Meta AI 正式推出 DINOv3 —— 一项在计算机视觉领域具有里程碑意义的自监督学习模型。它不仅刷新了密集预测任务的性能上限,更首次证明:一个通用、冻结的视觉骨干,可以在无需微调的情况下,在多个专业场景中超越专用模型。这一进展标志着 AI 视觉系统正从“任务定制”迈向“通用即用”的新阶段。
- 项目主页:https://ai.meta.com/dinov3
- GitHub:https://github.com/facebookresearch/dinov3
- 模型:https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
什么是 DINOv3?
DINOv3 是 Meta 对其 DINO 系列自监督视觉模型的重大升级,全称为 "DINO version 3"。它通过大规模无标签数据训练,生成高质量、高分辨率的图像特征,适用于目标检测、语义分割、实例分割、视频跟踪等多种下游任务。

与传统模型不同,DINOv3 的核心思想是:
训练一个强大的通用视觉骨干,冻结权重,直接搭配轻量级适配器用于具体任务。
无需对主干网络进行微调,即可实现卓越性能,极大提升了部署效率与泛化能力。
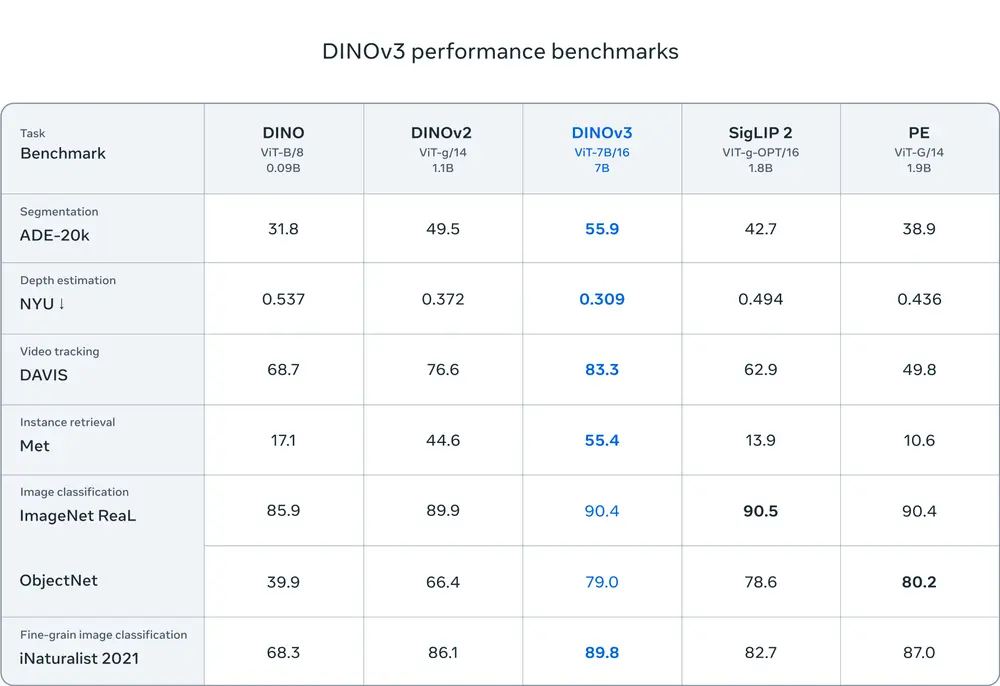
关键突破与技术亮点
| 特性 | 说明 |
|---|---|
| 完全自监督训练 | 使用 17 亿张无标签图像 进行训练,远超前代 DINOv2 的 1.42 亿张。整个过程不依赖人工标注,适合标注成本高昂或稀缺的领域,如遥感、生物医学影像、农业监测等。 |
| 70亿参数骨干网络 | 采用 ViT-G(Giant Vision Transformer)架构,参数规模达 70 亿,是目前最大的公开自监督视觉模型之一,显著提升特征表达能力。 |
| 冻结骨干,无需微调 | 在目标检测、语义分割等任务中,主干网络保持冻结状态,仅训练小型适配器(如提示解码器)。这不仅节省算力,还增强了模型稳定性与跨域适应性。 |
| 多任务超越专用模型 | 在多个基准测试中,DINOv3 在未微调的情况下,表现优于针对特定任务设计的模型(如 Mask R-CNN、U-Net 等),打破了“专用优于通用”的固有认知。 |
| 多种模型变体支持不同场景 | 除大规模 ViT-G 外,Meta 还发布了 ViT-B、ViT-L 和 ConvNeXt 变体,满足从科研实验到边缘设备部署的多样化需求。 |
开源与商业化并行发布
Meta 此次发布不仅包含预训练模型权重,还提供了:
- 完整的训练与评估代码
- 下游任务适配器实现
- Jupyter 示例笔记本
所有资源均以 商业许可证 形式发布,允许企业将其集成到产品中,加速 AI 视觉能力的落地。
这一完整套件的开放,为学术界和工业界提供了即用型工具链,有望推动新一轮视觉应用创新。
真实世界的应用已开始
DINOv3 的潜力已在全球多个实际项目中得到验证:
- 世界资源研究所(WRI)
在肯尼亚的森林监测项目中,使用 DINOv3 后,树冠高度估算误差从 4.1 米降至 1.2 米,精度大幅提升,有助于更精准地评估碳储量与生态变化。 - NASA 喷气推进实验室(JPL)
正将 DINOv3 集成至火星探测机器人视觉系统中,利用其强大的零样本泛化能力,在极端环境下实现高效、低计算开销的场景理解。
这些案例表明,DINOv3 不仅是实验室成果,更是可直接服务于地球观测、太空探索等关键领域的实用技术。
DINOv3 与前代模型对比
| 属性 | DINO / DINOv2 | DINOv3 |
|---|---|---|
| 训练数据量 | 最多 1.42 亿张图像 | 17 亿张图像(+10倍以上) |
| 模型参数 | 最多 11 亿 | 70 亿 |
| 是否需要微调 | 否 | 否(保持冻结) |
| 密集任务表现 | 表现强劲 | 超越专用模型 |
| 模型变体 | ViT-S/B/L/g | ViT-B/L/G, ConvNeXt |
| 发布形式 | 开源 | 商业许可证 + 完整工具套件 |
为什么 DINOv3 如此重要?
- 降低标注依赖:在医疗、农业、工业质检等领域,高质量标注数据稀缺且昂贵。DINOv3 提供了一条无需标注即可获得强视觉表征的路径。
- 提升部署效率:冻结骨干 + 轻量适配器的模式,使得模型更新和迁移成本大幅降低,特别适合多任务、多场景的快速迭代。
- 推动通用视觉发展:它证明了“一个模型,多种用途”的可行性,为构建真正的通用视觉系统奠定了基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...