
Adobe和伊利诺伊大学厄巴纳-香槟分校的研究人员介绍了一种名为NIRVANA的新型文本到图像生成系统,它利用了一种称为近似缓存(Approximate Caching)的技术,旨在高效地服务基于扩散模型(Diffusion Models)的文本到图像生成任务。扩散模型因其能够根据文本提示生成高质量图像而越来越受欢迎,但这些模型在生成图像时需要进行大量的迭代去噪步骤,资源消耗大,且存在显著的延迟。
例如,我们想要生成一张“雪山上的白马骑士”的图片,使用传统的扩散模型,需要从噪声开始,逐步去噪,直到生成最终的图像。而NIRVANA系统通过近似缓存技术,可以跳过一部分去噪步骤,直接重用之前生成过程中的中间噪声状态,从而加快图像生成速度并减少计算资源消耗。
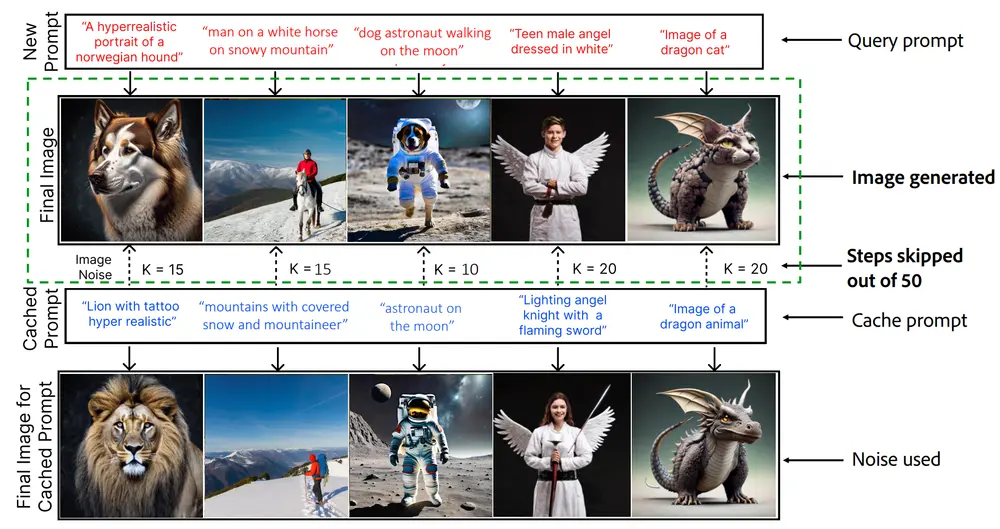
主要功能:
- 近似缓存技术:通过重用先前图像生成过程中的中间噪声状态,减少迭代去噪步骤。
- 缓存管理策略:提出了一种新颖的缓存管理策略LCBFU(Least Computationally Beneficial and Frequently Used),优化存储空间,提高计算效率。
主要特点:
- 降低GPU计算成本:与传统扩散模型相比,NIRVANA实现了21%的GPU计算节省。
- 减少延迟:NIRVANA减少了19.8%的端到端延迟。
- 成本节约:在图像生成上实现了19%的成本节约。
- 高质量图像:用户研究显示,NIRVANA生成的图像质量与昂贵且慢的传统模型相当。
工作原理:
NIRVANA首先为输入的文本提示生成一个嵌入向量,然后在向量数据库(VDB)中查找最接近的缓存嵌入。如果找到相似的缓存条目,系统将从EFS存储中检索相应的中间噪声状态,并将其用于剩余的去噪步骤。这个过程通过控制命中率与计算节省之间的权衡来选择最优的K值(即跳过的去噪步骤数)。
具体应用场景:
- 在线创意平台:如Adobe Firefly,用户可以输入文本提示,快速生成相应的图像。
- 社交媒体和内容创作:用户可以实时生成与文本描述相符的图像,用于社交媒体帖子或博客内容。
- 游戏和娱乐:在游戏或虚拟现实环境中,根据玩家的输入动态生成图像。
- 广告和营销:根据广告文案快速生成吸引人的图像,用于营销活动。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











