在复杂任务中,如网页购物、虚拟环境导航或深度信息检索,大语言模型(LLM)作为智能体的表现正日益受到关注。然而,一个长期困扰研究者的难题是:这些任务往往只在最终成功或失败时给出奖励信号——中间成百上千步的行为得不到反馈。
这种“稀疏奖励”问题导致标准强化学习算法难以有效分配信用(credit assignment),使得训练效率低下,甚至出现策略崩溃。
近期,来自字节跳动、中国科学技术大学、复旦大学与中国科学院自动化研究所的联合团队提出了一种全新的强化学习框架 —— EMPG(Entropy-Modulated Policy Gradient),从学习信号本身入手,重新校准每一步的更新强度,显著提升了 LLM 智能体在长时域任务中的性能与稳定性。
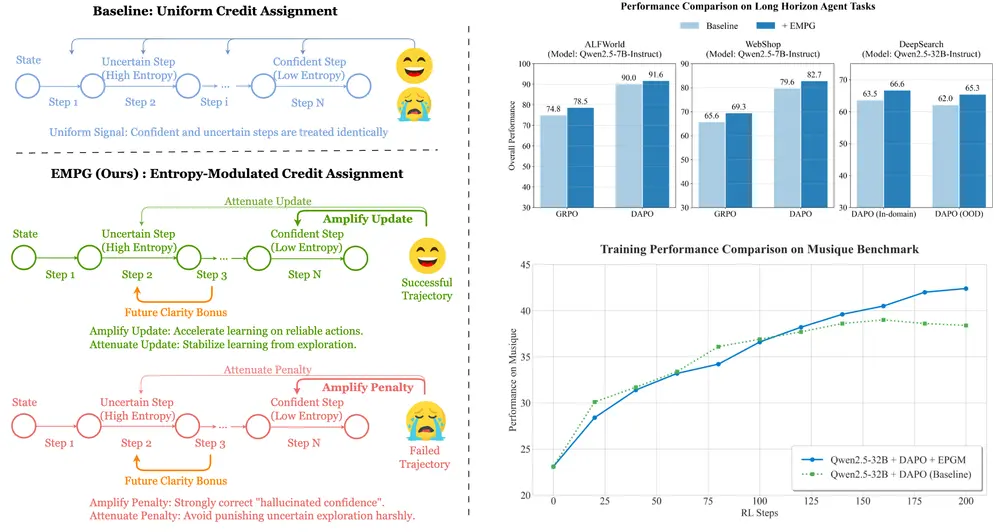
问题本质:为什么“自信”反而学得慢?
在传统策略梯度方法(如 PPO、GRPO)中,存在一个被忽视的根本性耦合现象:
策略梯度的更新幅度与其输出熵天然负相关。
这意味着:
- 当模型高度自信且正确时(低熵),其梯度反而较小 → 应该强化的动作没有得到充分更新;
- 当模型犹豫不决或随机探索时(高熵),梯度较大 → 噪声动作被过度调整,引发训练震荡。
这就像学生做题:答对了却因“太确定”而不加分,错得果断反而扣分更多 —— 显然不利于稳定成长。
此外,在 WebShop、ALFWorld 等需要多步交互的任务中,只有完成整个流程才能获得奖励。中间过程无论多么合理,都无法直接获得正向激励。
EMPG 的核心思想:让学习信号更“聪明”
EMPG 不是对现有算法的小修小补,而是从学习动态的本质出发,重构信用分配机制。它包含两个关键组件:
✅ 组件一:自适应梯度调制(Entropy-Modulated Credit Assignment)
通过量化每一步生成文本的token级平均熵来衡量不确定性,并据此动态调整优势函数:
| 轨迹结果 | 高自信(低熵) | 低自信(高熵) |
|---|---|---|
| 成功 | ➕ 强化更新(放大信号) | ➖ 减弱更新(抑制噪声) |
| 失败 | 🔻 严厉惩罚(打击“虚幻自信”) | ⚠️ 宽容对待(允许探索) |
这一机制实现了三个目标:
- 加速对“正确且坚定”行为的学习;
- 抑制不确定动作带来的梯度噪声;
- 主动纠正那些“坚信自己是对的却错了”的危险倾向。
✅ 组件二:未来清晰度奖励(Future Clarity Reward)
仅调整梯度还不够。EMPG 进一步引入一种内在奖励机制,鼓励智能体选择那些能让后续状态更可预测的动作。
具体来说,该奖励基于这样一个原则:
“好的决策不仅解决当前问题,还应减少未来的不确定性。”
形式上,它通过最大化下一状态的策略清晰度(即最小化其熵)来实现,相当于给智能体注入一种“元能力”:主动寻求明确路径,避免陷入模糊困境。
这在实践中意味着,模型更倾向于点击结构清晰的按钮、输入规范指令、选择信息丰富的操作,而非盲目试错。
三、技术实现:如何落地 EMPG?
EMPG 可无缝集成到主流策略梯度框架中(如 GRPO),其工作流程如下:
- 生成轨迹
智能体在环境中执行任务,记录完整动作序列(rollout)及最终成败结果。 - 计算每步不确定性
对每个时间步,使用模型输出的 token 分布计算平均熵,作为该步的不确定性度量。 - 归一化处理
在批次维度上对熵值进行标准化,确保不同任务间的调节尺度一致。 - 策略更新
使用调整后的优势函数进行策略梯度更新,完成一次迭代。
整个过程无需额外标注数据或辅助任务,完全依赖于任务本身的稀疏反馈。
实验验证:全面超越主流基线
研究人员在三个具有代表性的长时域基准任务上测试 EMPG:
| 任务 | 场景说明 |
|---|---|
| WebShop | 根据自然语言指令在模拟电商网站中完成商品搜索与购买 |
| ALFWorld | 在文本版 Minecraft 中完成物品收集与合成任务 |
| Deep Search | 多轮搜索引擎查询以获取深层信息 |
主要结果(以 Qwen2.5-7B-Instruct 为例):
| 方法 | WebShop 成功率 | ALFWorld 成功率 | Deep Search 表现 |
|---|---|---|---|
| GRPO(基线) | 68.1% | 59.3% | 中等 |
| DAPO | 73.2% | 64.5% | 较好 |
| EMPG | 82.7% | 73.8% | 显著提升 |
📌 提升幅度达 +9.5%~+10.3%,且训练过程更加平稳,未出现典型“策略崩溃”现象(即突然性能断崖式下降)。
更值得注意的是,在消融实验中发现:
- 单独使用熵调制已能带来明显增益;
- 加入“未来清晰度”奖励后,模型更少进入死胡同,重试次数减少约 30%。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...