
华为诺亚方舟实验室发布多模态大语言模型ILLUME,旨在无缝集成图像和文本的理解与生成。ILLUME凭借其创新的架构和训练策略,在显著减少预训练所需数据量的同时,达到了最先进的性能。ILLUME基于统一的下一个标记预测框架构建,使其能够以卓越的精度处理多模态任务,如理解、生成和编辑。这使得ILLUME成为从图像字幕到多模态编辑等多种应用的通用工具。
例如,考虑一个任务,需要模型根据文本描述生成图像,如“一个小男孩戴着面具,站在草坪前”。ILLUME能够理解文本内容,并生成与描述相符的图像。此外,ILLUME还能够进行自我评估,检查生成的图像与文本描述之间的一致性,从而提高图像生成的准确性和现实性。

ILLUME的关键创新
视觉标记化的数据效率
ILLUME利用了一种视觉标记器,该标记器结合了语义信息,以更有效地对齐图像和文本。这使得预训练数据集仅需要1500万样本,比同类模型小四倍,同时保持了具有竞争力的或更优的性能。
自增强的多模态对齐
ILLUME引入了一种新颖的自增强对齐方案。该模型评估文本描述与其生成的图像之间的一致性,使其能够自我纠正并提高对多模态输入的理解。这带来了更准确的解释和更真实的输出。

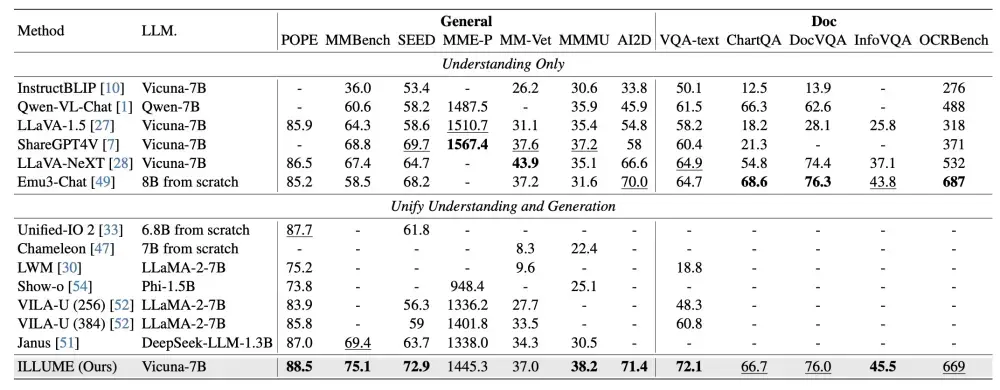
多模态卓越性能
广泛的实验表明,ILLUME在多模态理解、生成和编辑的基准测试中与领先的模型(如Janus)竞争,甚至在某些方面超越了它们。其平衡的架构确保了在专业和统一MLLM任务中的顶级性能。
ILLUME的未来方向
华为计划在以下几个关键领域扩展ILLUME的能力:
更广泛的模态支持:扩展功能以包括视频、音频和3D数据,使其适用于娱乐、医疗和工业设计等多样化的领域。
增强的视觉标记器:开发一种多功能标记器,能够支持图像和视频,同时进一步整合语义洞察。
先进的自增强技术:结合美学质量等标准,使输出更符合人类偏好,从而提高理解和生成能力。
这些进步旨在将ILLUME转变为一个通用、高效的多模态AI系统,适用于任何任务和任何模态。
主要功能和特点
- 多模态理解和生成:ILLUME能够处理图像和文本,执行视觉理解、图像生成和混合模态任务(如对象修改和风格转换)。
- 数据效率:通过视觉分词器和多阶段训练过程,ILLUME只需要15M的图像-文本对数据进行预训练,远少于其他模型。
- 自我增强的多模态对齐方案:ILLUME能够自我评估文本描述和自生成图像之间的一致性,从而提高模型对图像的理解能力,并避免图像生成中的不准确和错误预测。
工作原理
- 视觉分词器:使用预训练的视觉编码器提取图像的语义特征,并通过特征重建损失来监督量化过程,将图像转换为离散的标记。
- MLLM架构:ILLUME扩展了现有的视觉语言模型,增加了额外的视觉词汇表,以生成离散的视觉标记。模型通过统一的语言建模目标,直接最大化每个多模态序列的可能性。
- 训练过程:包括视觉嵌入初始化、统一图像-文本对齐和监督微调三个阶段。
- 自我增强多模态对齐:通过自我评估过程,模型学习识别和理解自身生成的负面样本,从而提高图像解释能力,并在图像生成中避免潜在错误。
具体应用场景
- 视觉理解:如图像问答(VQA)、文档视觉问答(DocVQA)等,ILLUME能够理解和回答有关图像内容的问题。
- 图像生成:根据文本描述生成图像,如“一个穿着红色连衣裙的女孩在海边”。
- 混合模态生成:包括对象移除、对象修改、风格转换等,ILLUME能够根据文本指令对图像进行编辑和风格化处理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











