在图像定制领域,个性化生成已逐渐从“一个人一个风格”迈向“多人协同场景”的复杂需求。然而,当一张图中需要同时呈现多个真实人物时,模型常常出现“张冠李戴”——面部特征混淆、身份错位,导致输出失真。这不仅影响视觉真实性,也限制了图像定制在影视预览、虚拟社交、广告设计等场景的落地。
- 项目主页:https://bytedance.github.io/UMO
- GitHub:https://github.com/bytedance/UMO
- 模型:https://huggingface.co/bytedance-research/UMO
- Demo:https://huggingface.co/spaces/bytedance-research/UMO_UNO
- UMO_OmniGen2:https://huggingface.co/spaces/bytedance-research/UMO_OmniGen2
为此,字节跳动智能创造实验室(UXO)团队推出 UMO(Unified Multi-identity Optimization),一个面向多身份图像生成的统一优化框架。作为UXO系列继USO(单主体优化)、UNO(通用对象绑定)之后的新成员,UMO首次系统性地解决了多身份一致性与身份混淆缓解之间的矛盾。

问题本质:我们为什么需要“不认错人”的AI?
当前主流图像定制方法(如DreamBooth、Textual Inversion)在单人定制上已有较好表现。但一旦涉及多个参考身份——比如“父亲在厨房做饭,母亲在客厅看书”,模型往往难以精准区分两个角色的身份特征。
原因在于:
- 人脸具有高度敏感性和细微差异,微小偏差即被察觉;
- 多个嵌入向量共存时容易相互干扰,造成特征泄露或融合;
- 缺乏明确的优化目标来衡量“谁是谁”以及“有没有搞混”。
这就引出了核心挑战:如何在生成过程中,既保证每个角色与对应参考的高度一致,又能清晰区隔不同身份?
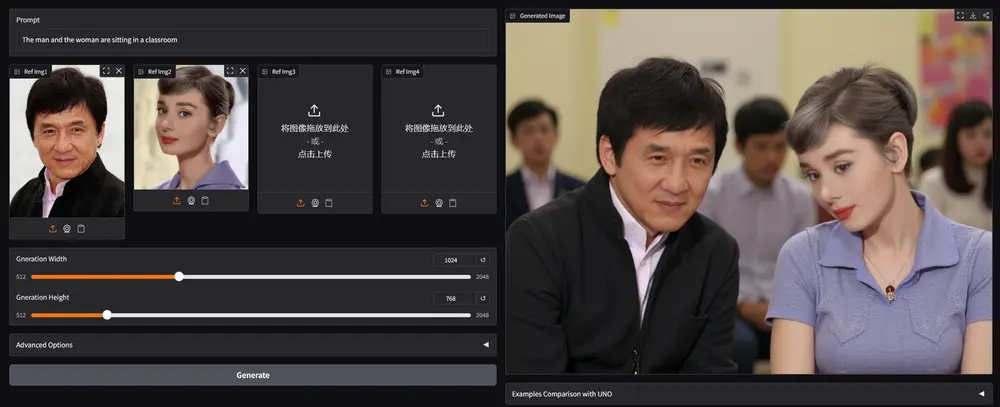
UMO 的答案是:将多身份匹配建模为一个全局最优分配问题。
核心技术:用“匹配奖励”实现精准身份对齐
UMO 的核心思想不是逐个优化身份,而是从整体出发,构建一个多对多身份匹配机制,确保生成结果中的每一个人脸都能找到最合适的归属。
1. 多对多匹配范式(Multi-to-Multi Matching)
传统方法通常采用“一对一绑定”,即每个参考图像独立引导生成。但在多人场景下,这种局部优化无法防止跨身份干扰。
UMO 则将整个生成过程视为一个二分图匹配问题:
- 左侧节点:输入的多个参考身份(来自不同人脸)
- 右侧节点:生成图像中检测到的多个面部区域
- 边权重:基于身份嵌入相似度计算的匹配得分
通过匈牙利算法求解最优匹配路径,最大化整体身份一致性,同时最小化错配概率。
类比理解:就像给一组演员分配剧本角色,UMO 不是随便安排,而是综合演技、外形、气质后做出全局最优选角。
2. 匹配奖励驱动学习(Matching Reward)
为了将这一匹配结果反馈回生成模型,UMO 引入了一种新型强化学习机制——参考奖励反馈学习(ReReFL)。
具体流程如下:
- 扩散模型生成候选图像;
- 提取所有人脸特征并与参考身份进行匹配;
- 计算全局最优匹配得分作为奖励信号;
- 将奖励梯度反向传播至U-Net主干,调整生成路径。
这种方式使得模型在训练中不断学习“什么样的生成方式能获得更高匹配分数”,从而自发规避身份混淆。
3. 单身份 vs 多身份奖励统一设计
- 在单身份场景下,使用基于余弦距离的身份相似度作为奖励(SIR);
- 在多身份场景下,升级为多身份匹配奖励(MIMR),显式建模身份间关系;
- 两者共享同一优化框架,实现无缝切换。

数据与评估:从合成到真实,构建完整验证闭环
为支持大规模训练与公平评估,团队构建了一个可扩展的定制数据集,包含:
- 合成部分:控制变量下的多身份组合图像,用于验证模型基本能力;
- 真实部分:来自公开数据集及授权采集的真实人物图像,提升泛化性。
此外,提出一项新指标:ID-Conf(Identity Confusion Score),专门用于量化身份混淆程度。该指标结合匹配稳定性和交叉相似度,比传统ID-Sim更能反映多身份任务中的真实问题。
实验表现:开源方案中的SOTA
在多个权威基准测试中,UMO展现出显著优势:
| 基准 | 指标 | 表现 |
|---|---|---|
| XVerseBench | ID-Sim ↑ | 显著优于现有开源方法 |
| XVerseBench | ID-Conf ↓ | 混淆率降低最多,排名第一 |
| OmniContext | 综合评分 | 在复杂上下文场景下保持高一致性 |
用户研究同样证实:在身份准确性、提示遵循、美学质量等方面,UMO均获得最高主观评分。
特别值得一提的是,在“父子合影”“朋友聚会”“家庭剧照”等典型多身份场景中,UMO 能稳定保留每个人的关键面部特征(如眼型、鼻梁、笑容弧度),且极少发生特征迁移或混合。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...