
音频驱动的肖像动画在基于扩散模型的推动下取得了显著进展,提高了视频质量和唇同步的准确性。然而,这些模型的复杂性增加导致了训练和推理的低效,以及对视频长度和帧间连续性的限制。为了解决这些问题,京东健康国际和浙江大学的研究人员提出了JoyVASA,一种基于扩散的方法,用于生成音频驱动的面部动画,包括面部动态和头部运动。JoyVASA特别关注于提高视频质量和唇形同步的准确性,并且能够处理更复杂的模型所带来的训练和推理效率问题,以及视频长度和帧间连续性的限制。
- 项目主页:https://jdh-algo.github.io/JoyVASA
- GitHub:https://github.com/jdh-algo/JoyVASA
- 模型:https://huggingface.co/jdh-algo/JoyVASA
例如,JoyVASA可以用于创建一个数字虚拟助手,该助手能够根据输入的语音信号,生成一个逼真的、具有动态面部表情和头部动作的3D人物形象。这可以应用于视频会议、虚拟主播或者数字娱乐领域,使得虚拟角色能够更加自然地与观众互动。

方法概述
JoyVASA的主要贡献在于其解耦的面部表示框架和与身份无关的运动生成过程。具体来说,该方法分为三个阶段:
1、解耦的面部表示框架:
解耦动态面部表情与静态3D面部表示:JoyVASA引入了一个解耦的面部表示框架,将动态面部表情与静态3D面部表示分离。这种解耦使得系统能够通过将任何静态3D面部表示与动态运动序列结合来生成更长的视频。
2、扩散变换器生成运动序列:
与角色身份无关的运动生成:在第二阶段,训练一个扩散变换器直接从音频提示生成运动序列,与角色身份无关。这使得模型能够生成与特定角色身份无关的面部动态和头部运动。
3、高质量动画渲染:
使用3D面部表示和生成的运动序列:在第三阶段,使用第一阶段训练的生成器,将3D面部表示和生成的运动序列作为输入,渲染高质量的动画。这一步骤确保了最终生成的视频具有高分辨率和逼真的效果。
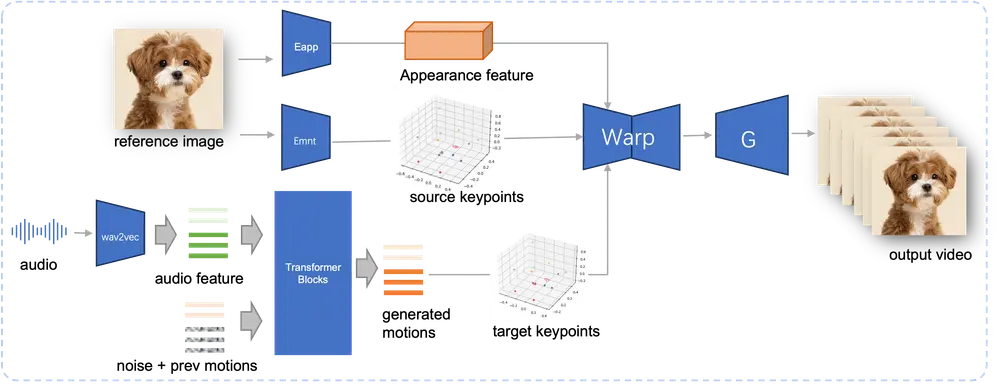
关键特点
解耦的面部表示:解耦动态面部表情与静态3D面部表示,使得系统能够生成更长的视频,不受视频长度和帧间连续性的限制。 与身份无关的运动生成:使用扩散变换器从音频提示生成运动序列,与角色身份无关,提高了模型的泛化能力,适用于不同的人物和动物面部。 高质量动画渲染:利用3D面部表示和生成的运动序列,渲染高质量的动画,确保视频的高分辨率和逼真效果。 多语言支持:模型在混合的中文私有数据和公开的英文数据集上进行训练,支持多语言,扩展了应用范围。
实验结果
实验结果验证了JoyVASA方法的有效性。该模型在生成高质量音频驱动的面部动画方面表现出色,特别是在视频质量和唇同步的准确性方面。此外,模型的泛化能力使其能够无缝地动画化不同的人物和动物面部。
未来工作
提高实时性能:优化模型的训练和推理过程,提高实时性能,使其更适合实时应用场景。 细化表情控制:进一步研究和改进表情控制机制,使生成的动画更加自然和细腻。 扩展应用范围:探索JoyVASA在更多领域的应用,如虚拟现实、游戏和影视制作等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











