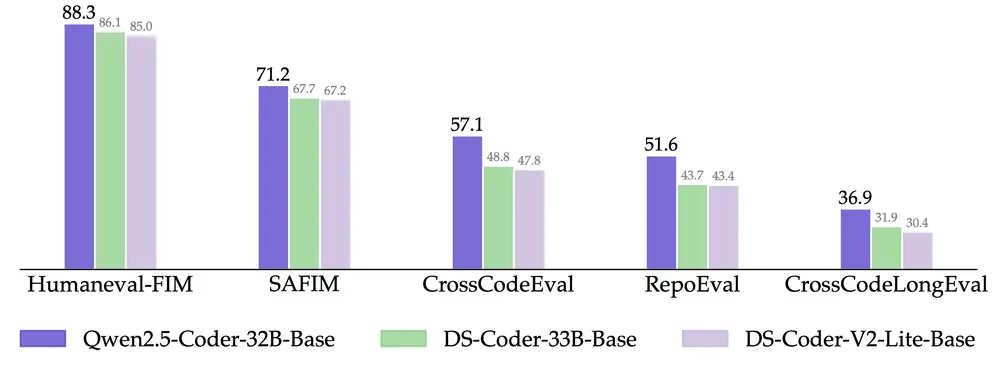
另外,Qwen2.5-Coder-32B 在预训练模型上就展现出强大的代码补全能力,在 Humaneval-Infilling、CrossCodeEval、CrossCodeLongEval、RepoEval、SAFIM 等 5 个评测集上都取得了 SOTA 表现。
为了保持公平对比,我们将最大序列长度控制在 8k,采用 Fill-in-the-Middle 模式进行测试。在 CrossCodeEval、CrossCodeLongEval、RepoEval、Humaneval-Infilling 4 个评测集中,我们评估了生成内容与真实标签是否绝对相等(Exact Match);在 SAFIM 中,我们采用 1 次执行成功率(Pass@1)进行评价。
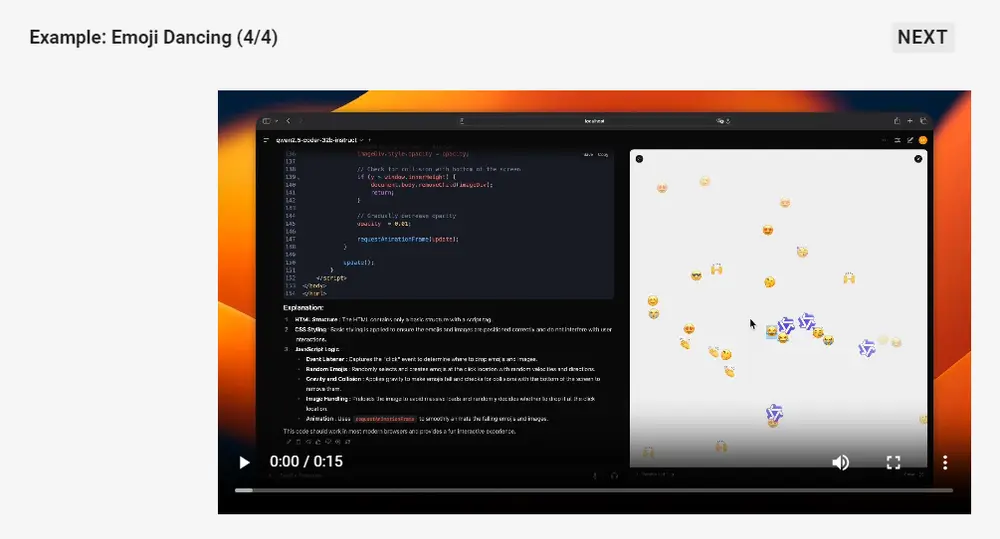
Qwen2.5-Coder 🤝 Artifacts
Artifacts 是代码生成的重要应用之一,能够帮助用户创作一些适合可视化的作品,我们选择 Open WebUI 探索 Qwen2.5-Coder 在 Artifacts 场景下的潜力,下面是一些具体的例子:
我们即将在通义官网 https://tongyi.aliyun.com 上线代码模式,支持一句话生成网站、小游戏和数据图表等各类可视化应用。欢迎大家体验!
模型许可
Qwen2.5-Coder 0.5B/1.5B/7B/14B/32B 模型均采用 Apache 2.0 许可证,3B模型使用 Research Only 许可。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











