
故事讲述视频生成(SVG)是一项旨在从文本脚本创建长时间、多动作、多场景视频的任务。这种技术在媒体和娱乐领域的内容创作中具有巨大潜力,但同时也面临着诸多挑战,包括但不限于:
物体需要展示一系列精细、复杂的动作。 多个物体需要在场景中一致地出现。 主体可能需要在同一场景内执行多个动作,并且这些动作之间需要无缝过渡。
DreamRunner介绍
为了解决上述挑战,北卡罗来纳大学教堂山分校的研究人员开发了新型故事视频生成框架DreamRunner,这个框架能够根据文本脚本生成长篇、多动作、多场景的视频,这些视频连贯地表现输入文本中描述的故事。
例如,你有一个故事脚本,描述了一个女巫和她的猫在一天中的冒险。使用DREAMRUNNER,你可以根据这个脚本生成一个视频,视频中展示了女巫在书房里写作、喝茶,而她的猫坐在旁边;接着女巫在花园中与猫一起散步,低声告别;最后女巫在研究室内翻阅她的魔法书,施展魔法,而猫躺在后面。DREAMRUNNER能够捕捉这些精细的动作和场景转换,生成一个连贯的视频故事。
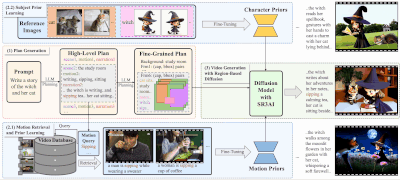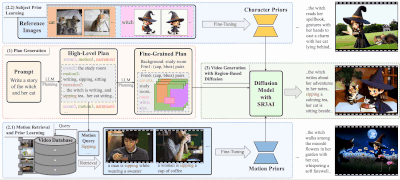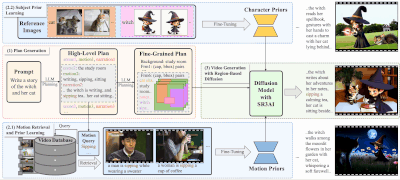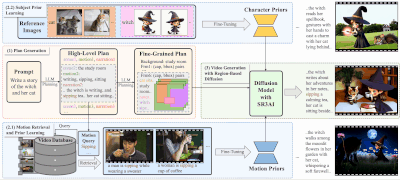
DreamRunner的主要贡献包括:
脚本结构化:使用大型语言模型(LLM)对输入脚本进行结构化处理,以便进行粗粒度的场景规划以及细粒度的对象级布局和动作规划。这一过程确保了视频内容与原始脚本的高度一致性和逻辑连贯性。 检索增强的测试时适应:提出了一种检索增强的测试时适应方法,用于捕捉每个场景中对象的目标动作先验。这种方法支持基于检索视频的多样化动作定制,使得生成的视频能够包含更加复杂、脚本化的动作序列。 基于空间-时间区域的3D注意力与先验注入模块(SR3AI):SR3AI模块用于细粒度的对象-动作绑定和逐帧的语义控制。这一模块通过引入空间-时间区域的3D注意力机制,增强了视频生成过程中对对象动作的精确控制,确保了动作的流畅性和自然性。
主要功能:
故事视频生成(SVG):根据给定的故事脚本生成多场景视频。 复杂动作捕捉:确保视频中的对象展示出与叙事需求相一致的精细、复杂动作。 多对象一致性维护:在多个场景中保持角色的可识别特征,如外观和位置。 场景内平滑过渡:在同一个场景中不同动作或状态之间实现平滑过渡。
工作原理:
DREAMRUNNER的工作原理包括以下几个关键步骤:
计划生成阶段:使用LLM从用户提供的通用故事叙述中生成层次化的视频计划。 动作检索和先验学习阶段:基于LLM生成的动作描述,从视频数据库中检索相关视频,并通过测试时微调学习动作先验。 主题先验学习阶段:使用参考图像通过测试时微调学习主题先验。 视频生成阶段:使用区域基于扩散的模型,结合新颖的空间-时间区域基于的3D注意力和先验注入模块(SR3AI),进行视频生成。
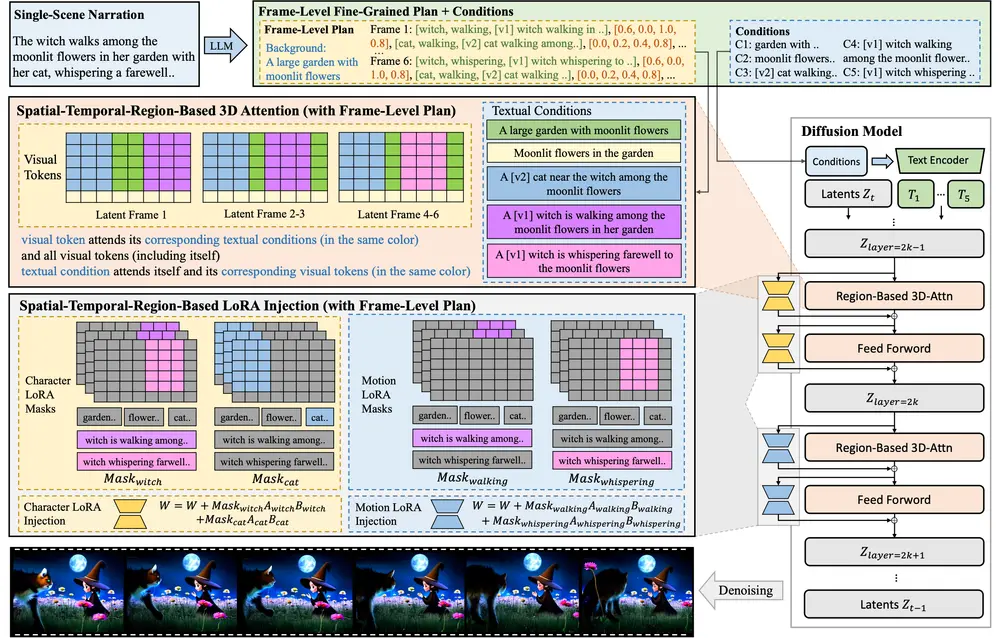
实验结果与优势
通过与多种SVG基线方法的对比,DreamRunner在以下方面展现出了显著的优势:
角色一致性:DreamRunner生成的视频在角色一致性方面表现出色,确保了不同场景之间的角色外观和行为的一致性。 文本对齐:视频内容与输入脚本的高度对齐,保证了故事叙述的准确性和完整性。 平滑过渡:场景切换和动作转换的平滑性得到了显著提升,提升了观众的观看体验。 细粒度条件遵循能力:在组合文本到视频生成任务中,DreamRunner展现了强大的细粒度条件遵循能力,特别是在T2V-ComBench基准测试中显著优于其他基线方法。 多对象交互:定性示例显示,DreamRunner在生成涉及多个对象复杂交互的视频方面表现出色,能够真实地模拟现实生活中的互动场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











