
Comfy-WaveSpeed 是一个专为 ComfyUI 设计的全能推理优化解决方案,旨在提供通用、灵活且高效的模型加速能力。以下是其主要特性和使用指南。
动态缓存(首块缓存)
Comfy-WaveSpeed 引入了 首块缓存(First Block Cache, FBCache) 技术,该技术基于 TeaCache 和其他去噪缓存算法发展而来。FBCache 利用 Transformer 模型中第一个块的残差输出作为缓存指标,当当前与上一个首块残差输出之间的差异足够小时,可以复用之前的最终残差输出,从而跳过后续所有 Transformer 块的计算。这种方法可以在不影响精度的前提下显著减少计算量,实现高达 2 倍的性能提升。
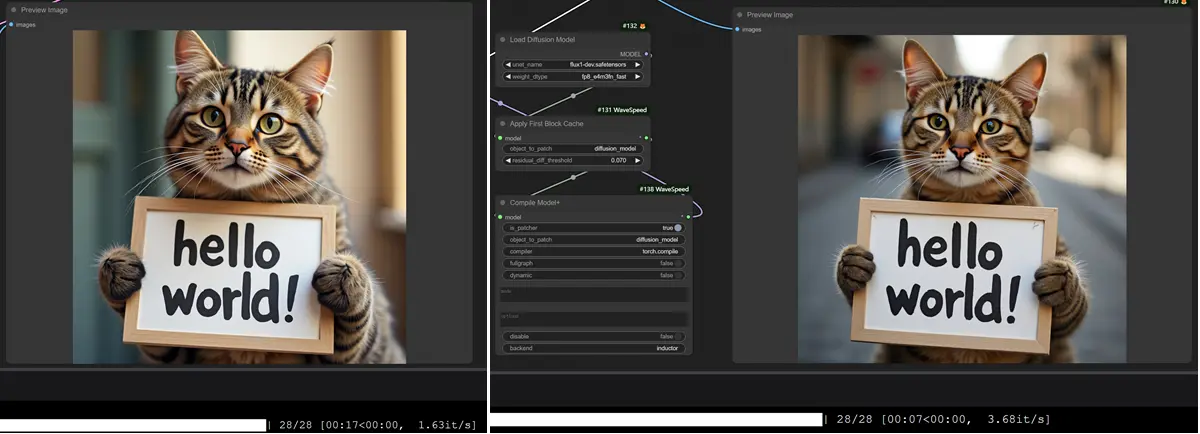
- 应用方法:在工作流中的 Load Diffusion Model 节点之后添加 wavespeed->Apply First Block Cache 节点,并根据具体使用的模型调整
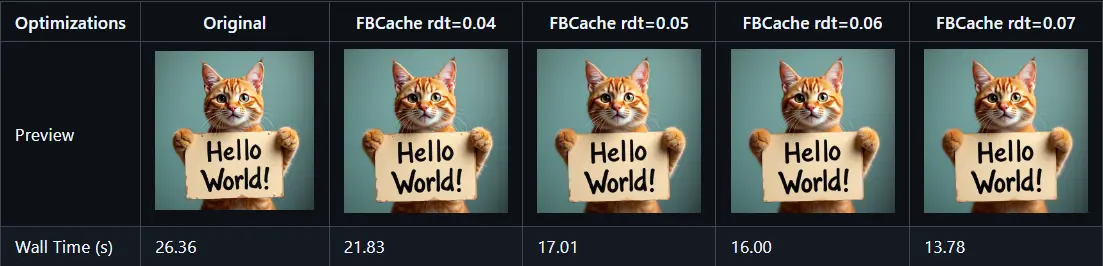
residual_diff_threashold参数。例如,在使用flux-dev.safetensors模型时,可设置此值为0.07,以达到 1.5 至 3.0 倍的速度提升。 - 支持模型:包括但不限于 FLUX、LTXV 和 HunyuanVideo(原生)
首块缓存的工作原理
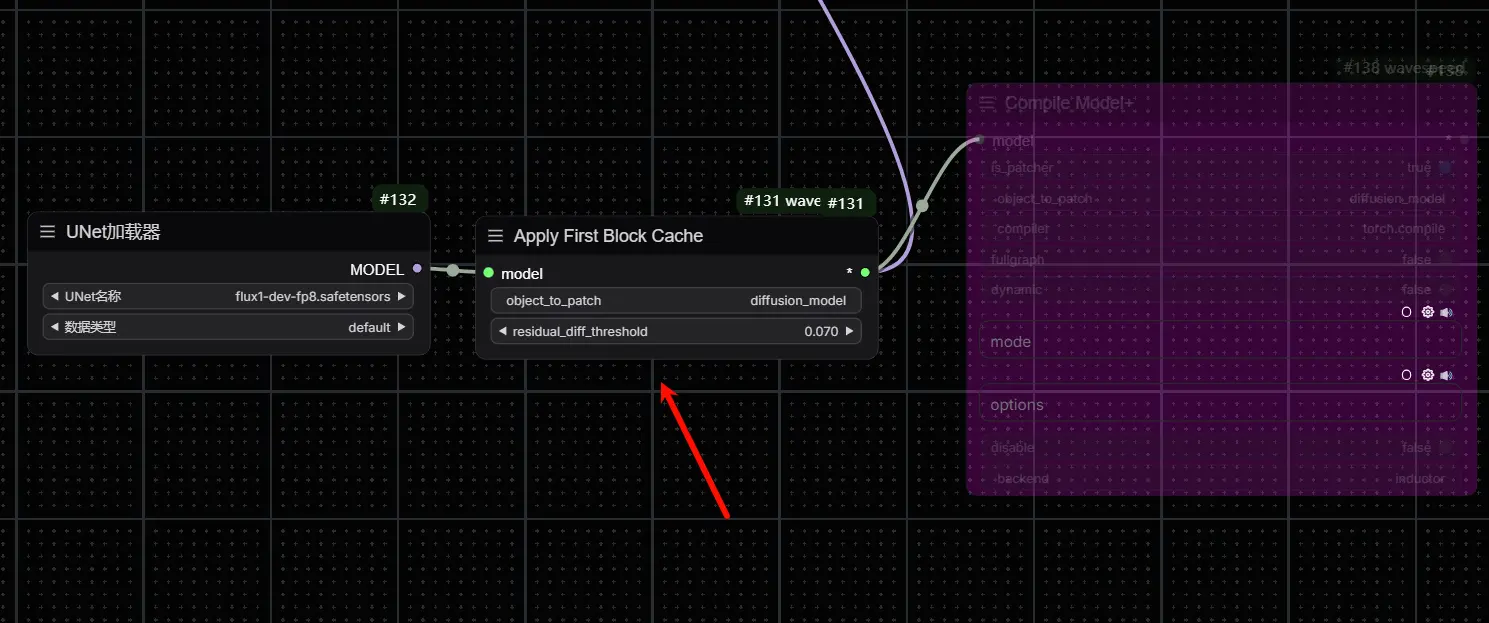
首块缓存利用了这样一个观察:如果当前推理步骤与之前步骤的第一个 Transformer 块输出的残差差异足够小,那么我们可以安全地假设后续的模型输出也会相似。因此,可以跳过中间的去噪步骤,直接复用之前的缓存结果,从而节省了大量的计算资源。这种方法不仅简单而且高效,不需要像 TeaCache 那样复杂的重新缩放策略就能保证缓存的准确性。实验表明,在 FLUX.1-dev 推理过程中,这种方法可以实现高达 1.5 倍的加速,并且几乎不会影响生成图像的质量。
增强版 torch.compile
为了进一步提高模型的执行效率,Comfy-WaveSpeed 提供了增强版的 torch.compile 功能。通过编译模型,可以优化运行时性能,尽管首次编译过程较为耗时,但之后的运行将受益于缓存,获得更快的速度。
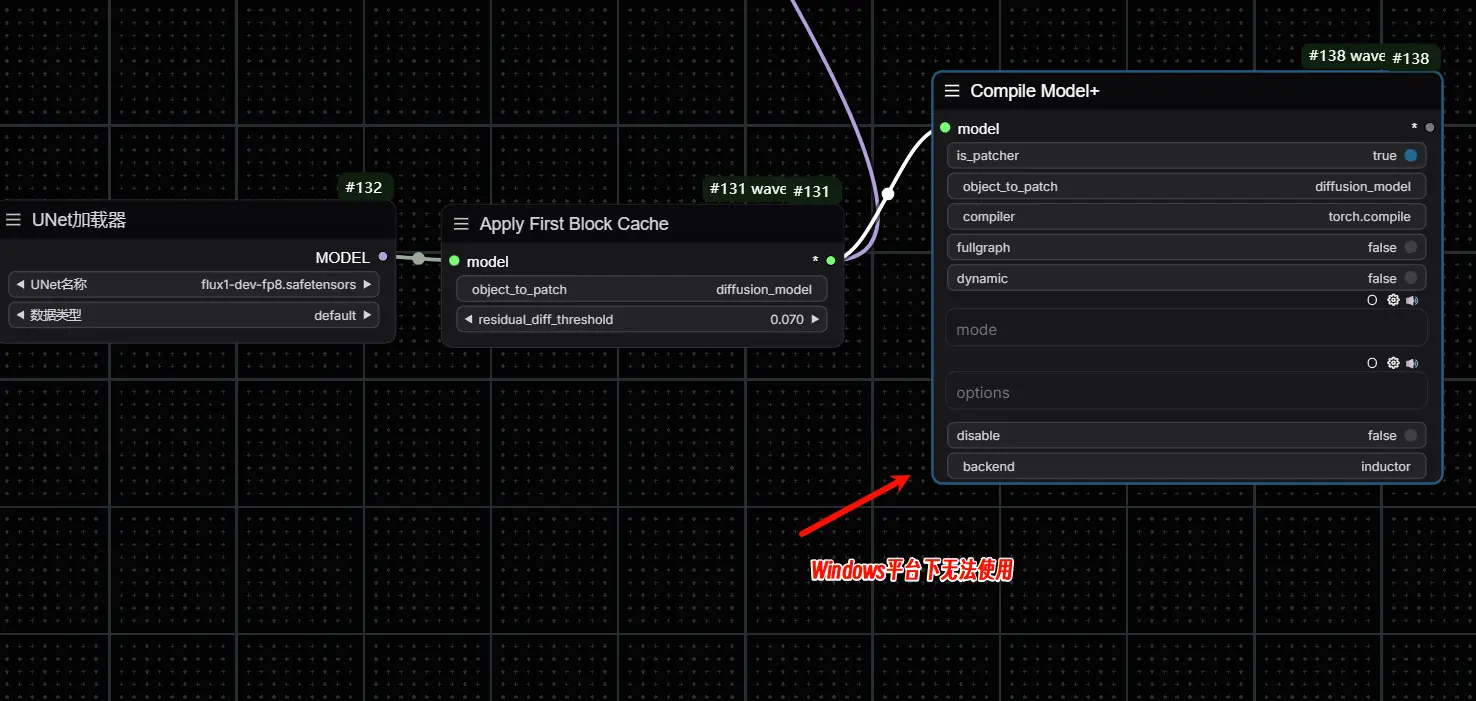
- 应用方法:在工作流中的 Load Diffusion Model 或 Apply First Block Cache 节点后加入 wavespeed->Compile Model+ 节点。你可以选择不同的
mode参数来优化编译效果,如max-autotune或max-autotune-no-cudagraphs。 注意事项:由于
torch.compile可能与模型卸载不兼容,建议在启动 ComfyUI 时添加--gpu-only参数以禁用模型卸载功能。torch.compile目前未在 Windows 上得到官方支持,因此可能会出现兼容性问题。建议在Windows平台使用的适合不要添加此节点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











