
卡内基梅隆大学与英伟达联合推出了一项具有突破性的生成模型框架——Multiverse。这是全球首个开源的非自回归(Non-Autoregressive)并行推理框架,在保持与主流自回归模型(AR-LLM)相当性能的同时,实现了高达 2倍的推理加速。
- 项目主页:https://multiverse4fm.github.io
- GitHub:https://github.com/Infini-AI-Lab/Multiverse
- 模型:https://huggingface.co/Multiverse4FM
这一成果标志着大模型推理效率迈入了一个新阶段,尤其对实时交互和大规模部署场景具有重要意义。
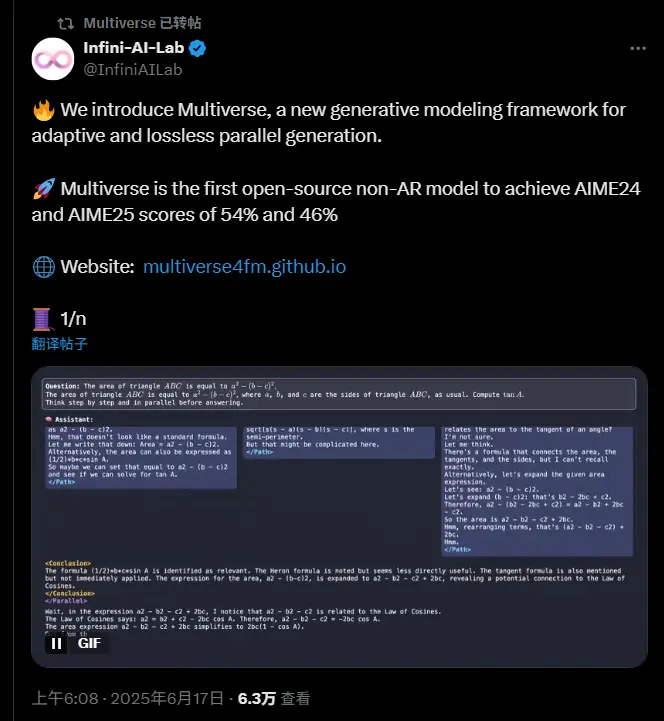
什么是 Multiverse?
Multiverse 的核心创新在于将经典的 MapReduce 范式引入生成模型架构中,并将其内化为三个关键阶段:
- Map(映射)阶段:自动将任务拆分为多个可独立处理的子任务;
- Process(处理)阶段:多个子任务在不同分支上并行执行;
- Reduce(归约)阶段:最终将各子任务结果无损合并为完整输出。
通过这种方式,Multiverse 实现了真正的原生并行生成能力,打破了传统自回归模型逐词生成的限制。
系统设计亮点
为了实现高效、实用的并行推理,Multiverse 围绕数据、算法和系统三方面进行了协同设计:
✅ Multiverse Curator
自动化 LLM 辅助流水线,将顺序链转换为 Multiverse 结构,支持从前沿 AR 模型快速迁移。
✅ Multiverse Attention
全新注意力机制,分离可并行分支,同时保证训练效率与生成质量。
✅ Multiverse Engine
高效生成引擎,支持动态切换顺序生成与并行生成模式,适配多种推理需求。
性能表现:媲美主流 AR 模型
在仅使用 1000个样本微调3小时 后,Multiverse-32B 成为目前唯一一个在同等规模下达到领先 AR 模型性能水平的开源非自回归模型。
测试数据显示:
- 在 AIME24 和 AIME25 基准测试中分别获得 53.8% 和 45.8% 的准确率;
- 相比自回归模型,在相同上下文长度下平均性能高出 1.87%;
- 在不同批量大小下均可实现高达 2倍的推理加速。
这表明,Multiverse 不仅具备强大的推理能力,还展现出极高的扩展性和数据效率。
工作原理详解
Multiverse 的运行流程如下:
- Map 阶段:输入复杂任务后,模型自动将其分解为多个子任务,并为每个子任务生成前缀序列;
- Process 阶段:各个子任务在独立分支上并行执行,互不干扰;
- Reduce 阶段:完成所有子任务后,模型以无损方式合并输出,确保最终结果连贯准确;
- 控制标签:如
<Parallel>和<Path>标签用于界定 MapReduce 块边界,协调各阶段执行逻辑。
这种结构特别适用于数学推导、多步推理等需要高并发处理的任务。
主要优势总结
| 特性 | 描述 |
|---|---|
| 并行生成 | 将任务拆解为多个子任务并行处理,显著缩短生成时间 |
| 无损合并 | 多路结果融合保持语义一致性和完整性 |
| 自适应任务拆分 | 动态决定任务分解策略,提升并行效率 |
| 高效训练与推理 | 新型注意力机制 + 引擎优化,兼顾性能与速度 |
开源与未来展望
Multiverse 是一个完全开源的项目,包含完整的模型代码、训练数据及推理工具,便于研究人员和开发者复现与扩展。
研究团队表示,未来将进一步探索其在更复杂任务中的应用,包括长文本生成、多模态推理以及跨语言理解等方向。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











