
文本到图像(T2I)生成任务的目标是从文本提示生成逼真的图像。尽管扩散模型在这一领域取得了显著进展,但现有方法在处理复杂的多步推理和组合性提示时仍面临挑战。特别是,当文本提示包含多个对象及其属性之间的复杂关系时,最先进的模型往往难以忠实建模这些细节,导致生成的图像出现错误或不一致。
- 项目主页:https://dair-iitd.github.io/GraPE
- GitHub:https://github.com/dair-iitd/GraPE
- PixEdit:https://github.com/dair-iitd/PixEdit
为了解决这些问题,印度理工学院的研究人员提出了一种分解式T2I合成范式GraPE,将复杂的多步生成任务分解为三个独立的步骤:生成、规划和编辑。这种模块化的方法不仅提高了生成图像对复杂文本提示的忠实度,还具有灵活性和可扩展性,适用于任何现有的图像生成和编辑模型。
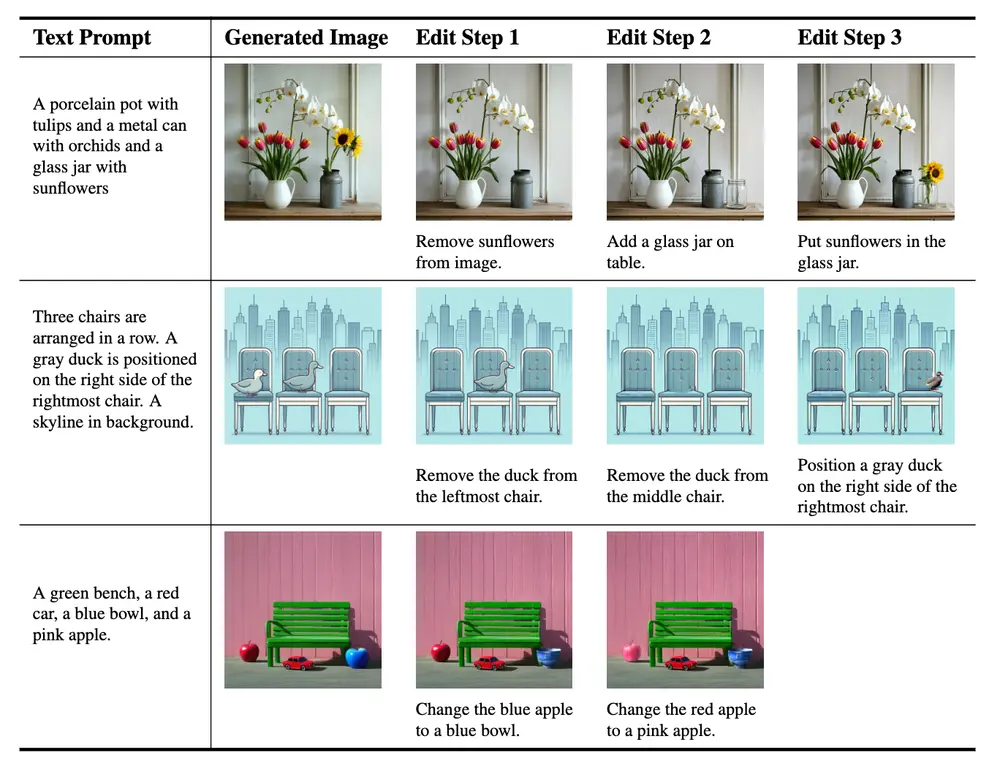
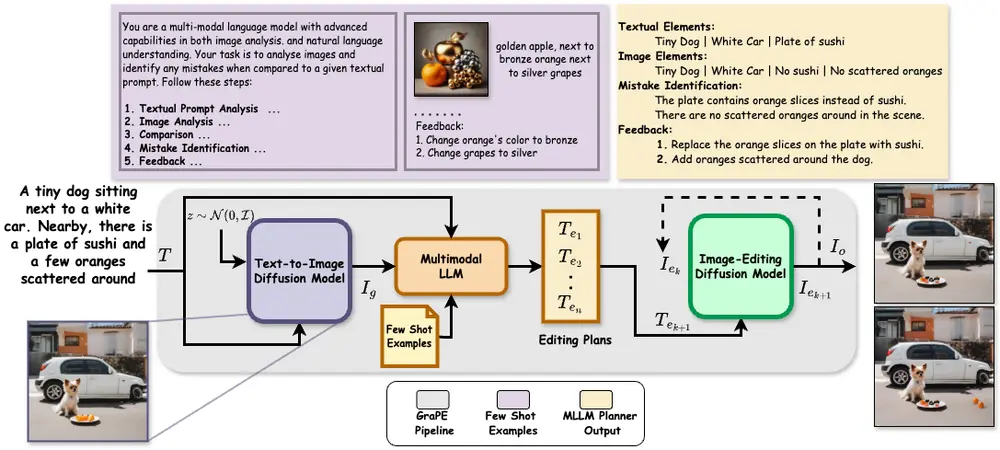
例如,我们有一个文本提示:“一个金色的苹果旁边是一个青铜色的橙子,再旁边是银色的葡萄。”使用GraPE框架,首先会生成一个初步的图像,然后通过多模态大语言模型(MLLM)分析图像与文本提示之间的差异,生成一个编辑计划,最后按照这个计划逐步编辑图像,以确保最终图像准确地反映了文本提示的内容。
方法概述
生成(Generation):
- 使用现有的扩散模型:首先,研究人员使用现有的扩散模型(如DALL·E 3、Stable Diffusion等)根据输入的文本提示生成初始图像。这一步骤利用了扩散模型的强大生成能力,能够快速生成高质量的图像。
规划(Planning):
- 识别错误并生成编辑计划:接下来,研究人员引入了一个多模态大语言模型(MLLMs),用于分析生成的图像,并识别其中的对象及其属性是否符合文本提示的要求。MLLMs能够理解复杂的文本描述,并检测生成图像中的错误或不一致之处。
- 生成纠正步骤序列:基于检测到的错误,MLLMs会生成一个编辑计划,即一系列具体的纠正步骤,指导后续的编辑过程。每个编辑步骤都针对特定的对象或属性进行调整,确保最终生成的图像能够忠实于原始文本提示。
编辑(Editing):
- 顺序执行编辑计划:最后,研究人员使用现有的文本引导图像编辑模型,按照编辑计划对生成的图像进行逐步修改。通过这种方式,模型可以在不重新生成整个图像的情况下,精确地修正图像中的错误或不一致之处,从而提高图像对文本提示的忠实度。
- 组合编辑模型:为了进一步提高编辑的准确性,研究人员还开发了一种能够进行组合编辑的模型。该模型能够在一次操作中同时处理多个对象及其属性的修改,避免了多次编辑带来的累积误差。
方法的优势
- 模块化设计:该方法的模块化性质使得它能够灵活应用于任何现有的图像生成和编辑模型的组合。用户可以根据需要选择不同的生成和编辑模型,而无需重新训练整个系统。
- 无需额外训练:由于该方法依赖于现有的生成和编辑模型,因此不需要额外的训练。这大大降低了开发成本和时间,使得该方法更具实用性和可扩展性。
- 灵活的权衡:该方法允许用户在推理时间计算和组合文本提示性能之间进行灵活权衡。对于简单的文本提示,可以直接使用生成步骤;而对于复杂的多步推理任务,则可以通过引入规划和编辑步骤来提高生成图像的忠实度。
- 提高弱模型的表现:实验结果表明,该方法不仅能够提升最先进模型的性能(高达3个百分点),还能显著缩小较弱模型和较强模型之间的性能差距。这对于那些资源有限或无法访问最新模型的用户来说尤为重要。
工作原理:
GraPE首先使用扩散模型生成一个与文本提示相关的初始图像。然后,MLLM分析这个图像,并与文本提示进行比较,识别出图像中的对象及其属性的错误。基于这些错误,MLLM生成一个编辑计划,该计划包含一系列简单的编辑指令。最后,GraPE使用图像编辑模型按照编辑计划逐步修改初始图像,直到生成的图像忠实于原始文本提示。
实验评估
研究人员在3个基准数据集和10个T2I模型(包括DALLE-3和最新的SD-3.5-Large)上进行了广泛的实验评估。实验结果表明:
- 性能提升:该方法在所有测试模型上均表现出显著的性能提升,特别是在处理复杂文本提示时,生成图像的忠实度得到了明显改善。
- 缩小性能差距:对于较弱的T2I模型,该方法能够显著提升其生成质量,缩小与较强模型之间的差距。
- 组合编辑的效果:引入组合编辑模型后,整体编辑的准确性和效率得到了进一步提高,尤其是在处理多个对象及其属性的修改时表现尤为出色。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











