
快手 Kwaipilot 团队正式开源了其最新研究成果——KwaiCoder-AutoThink-preview 自动思考大模型。该模型针对当前深度思考类大模型中普遍存在的“过度思考”问题,提出了一种全新的训练范式,并引入了一种基于传统强化学习(GRPO)的改进方法 Step-SRPO,以提升模型在复杂任务中的表现。
模型亮点:自动切换“深思”与“直觉”
KwaiCoder-AutoThink-preview 的核心创新在于它融合了“思考”与“非思考”两种能力,能够在不同任务之间智能切换推理方式,类似于人类面对问题时选择“深入分析”或“快速判断”。
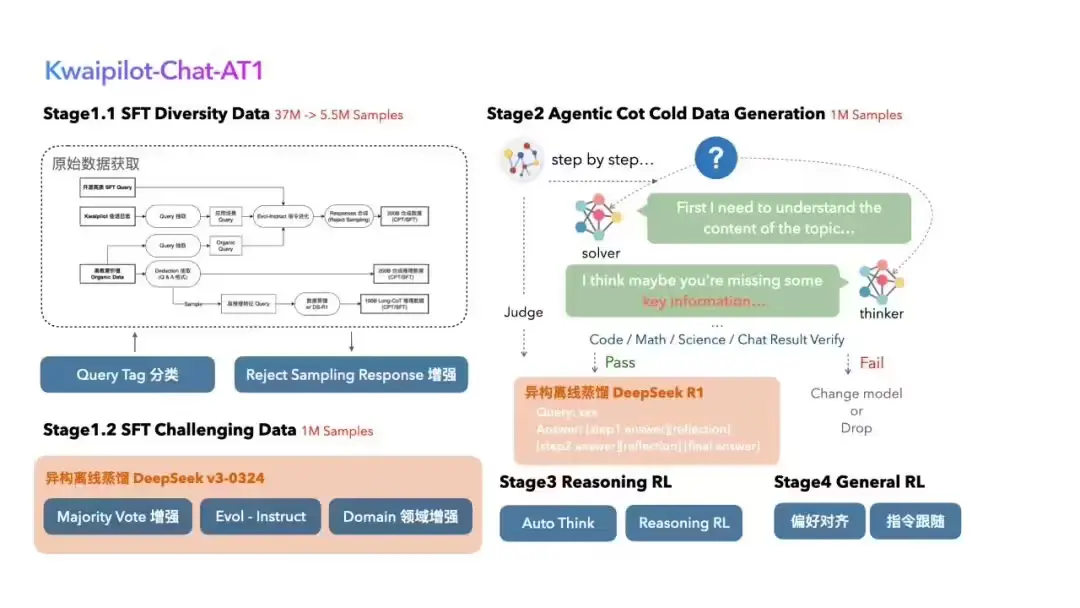
官方称其为“DeepSeek-V3 & R1 合体”,这意味着它结合了深度链式推理和直接输出的能力。通过这种自动切换机制,模型不仅提升了处理复杂任务的准确性,还有效避免了在简单任务中不必要的计算开销。
性能提升:代码与数学任务显著增强
在多个评测榜单上,KwaiCoder-AutoThink-preview 表现出色:
- 在部分代码和数学任务中,开启自动思考模式后,模型得分提升高达 20 分左右;
- 即使在未启用思考模式的情况下,由于推理形态的优化,模型性能也有小幅提升。
这表明,无论任务是否需要深度思考,该模型都能保持良好的适应性和稳定性。
技术演进:从 Step-SRPO 到工具集成
为了进一步提升模型的复杂任务处理能力,团队基于 GRPO 强化学习框架,提出了带有过程监督的 Step-SRPO 方法。这一方法通过监督每一步推理过程,引导模型生成更加合理、高效的思考路径。

此外,快手技术团队表示,未来将在 preview 版本的基础上持续优化,重点提升模型的推理能力和工具调用能力。所有技术细节与训练方法也将逐步开源,供社区研究和复现。
开源地址
目前,KwaiCoder-AutoThink-preview 已在 Hugging Face 和 ModelScope 等平台上线,开发者可自由下载和使用。
未来,Kwaipilot 团队将继续探索自动思考模型的边界,推动其在实际工程场景中的落地应用,同时也将持续开放更多技术和模型资源,助力大模型生态的发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











