
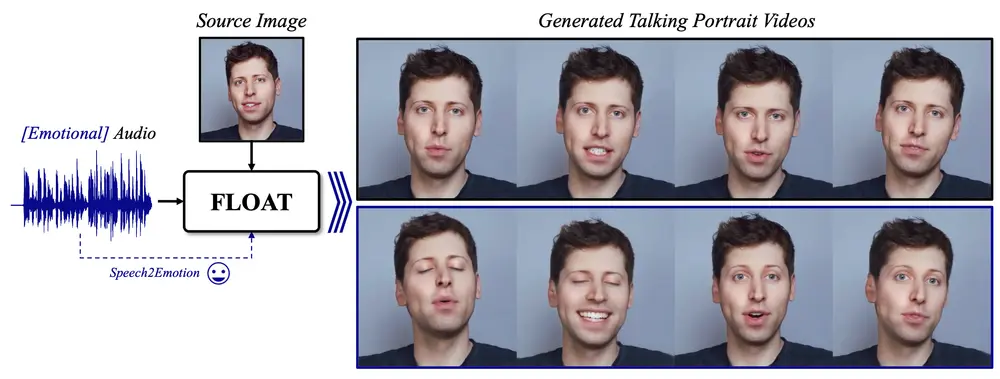
DeepBrain和韩国科学技术院人工智能研究生院的研究人员推出新型音频驱动的肖像视频生成方法FLOAT,它基于流匹配生成模型,能够在给定单一源图像和音频的情况下生成具有自然说话动作的肖像视频。FLOAT通过在学习到的运动潜在空间中匹配运动来生成说话动作,并且能够通过语音驱动的情感标签增强情感相关的说话动作,实现了一种自然的情感意识运动控制方式。
例如,一个历史人物的肖像画,我们希望它能够“活”过来,讲述历史故事。使用FLOAT,我们只需提供该人物的肖像画和一段讲述历史的音频,FLOAT就能生成一个视频,其中肖像画中的人物嘴唇的动作与音频同步,面部表情和头部动作自然,仿佛在真实讲述故事。这种技术可以用于博物馆的互动展览,让历史人物以虚拟形象出现,提供更加生动的历史教育体验。
主要功能
FLOAT的主要功能包括:
- 音频驱动的肖像动画:根据给定的音频信号生成与音频同步的自然说话动作。
- 情感增强:利用语音驱动的情感标签来增强说话动作的情感表达。
- 高效采样:与基于扩散模型的方法相比,FLOAT能够更快速地生成视频,减少了迭代采样的需求。
主要特点
- 运动潜在空间:将生成建模从像素基础的潜在空间转移到学习到的运动潜在空间,实现了时间上一致的运动设计。
- 变换器基础的向量场预测器:使用变换器架构来预测向量场,从而生成时间上一致的运动潜在序列。
- 情感控制:支持基于语音的情感增强,使模型能够根据语音中的情感标签生成更具表现力的动作。
- 效率和性能:在保持高质量样本的同时,FLOAT在计算效率和性能上超越了现有的音频驱动的肖像视频方法。
工作原理
FLOAT的工作原理基于以下几个关键步骤:
- 运动潜在空间编码:使用运动自编码器将源图像编码到运动潜在空间。
- 流匹配生成:在运动潜在空间中,通过流匹配方法生成一系列与音频同步的运动潜在序列。
- 向量场预测:利用基于变换器的向量场预测器,根据音频和情感标签预测生成向量场。
- 情感标签融合:将语音驱动的情感标签与音频信号一起作为条件输入,增强生成动作的情感表达。
- 解码和视频生成:将生成的运动潜在序列解码成视频帧,生成最终的肖像视频。
具体应用场景
FLOAT可以应用于以下场景:
- 虚拟助手和客户服务:创建能够自然对话的虚拟形象,提供更加友好和自然的交互体验。
- 视频会议和社交媒体:生成用户的虚拟形象,用于视频会议或社交媒体平台。
- 娱乐和游戏:为游戏角色创建逼真的面部动画,增强游戏的沉浸感。
- 教育和培训:生成教师或虚拟角色的肖像视频,用于在线课程或培训材料。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











