
去年12月,微软推出了其Phi系列的最新成员——Phi-4,该模型在解决数学问题等方面展现了显著的进步。这些进步主要得益于训练数据质量的提升,特别是采用了高质量的合成数据集和人类生成的内容数据集。然而,当时Phi-4的访问权限非常有限,仅能在Azure AI Foundry开发平台上用于研究目的。
- 模型:https://huggingface.co/microsoft/phi-4
- Demo:https://huggingface.co/spaces/Tonic/Phi-4
- Ollama:https://ollama.com/library/phi4
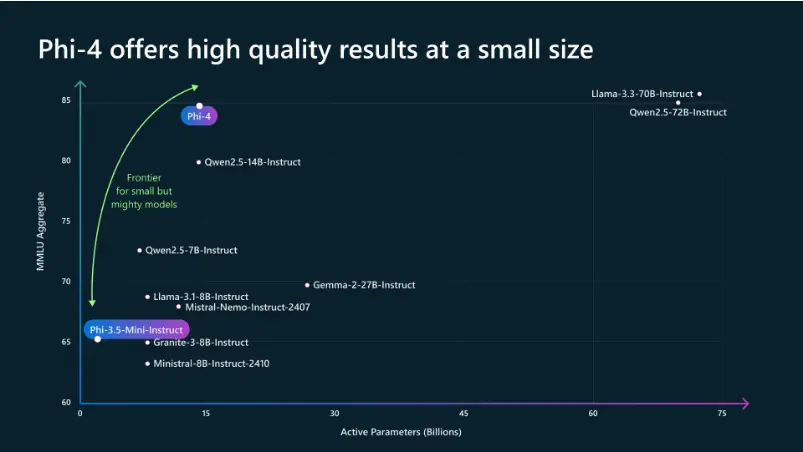
今天,微软正式开源了Phi-4,这是一款拥有140亿参数的先进开源模型。Phi-4基于合成数据集、过滤后的公共领域网站数据以及学术书籍和问答数据集构建而成,并经过严格的增强和对齐过程,包括监督微调(Supervised Fine-Tuning)和直接偏好优化(Direct Preference Optimization),确保了精确的指令遵循能力和强大的安全措施。
技术特性
- 上下文长度:支持高达16k tokens的上下文长度。
- 应用场景:特别适合内存/计算受限的环境、延迟敏感的场景以及需要推理与逻辑处理的任务。
竞争格局
Phi-4作为一款小型语言模型(约140亿参数),加入了与GPT-4 mini、Gemini 2.0 Flash和Claude 3.5 Haiku等同类产品的竞争行列。这些模型通常具有运行速度快、成本低的优势,且性能在过去几年中得到了稳步提升。
技术背后的思考
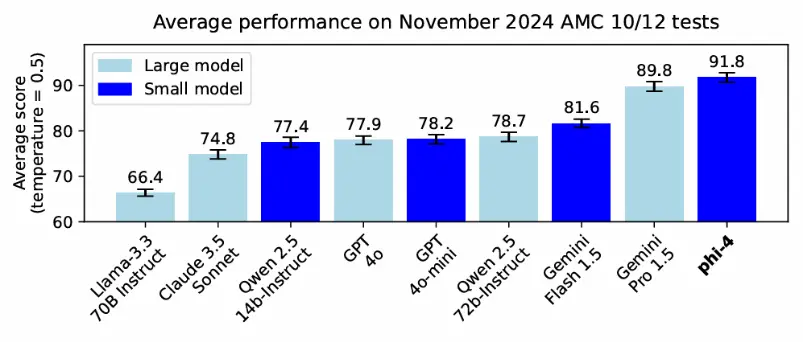
微软强调,Phi-4性能的提高不仅依赖于数据质量,还在于训练后的改进措施。当前,许多AI实验室都在探索如何通过合成数据和训练后优化来推进技术革新。Scale AI首席执行官Alexandr Wang也在社交媒体上表达了类似观点,认为行业已经触及到了预训练数据的极限,这一看法进一步印证了近期关于该领域的讨论。
关键人物变动
值得注意的是,Phi-4是Sébastien Bubeck离职后微软发布的首个Phi系列模型。Bubeck曾担任微软AI副总裁,在Phi模型的开发过程中扮演了重要角色。他于今年10月离开了微软,加入OpenAI继续从事AI研究工作。
主要用例
Phi-4旨在加速语言模型的研究,并作为生成式AI功能的基础模块。它适用于以下场景:
- 在资源有限的情况下高效运行。
- 在需要低延迟的应用中表现出色。
- 擅长处理涉及逻辑推理的任务,尤其是在英语环境中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











