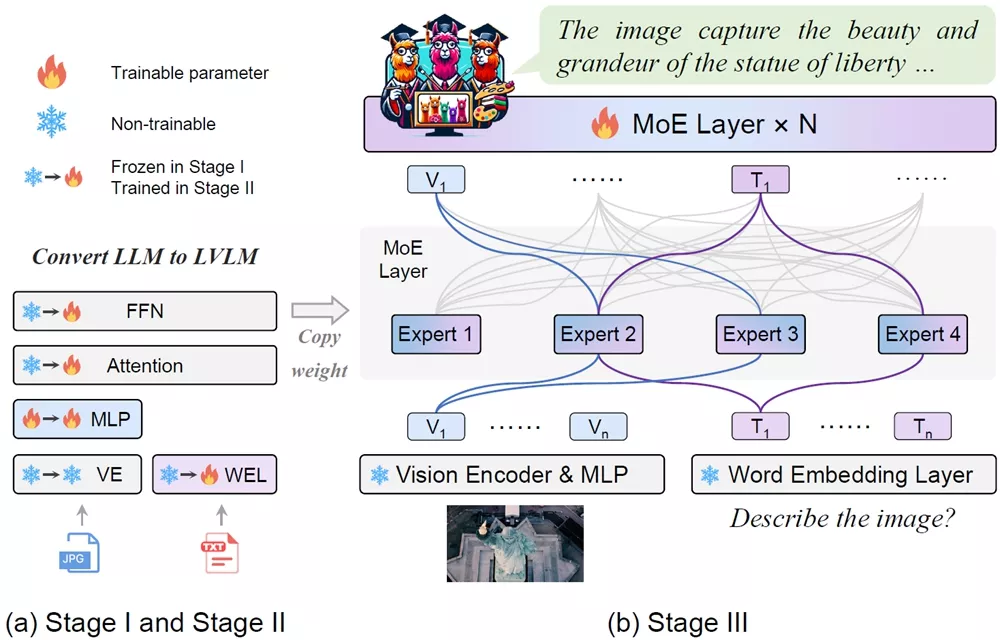
来自北大的研究人员推出多模态的混合专家模型MoE-LLaVA,旨在通过一种新颖的训练策略,有效地提高模型在处理视觉和语言任务时的性能,同时保持计算成本的稳定。
此模型只有3B个稀疏激活参数,与LLaVA-1.5-7B在各种视觉数据集上表现相当,在物体幻觉基准测试中超越了LLaVA-1.5-13B。

主要功能和特点:
- 稀疏模型构建:MoE-LLaVA能够构建一个拥有大量参数但计算成本恒定的稀疏模型。这意味着模型可以在不增加计算负担的情况下,拥有更多的参数来处理更复杂的任务。
- 多专家系统(MoE):模型基于混合专家(Mixture of Experts, MoE)架构,这是一种将多个专家(子模型)组合在一起的方法。每个专家负责处理特定的任务,通过路由器(router)来决定哪个专家处理哪个任务。
- 性能提升:MoE-LLaVA在多个视觉理解数据集上展示了其出色的能力,甚至在某些基准测试中超过了现有的大型模型,如LLaVA-1.5-13B。
- 减少幻觉:模型在输出中减少了幻觉(hallucinations),即在没有足够信息的情况下生成不真实的内容。

工作原理:MoE-LLaVA的工作原理可以分为三个阶段:
- 第一阶段(MoE-tuning):首先,使用一个多层感知器(MLP)来适应视觉输入,让大型语言模型(LLM)理解图像内容。
- 第二阶段:在这个阶段,整个LLM的参数被训练,以赋予模型多模态理解能力。这是通过使用更复杂的指令数据集来实现的,这些数据集要求模型具备更强的多模态理解能力。
- 第三阶段:在这个阶段,使用前向神经网络(FFN)的副本作为专家的初始化权重,并仅训练MoE层。路由器会根据输入动态地将任务分配给不同的专家,只有被激活的专家会参与处理任务,而其他专家保持不活跃。
具体应用场景:MoE-LLaVA可以应用于多种场景,包括但不限于:
- 图像描述:为图像生成描述性文本。
- 视觉问答(VQA):回答关于图像内容的问题。
- 图像检索:根据文本描述找到相关的图像。
- 多模态内容生成:结合图像和文本生成新的多模态内容。
- 辅助视觉障碍人士:通过图像理解帮助视障人士获取周围环境的信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











