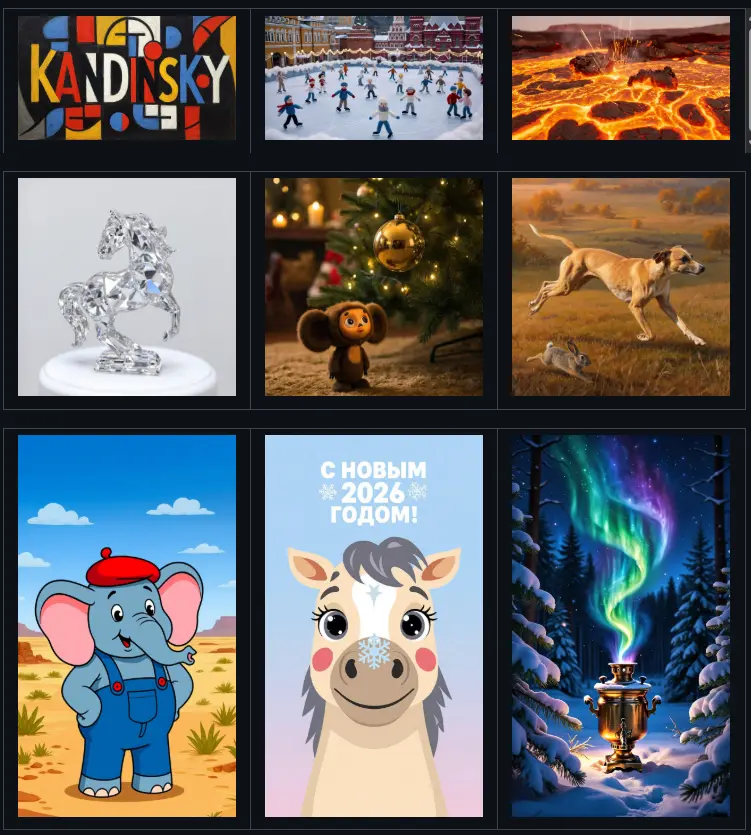
由上海人工智能实验室牵头,联合上海创智学院、上海交通大学、悉尼大学、南京大学、香港中文大学和清华大学的研究团队,共同推出 Lumina-DiMOO ——一个面向多模态生成与理解一体化的新型基础模型。
- 项目主页:https://synbol.github.io/Lumina-DiMOO
- GitHub:https://github.com/Alpha-VLLM/Lumina-DiMOO
- 模型:https://huggingface.co/Alpha-VLLM/Lumina-DiMOO
该模型突破传统架构限制,采用完全离散的扩散建模范式,在文本到图像生成、图像编辑、图像修复、可控生成与高级视觉理解等多项任务中实现统一建模,并在效率与性能上均达到当前开源模型的领先水平。

Lumina-DiMOO 的发布,为构建“一个模型处理多种模态”的通用智能系统提供了新范式。
核心理念:用统一架构打通生成与理解
当前多模态模型普遍面临两大挑战:
- 架构割裂:生成与理解任务常使用不同模型或训练范式(如自回归 + 扩散)
- 效率瓶颈:扩散模型采样步数多、速度慢,难以实用化
Lumina-DiMOO 提出以 “统一离散扩散” 为核心,将文本、图像等模态统一表示为离散 token 序列,在同一扩散框架下完成双向跨模态建模——既能从文本生成图像,也能从图像推理语义。
这意味着:同一个模型,既可作“创作者”,也可作“理解者”。
四大关键技术突破
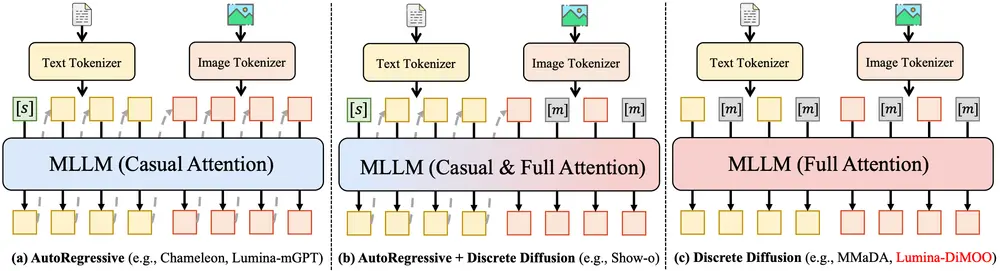
1. 统一的离散扩散架构
不同于主流的连续扩散或混合架构(如 AR + Diffusion),Lumina-DiMOO 全程采用 离散 token 空间中的扩散过程,对输入和输出进行端到端建模。
- 文本和图像均被编码为离散 token 流
- 扩散过程在 token 级别进行噪声添加与去噪
- 支持任意方向的跨模态生成(T2I、I2T、I2I)与理解(VQA、图像描述等)
这一设计实现了真正意义上的架构统一性,无需任务特定头或额外模块。
2. 多样化的多模态能力
Lumina-DiMOO 支持广泛的多模态任务,涵盖生成与理解两大方向:
✅ 多模态生成
- 文本到图像(T2I):支持任意分辨率输出,细节丰富
- 图像到图像(I2I)
- 图像编辑(Edit)
- 主题驱动生成(Subject-driven)
- 图像修复(Inpainting)
- 图像外推(Outpainting)
- 可控生成:通过 prompt 实现风格、布局、对象控制
✅ 高级图像理解
- 视觉问答(VQA)
- 图像描述生成
- 复杂场景语义解析
所有任务共享同一模型参数,无需微调即可切换模式。
3. 更高的采样效率
传统扩散模型通常需要数十甚至上百步采样,影响实用性。Lumina-DiMOO 在保证质量的前提下显著提升推理效率:
- 相比自回归(AR)或混合范式,采样速度更快
- 引入定制化缓存机制,减少重复计算
- 实验表明:采样速度提升达 2 倍
示例配置:
- 图像生成:64 步采样
- 图像理解:块长度 256,采样 128 步
值得注意的是,由于文本生成以块状方式进行,而图像生成为全局解码,因此图像理解的速度增益相对有限,但仍优于同类模型。
4. 卓越的性能表现
在多个标准基准测试中,Lumina-DiMOO 表现出色,全面超越现有开源统一多模态模型,部分指标逼近甚至超过闭源系统。
| 任务类别 | 性能亮点 |
|---|---|
| T2I 质量 | 在 COCO、PartiScore 等评测中取得 SOTA 分数 |
| I2I 编辑 | 保持主体一致性更强,边界更自然 |
| 图像修复 | 在复杂遮挡场景下恢复效果更真实 |
| VQA 准确率 | 显著优于同规模多模态理解模型 |
定性结果也显示,其生成图像在构图、细节和语义对齐方面更具优势。
更多可视化案例可访问官方项目页面查看。
技术意义:推动多模态走向“统一建模”时代
Lumina-DiMOO 的价值不仅在于性能提升,更在于它验证了一条可行的技术路径:
用单一离散扩散框架,统一处理生成与理解任务
这为未来构建“通用感知-生成智能体”提供了重要参考,尤其适用于以下场景:
- AI 创作工具(图文互转、智能编辑)
- 智能助手(看图说话、提问解答)
- 自动化内容审核与生成系统
同时,其高采样效率也为部署于实际产品中提供了可能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











