在视觉生成领域,强化学习(Reinforcement Learning, RL)正成为提升模型表现的关键手段。其中,奖励模型(Reward Model, RM)作为引导生成方向的核心组件,直接影响最终输出的质量。然而,在图像与视频生成中,如何构建一个可扩展、鲁棒且能真实反映人类偏好的奖励系统,依然是一个悬而未决的问题。
现有方法面临多重瓶颈:
- 基于CLIP的奖励模型受限于其架构设计,难以处理复杂指令或多模态上下文;
- 广泛使用的Bradley-Terry损失函数与视觉语言模型(VLM)的自回归生成机制存在本质错配;
- 更严重的是,“奖励黑客”问题普遍存在——模型学会“钻空子”,通过微小扰动获取高分,却并未提升实际质量,导致输出趋于单一或失真。
为突破这些限制,字节跳动Seed项目组提出 RewardDance ——一种面向视觉生成任务的新型可扩展奖励建模框架。它不仅提升了生成质量,更重要的是,从机制层面解决了长期困扰RLHF应用的对齐难题。
核心思想:把“打分”变成“回答”
传统奖励模型通常将两个样本进行对比,输出一个标量分数或偏好概率。这类判别式建模方式与主流视觉语言模型的生成式架构不兼容,制约了模型规模与上下文能力的扩展。
RewardDance 的关键创新在于:
将奖励判断重构为一个生成任务 —— 模型不再直接输出分数,而是根据输入条件预测“yes”标记的概率,表示“当前生成结果是否优于参考样本”。
这一转变看似简单,实则意义深远:
- 它使奖励目标与VLM的下一标记预测机制完全对齐;
- 支持自然引入指令、示例、推理链等丰富上下文信息;
- 可无缝集成到现有的生成流程中,无需额外适配模块。
例如,当用户希望生成“一只豹在雾中捕猎鹿”的画面时,RewardDance不仅能判断某张图像是否符合描述,还能结合思维链推理逐步评估细节完整性(如环境氛围、动作合理性),从而提供更具语义深度的反馈信号。
双重扩展:模型更大,上下文更丰富
RewardDance 实现了两个维度上的系统性扩展,这是此前方法难以企及的。
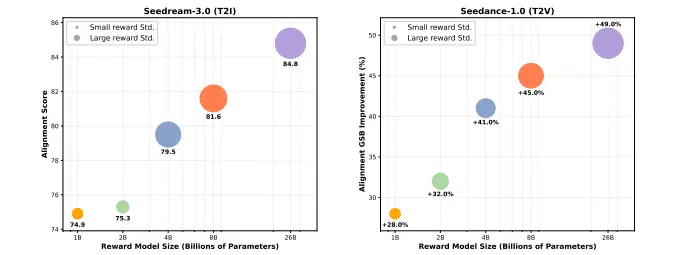
1. 模型扩展:参数规模从1B到26B
研究团队基于InternVL系列架构,训练了从10亿到260亿参数的奖励模型。实验表明,随着模型增大,其对细微差异的辨别能力显著增强,尤其在复杂场景下优势明显。
| 参数规模 | Bench-240得分 |
|---|---|
| 1B | 74.1 |
| 13B | 80.5 |
| 26B | 84.8 |
这是首次在视觉奖励建模中实现超大规模模型的有效训练,验证了“越大越好”在该任务中的可行性。
2. 上下文扩展:支持指令+示例+推理链
不同于传统RM只能接收图像对,RewardDaste允许输入:
- 任务指令(如“请生成更具电影感的画面”)
- 参考图像(用于风格或内容对照)
- 思维链提示(CoT),引导模型分步分析构图、光影、动态逻辑等维度
这种灵活的输入结构极大增强了模型的理解能力,使其更接近人类评审者的决策过程。
对抗“奖励黑客”:保持多样性与真实性
强化学习中最棘手的问题之一是“奖励黑客”(Reward Hacking)——模型发现奖励函数的漏洞,通过非预期方式获得高分,比如添加无关纹理、重复模式以迎合评分标准。
RewardDance 通过以下机制缓解这一问题:
- 大规模模型具备更强的泛化能力,不易被局部信号误导;
- 高维上下文输入增加了“作弊”的成本;
- 实验数据显示,26B模型在RL微调过程中始终保持较高的奖励方差,说明其持续探索多样化高质量输出,而非收敛至少数几种“最优模板”。
这有效缓解了小模型常见的“模式崩溃”现象,确保生成结果既稳定又富有创造力。
实测表现:跨任务领先
RewardDance已在多个视觉生成任务中验证有效性:
| 任务类型 | 测试基准 | 提升幅度 |
|---|---|---|
| 文本到图像 | Bench-240 | +10.7 pts |
| 文本到视频 | SeedVideoBench-1.0 | +49% |
| 图像到视频 | SeedVideoBench-1.0 | +47% |
特别是在视频生成中,RewardDance帮助模型更好捕捉时间连贯性与动作逻辑,使得“由图生视”不再是简单的帧插值,而是具备叙事性的动态演绎。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...