
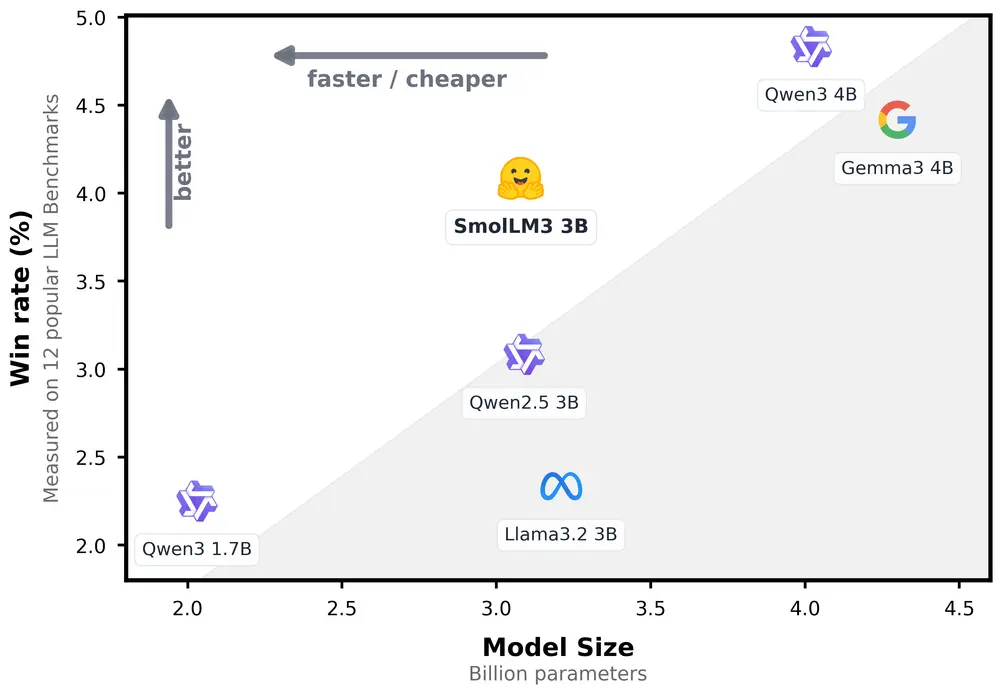
随着边缘计算和本地部署需求的增长,小型语言模型(Small Language Model, SLM) 正在成为新一代 AI 应用的关键组成部分。近日,Hugging Face 推出了其最新力作 —— SmolLM3,一款仅 3B 参数的高性能开源模型,在多项指标上超越同级别模型,甚至逼近部分 4B 模型的表现。
- 模型:https://huggingface.co/HuggingFaceTB/SmolLM3-3B-Base
- 模型:https://huggingface.co/HuggingFaceTB/SmolLM3-3B
更令人振奋的是,SmolLM3 不仅性能出色,还完全开源,并附带了完整的训练方法文档,为社区提供了从架构设计到训练策略的完整蓝图。
SmolLM3 的核心特性
| 特性 | 描述 |
|---|---|
| 模型规模 | 3B 参数,高效轻量,适合资源受限环境 |
| 多语言支持 | 英语、法语、西班牙语、德语、意大利语、葡萄牙语 |
| 长上下文能力 | 支持高达 128k tokens(通过 YaRN 外推) |
| 双模式输出 | 可切换“推理模式”与“非推理模式” |
| 开源许可 | 完全公开模型权重、训练配置、数据混合与评估脚本 |
这使其不仅适用于本地推理设备,也适合构建复杂任务导向的 AI 工具链。
架构优化亮点
SmolLM3 在 Llama 架构基础上进行了多项改进,以提升效率与上下文处理能力:
- 分组查询注意力(GQA)
使用 4 组查询注意力机制,减少 KV 缓存大小,同时保持多头注意力的性能优势。 - NoPE 技术
根据《RoPE to NoRoPE and Back Again》论文实现 NoPE 方法,选择性移除旋转位置嵌入,有效提升长序列建模能力。 - 文档内掩码机制
防止同一训练批次中不同文档之间相互关注,提升长文本训练稳定性。 - 训练稳定性增强
移除了嵌入层的权重衰减,使训练过程更稳定,模型收敛更快。
这些改进均通过 3B 规模上的消融实验验证,确保每一项改动都能带来实际性能提升。

训练阶段详解
SmolLM3 采用三阶段预训练策略,在 11.2T 令牌 数据上完成训练:
✅ 第一阶段(0T → 8T):打基础
- 网络数据:85%(含 12% 多语言)
- 代码数据:12%
- 数学数据:3%
使用 FineWeb-Edu、DCLM、The Stack v2 等高质量数据集,奠定通用理解能力。
✅ 第二阶段(8T → 10T):强化数学与代码
- 网络:75%
- 代码:15%
- 数学:10%
引入 Stack-Edu 和 MegaMath 数据集,进一步提升逻辑与编码能力。
✅ 第三阶段(10T → 11.1T):深化推理
- 网络:63%
- 代码:24%
- 数学:13%
重点加入 OpenMathReasoning、Pro 合成重写等推理数据集,提升模型在多轮对话中的表现。
所有训练细节、数据配比、日志和中间检查点均已公开,供开发者复现实验或用于下游任务微调。
性能评估结果亮眼
在多个主流基准测试中,SmolLM3 表现优异:
| 基准 | SmolLM3 表现 |
|---|---|
| HellaSwag | 超过 Llama-3.2-3B 和 Qwen2.5-3B |
| MMLU Pro CF | 与 Qwen3-4B 相当 |
| GSM8K / MATH | 在数学推理方面接近 Gemma3 |
| RULER 64k | 展示出强大的长上下文适应能力 |
| LiveCodeBench | 在编程任务中大幅优于其他 3B 模型 |
最终模型在 3B 尺寸上达到最先进水平,并具备与 4B 模型竞争的能力。
中训练:扩展长上下文与推理能力
主预训练完成后,SmolLM3 进入“中训练”阶段,专门优化两个关键维度:
📐 长上下文扩展(4k → 64k)
- 分两阶段逐步增加 RoPE theta 至 5M
- 每阶段训练 50B 令牌
- 最终结合 YaRN 技术 实现 128k token 的推理长度
无需额外采样特定长文档数据,仅通过训练动态调整即可获得优秀表现。
🤖 推理能力增强
- 使用 OpenThoughts3 和 Nemotron 合成推理轨迹训练
- 通过 ChatML 模板支持推理与非推理模式切换
- 引入 wrapped packing,避免过多结构化输入干扰学习
这一阶段共处理 140B 令牌,显著增强了模型的多轮对话理解和推理流程组织能力。
双模式交互:用户可控制是否启用推理
SmolLM3 提供了一种独特的聊天模板机制,允许用户通过指令控制输出模式:
/think:进入推理模式,输出包含详细思考路径/no_think:进入非推理模式,直接给出答案
这种设计使得 SmolLM3 既能胜任日常问答,也能应对复杂逻辑推理任务。
此外,它还支持工具调用,并通过 XML 和 Python 工具分类优化模型对工具描述的理解。
监督微调(SFT)与模型对齐
为了更好地融合推理与非推理能力,团队采用了合成数据生成 + APO 对齐策略:
- 使用 Qwen3-32B 在非推理数据上生成推理轨迹
- 构建包含 1.8B 令牌的 SFT 数据集
- 使用 BFD 打包策略,训练 4 个 epoch
最后,使用 Anchored Preference Optimization(APO) 进行模型对齐,这是一种 DPO 的改进变体,优化目标更稳定,效果更优。
模型合并技术恢复长上下文性能
在 APO 对齐后,团队发现模型在长文本任务(如 RULER)上有轻微下降。为此,他们采用 MergeKit 进行模型融合:
- 将 APO 检查点与长上下文版本进行线性合并(比例 0.9:0.1)
- 成功恢复长文本性能至原始水平
这种方法让 SmolLM3 在不牺牲速度的前提下,维持了广泛的适用性。
评估结果:全面领先
🧾 基础模型表现
在知识、推理、数学、编程等多个领域,SmolLM3 均表现出色:
- 在 ARC、HellaSwag、BoolQ 等常识推理任务中位列前三
- 数学推理(GSM8K、MATH)表现强劲
- 编程能力(HumanEval+、MBPP+)媲美主流 3B 模型
- 长文本处理能力超过多数 4B 模型
🧮 指令模型表现
在开启指令模式后,SmolLM3 的推理能力进一步释放:
| 任务 | 推理模式提升 |
|---|---|
| AIME 2025 数学题 | 从 9.3% 提升至 36.7% |
| LiveCodeBench 编程挑战 | 从 15.2% 提升至 30.0% |
| GPQA Diamond 高级推理 | 从 35.7% 提升至 41.7% |
这意味着,SmolLM3 不仅是小巧高效的模型,更是能在复杂任务中展现潜力的“智能引擎”。
开源与社区友好
SmolLM3 的一大亮点是其透明度与可复现性:
- 公开所有训练配置文件与数据混合比例
- 提供训练日志、中间检查点与最终模型
- 发布完整的监督微调与偏好对齐流程说明
- 提供详细的模型合并策略与评估脚本
这为研究者和工程师提供了一个极佳的起点,可用于:
- 自研小型模型训练
- 探索推理模式下的行为差异
- 构建低延迟、高精度的本地 AI 解决方案
适用人群
| 用户类型 | 价值 |
|---|---|
| AI 研究者 | 提供完整的训练流程与模型设计思路 |
| 工程团队 | 支持本地部署、低延迟推理、多语言支持 |
| 教育工作者 | 用于教学、演示推理与非推理模式差异 |
| 开发者 | 可轻松集成到应用中,构建推理辅助工具 |
| AI 创业公司 | 在有限资源下实现强大功能覆盖 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











