
Meta 正式发布 MobileLLM-R1 系列模型,包含 140M、360M 和 950M 三款尺寸,专为数学、编程(Python/C++)和科学推理任务设计。它不是通用聊天模型,而是一个经过精细训练的“专项选手”,目标明确:在有限资源下实现高性能。
最令人关注的是:MobileLLM-R1-950M 仅用不到 5 万亿 token 训练完成,在多个基准上表现媲美甚至超越更大规模的开源模型。这标志着一种新趋势:效率优先的模型研发范式正在崛起。
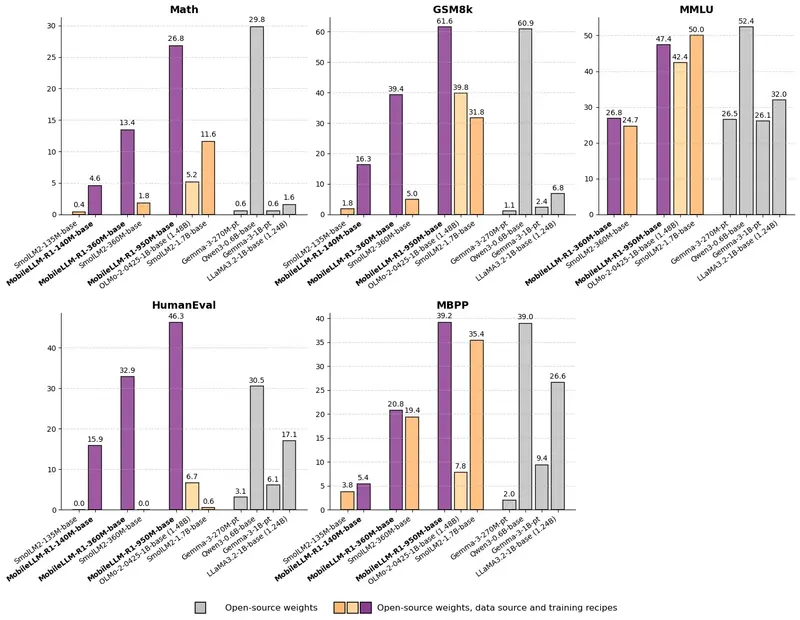
性能惊艳:以少胜多的典型代表
尽管参数量仅为 9.49 亿,MobileLLM-R1-950M 在关键任务上的表现却毫不逊色:
| 基准测试 | 表现 |
|---|---|
| MATH | 准确率显著优于 Olmo 1.24B(约高 5 倍),是 SmolLM2 1.7B 的 2 倍以上 |
| GSM8K | 与 Qwen3-0.6B 相当,后者使用了 36 万亿 token 预训练 |
| LiveCodeBench | 编码能力大幅领先 Olmo 和 SmolLM2 同类模型 |
这意味着:
- 更小的模型可以胜任复杂推理;
- 更少的数据也能达到先进水平;
- 边缘设备部署成为可能。
尤其值得注意的是,该模型总训练 token 不足 5T(其中预训练仅 2T),远低于主流模型动辄数十万亿的训练量,展现出极高的 token 利用效率。
架构设计:紧凑但高效
MobileLLM-R1 系列采用标准解码器架构,针对移动端和低资源场景进行了精简设计:
模型参数概览
| 模型 | 层数 | 注意力头数 | KV 头数 | 隐藏维度 | 参数量 |
|---|---|---|---|---|---|
| MobileLLM-R1-140M | 15 | 9 | 3 | 2048 | 140M |
| MobileLLM-R1-360M | 15 | 16 | 4 | 4096 | 359M |
| MobileLLM-R1-950M | 22 | 24 | 6 | 6144 | 949M |
统一特性:
- 输入/输出模态:纯文本
- 上下文长度:基础模型 4k,最终模型提升至 32k
- 词表大小:128k
- 使用共享嵌入层,减少内存占用
这种设计平衡了表达能力和计算开销,特别适合在手机、嵌入式设备等受限环境中运行。
训练策略:三阶段递进,层层提效
MobileLLM-R1 并非简单地“训得久”,而是通过精心设计的三阶段流程,逐步注入能力:
✅ 第一阶段:预训练(Pre-training)
- 数据总量:4T token(分两阶段各 2T)
- 优化器:Adam (β₁=0.9, β₂=0.95, ε=1e-8)
- 学习率:4e-3,2k 步预热后线性衰减
- 批大小:16 × 2k 序列
- 耗时:约 4–5 天(每阶段)
数据混合强调教育类语料(FineWeb-Edu 占比超 50%)、数学(OpenWebMath、FineMath)和代码(StarCoder),奠定扎实基础。
✅ 第二阶段:中训练(Mid-training) + 知识蒸馏
- 引入高质量推理数据集(如 GSM8K、Math、Dolmino)
- 使用 Llama-3.1-8B-Instruct 作为教师模型
- 通过 KL 散度最小化进行知识蒸馏,将大模型的推理能力迁移到小模型
这一阶段让模型从“理解语言”迈向“学会思考”。
✅ 第三阶段:后训练(Post-training) + SFT
分为两个子阶段:
- 通用监督微调(SFT)
- 数据:Tulu-3-sft-olmo 混合数据集(866K 样本)
- 目标:建立基本指令遵循能力
- 推理专项 SFT
- 数据:OpenMathReasoning(3.2M)、OpenScienceReasoning-2(803K)、OpenCodeReasoning-2(2.16M)
- 序列长度:32k
- 目标:强化数学推导、科学分析和编程逻辑
整个训练过程透明且可复现,Meta 同步公开了完整配方与数据来源。
为什么 MobileLLM-R1 如此高效?
1. 数据质量 > 数据数量
相比盲目扩大数据规模,MobileLLM-R1 更注重数据的相关性和质量:
- 大量使用 FineWeb-Edu、Arxiv、OpenWebMath 等高质量学术与教育语料;
- 推理阶段聚焦真实问题求解样本;
- 避免噪声数据稀释模型能力。
2. 分阶段训练,目标清晰
每一阶段都有明确目标:
- 预训练 → 学语言
- 中训练 → 学思维(借助蒸馏)
- 后训练 → 学应用(专项强化)
避免了“一步到位”带来的学习冲突。
3. 知识蒸馏加持
利用强大的教师模型(Llama-3.1-8B)引导训练,相当于给学生请了一位名师,加速能力收敛。
4. 高效上下文扩展
最终模型支持 32k 上下文长度,远超基础版的 4k,适用于长文档理解和复杂推理链构建。
定位明确:不是聊天助手,而是“专业工具”
需要强调的是:MobileLLM-R1 不是通用对话模型。
它的训练目标集中在三大领域:
- 📐 数学问题求解(MATH、GSM8K)
- 🔬 科学推理(OpenScienceReasoning)
- 💻 编程任务(LiveCodeBench、OpenCodeReasoning)
因此,它不适合闲聊或内容创作,但在 STEM 类任务中表现出色,特别适合作为:
- 手机端智能辅导工具
- 离线编程助手
- 教育类 AI 应用底层引擎
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











