由 Meta FAIR、卡内基梅隆大学与约翰霍普金斯大学联合提出的新框架 Darling(Diversity-Aware Reinforcement Learning for Generation),解决大语言模型在后训练中普遍存在的“高质量但低多样性”问题。该方法通过引入语义层面的多样性度量,并将其与质量奖励联合优化,在保持输出准确性的同时,显著提升生成内容的创新性和思想广度。
这一进展为语言模型在创意写作、头脑风暴、开放性问题求解等任务中的应用打开了新空间。
问题背景:后训练为何让模型“变呆”?
在标准的大模型训练流程中,后训练阶段(如RLHF)主要目标是提升响应的准确性、安全性和帮助性。这类优化通常依赖人类偏好数据或自动质量评分,引导模型趋向“最优解”。
但这种优化也带来副作用:模型输出趋于收敛到少数高分模式,形成“安全但重复”的表达习惯。例如,面对“讲一个关于时间旅行的故事”,多个生成结果可能结构雷同、情节趋同——虽然语法正确、逻辑通顺,却缺乏真正的新意。
这种现象被称为分布锐化(distribution sharpening),它削弱了模型在探索性任务中的潜力。
Darling 的核心理念正是对此做出回应:
我们不仅希望模型回答得对,还希望它能想得更多、说得不同。
Darling 做了什么?
Darling 是一种多样性感知的强化学习框架,其目标是让语言模型在生成高质量内容的同时,保持语义上的多样性。
具体来说,它实现了三个关键能力:
- ✅ 质量保障:保留传统强化学习对响应质量的优化能力。
- ✅ 语义多样性建模:不再依赖词级重复率等表面指标,而是学习识别响应之间的深层语义差异。
- ✅ 联合优化机制:将多样性信号作为奖励项,与质量奖励共同指导策略更新。
最终结果是:模型不仅能给出好答案,还能给出“不一样的好答案”。
核心技术:如何衡量“真正”的多样性?
传统方法常使用 n-gram 重复率或 BLEU 下降来间接反映多样性,但这些指标容易被同义词替换欺骗,无法捕捉思想层面的差异。
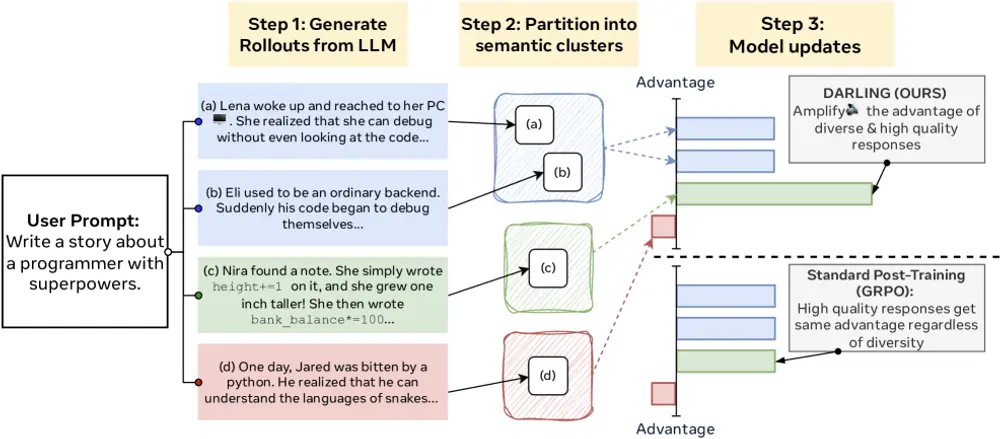
Darling 的突破在于引入了一个可学习的分区函数(learned partition function),其工作流程如下:
- 语义聚类:将一批模型生成的响应按语义相似性划分为若干簇。例如,“用火箭穿越黑洞”和“乘坐时光机回到恐龙时代”属于不同语义路径。
- 多样性评分:通过一个训练好的分类器判断新响应是否落入已有簇中。若为“新簇”,则赋予更高的多样性奖励。
- 奖励融合:将多样性奖励与质量奖励(如人类偏好得分、任务正确率)通过乘法结合,形成复合奖励函数:
R_{\text{total}} = R_{\text{quality}} \times (1 + \alpha \cdot R_{\text{diversity}})这种乘法结构确保只有高质量且新颖的输出才能获得最高奖励。
整个过程在在线强化学习中动态执行,随着训练推进,模型逐渐学会在探索与利用之间取得平衡。
模型无关的设计:适用于多种架构与规模
Darling 不依赖特定模型结构,已在多个模型家族上验证有效性,包括:
- LLaMA 系列(7B–70B)
- Qwen
- Mixtral
无论模型大小或训练数据分布如何,Darling 均能稳定提升质量与多样性的综合表现,展现出良好的泛化能力。
实验结果:全面优于基线
研究在两类典型任务上测试了 Darling 的性能:
1. 不可验证任务(创意类)
- 任务类型:指令遵循、创意写作、开放式建议
- 评估方式:AlpacaEval、ArenaHard(胜率)、NoveltyBench(Distinct 指标)
✅ 结果:Darling 在所有五个基准上均超过仅优化质量的基线方法,生成内容在人工评估中被认为更具原创性和吸引力。
2. 可验证任务(数学推理)
- 任务类型:MATH 数据集中的竞赛级数学题
- 评估方式:pass@1(单次生成正确率)、pass@k(k 次尝试中至少一次正确)
✅ 结果:Darling 在 pass@1 上持平或略优,在 pass@k 上显著领先——说明其生成的解法路径更多样,增加了“命中正确解”的机会。
更值得注意的是,Darling 在训练过程中表现出更强的探索行为:智能体更愿意尝试非主流但潜在有效的推理路径,从而带来长期性能提升。
实际意义:从“标准答案机器”到“创意协作者”
Darling 的价值不仅在于技术指标提升,更在于它重新定义了语言模型的角色:
- 在教育场景中,它可以生成多种解题思路,辅助学生理解不同方法;
- 在内容创作中,它能提供风格各异的故事开头或广告文案;
- 在科研辅助中,它有助于激发假设生成和跨领域联想。
通过显式鼓励多样性,Darling 推动语言模型从“追求唯一正确”向“支持多元表达”演进。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...