
在图像生成领域,扩散模型已成主流,但其典型架构依赖变分自编码器(VAE)将图像压缩至低维潜在空间,再在该空间进行生成。这种“两阶段”范式虽能降低计算负担,却也带来了解码伪影与信息损失等固有缺陷。
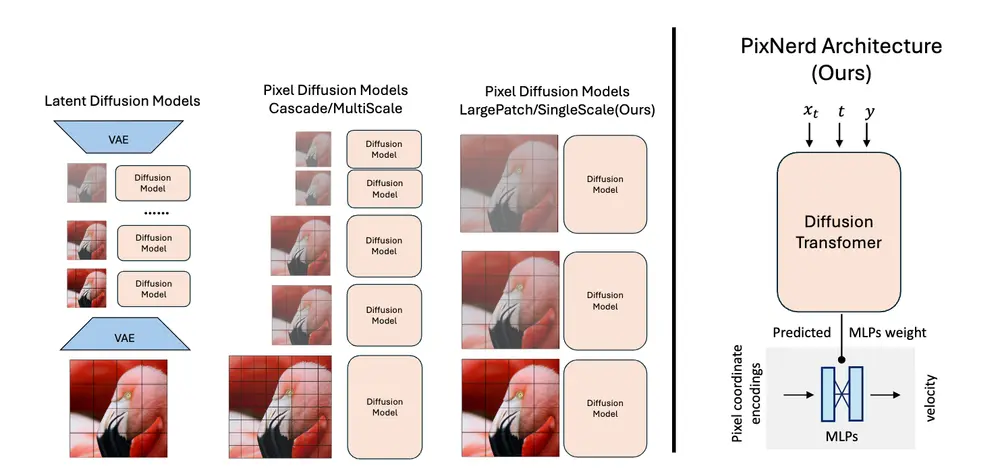
为突破这一瓶颈,南京大学、字节跳动与新加坡国立大学的研究团队联合提出 PixNerd ——一种全新的纯像素空间扩散变换器(Pixel-space Diffusion Transformer)。该模型完全摒弃 VAE,通过引入神经场(Neural Field)技术,直接在像素空间实现高效、高质量的端到端图像生成。
| Dataset | Model | Params | FID | HuggingFace |
|---|---|---|---|---|
| ImageNet256 | PixNerd-XL/16 | 700M | 2.15 | HuggingFace |
| ImageNet512 | PixNerd-XL/16 | 700M | 2.84 | HuggingFace |
PixNerd 不仅避免了潜在空间模型的累积误差,还在 ImageNet 和文本到图像生成基准上取得了极具竞争力的结果,重新定义了像素级扩散模型的可能性。

核心创新:用神经场建模像素细节
传统像素空间扩散模型面临两大挑战:
- 计算复杂度高:直接处理高分辨率像素序列,导致注意力机制开销巨大。
- 高频细节建模困难:难以捕捉纹理、边缘等精细结构。
PixNerd 的核心突破在于:将扩散模型的输出层重构为一个动态神经场。

具体而言:
- 模型主干仍为扩散变换器(Diffusion Transformer),负责全局结构建模。
- 在最终输出阶段,不直接预测像素值,而是预测一个多层感知机(MLP)的权重。
- 该 MLP 作为一个坐标到信号的映射函数(即神经场),接收每个像素的局部坐标编码和噪声状态,输出去噪后的像素值。
✅ 优势:神经场能以紧凑的参数化方式捕捉图像的空间连续性与高频细节,显著提升生成质量。
主要特点
🚫 无需 VAE,单阶段端到端训练
PixNerd 彻底取消了预训练 VAE 和潜在空间编码/解码过程,实现:
- 无信息损失:避免 VAE 压缩带来的模糊与伪影
- 训练简化:单一模型、单一目标函数,无需分阶段优化
- 误差隔离:不再受 VAE 解码质量制约
🖼️ 支持任意分辨率生成
得益于神经场的坐标连续性建模能力,PixNerd 可通过坐标插值生成训练分辨率之外的图像。
- 训练于 256x256 或 512x512
- 推理时可无缝生成更高或更低分辨率图像
- 无需微调或级联模型
这一特性使其在实际应用中更具灵活性。
⚙️ 高效计算设计
为应对像素空间的高维挑战,PixNerd 采用多项优化:
- 大块(Large Patch)处理:降低序列长度
- 轻量化神经场 MLP:控制参数量与推理延迟
- Adams-2 阶采样器:在 50 步内高效完成去噪
在保持高质量的同时,显著优于早期像素扩散模型(如 JetFormer)的计算效率。
工作原理简述
- 输入编码
将带噪图像划分为块,提取块级特征,输入扩散变换器主干。 - 神经场权重预测
模型最后一层输出一个小型 MLP 的权重参数(而非像素值)。 - 坐标映射与去噪
对每个像素位置:- 生成局部坐标编码
- 结合当前噪声状态
- 输入动态 MLP,预测去噪速度
- 迭代去噪
通过多步采样(如 Adams-2),逐步还原清晰图像。
实验结果:性能对标潜在空间模型
PixNerd 在多个权威基准上展现出卓越性能:
| 基准 | 模型 | 指标 | 结果 |
|---|---|---|---|
| ImageNet 256×256 | PixNerd-XL/16 | FID | 2.15 |
| ImageNet 512×512 | PixNerd-XL/16 | FID | 2.84 |
| GenEval | PixNerd-XXL/16 | 总体分数 | 0.73 |
| DPG | PixNerd-XXL/16 | 平均分数 | 80.9 |
- 在 ImageNet 256 上,FID 2.15 超越了同类像素模型(如 FractalMAR、JetFormer),接近顶级潜在空间模型水平。
- 在文本到图像任务中,GenEval 与 DPG 分数表明其语义理解与生成质量可与主流潜在扩散模型媲美。
与传统范式的对比
| 特性 | 传统潜在扩散模型 | PixNerd(纯像素扩散) |
|---|---|---|
| 是否需要 VAE | 是 | 否 |
| 训练阶段 | 两阶段(VAE + 扩散) | 单阶段端到端 |
| 信息损失 | 存在(编码-解码) | 无 |
| 生成分辨率 | 固定或需微调 | 支持任意分辨率 |
| 高频细节 | 依赖 VAE 解码质量 | 神经场直接建模 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











