
腾讯推出PosterLLaVa系统,它是一个统一的多模态布局生成器,利用多模态大语言模型(MLLM)来自动化图形设计中的布局生成任务。布局生成是图形设计中非常关键的一环,它需要以一种视觉上令人愉悦且遵循特定约束的方式来安排各种设计元素的位置和大小。PosterLLaVa是一个强大的自动化图形设计工具,它通过结合大型语言模型的能力和结构化的视觉-文本信息,实现了在多种设计任务中的高效和灵活布局生成。
- GitHub:https://github.com/posterllava/PosterLLaVA
- 模型:https://huggingface.co/posterllava/posterllava_v0
- Demo:https://huggingface.co/spaces/posterllava/PosterLLaVA
PosterLLaVa的数据驱动方法采用结构化文本(JSON格式)和视觉指令微调,在特定的视觉和文本约束下生成布局,包括用户自定义的自然语言规范。开发人员进行了广泛实验,并在公共多模态布局生成基准测试中达到了先进水平(SOTA),证明了PosterLLaVa方法的有效性。此外,鉴于现有数据集在捕捉现实世界图形设计复杂性方面的局限性,开发人员提出了两个针对更富挑战性任务(用户约束生成和复杂海报设计)的新数据集,进一步验证了PosterLLaVa在实际场景中的实用性。凭借其卓越的可访问性和适应性,这种方法进一步促进了大规模图形设计任务的自动化。

例如,你需要为一家餐厅设计一个宣传海报。海报上需要有餐厅的名称、一些菜品图片、价格信息,以及促销活动的文字描述。通常,这需要设计师手动调整各个元素的位置和大小,以确保海报既美观又能传达正确的信息。而PosterLLaVa系统能够自动完成这项工作,你只需提供背景图片和设计要求,它就能生成一个既满足要求又具有吸引力的海报布局。
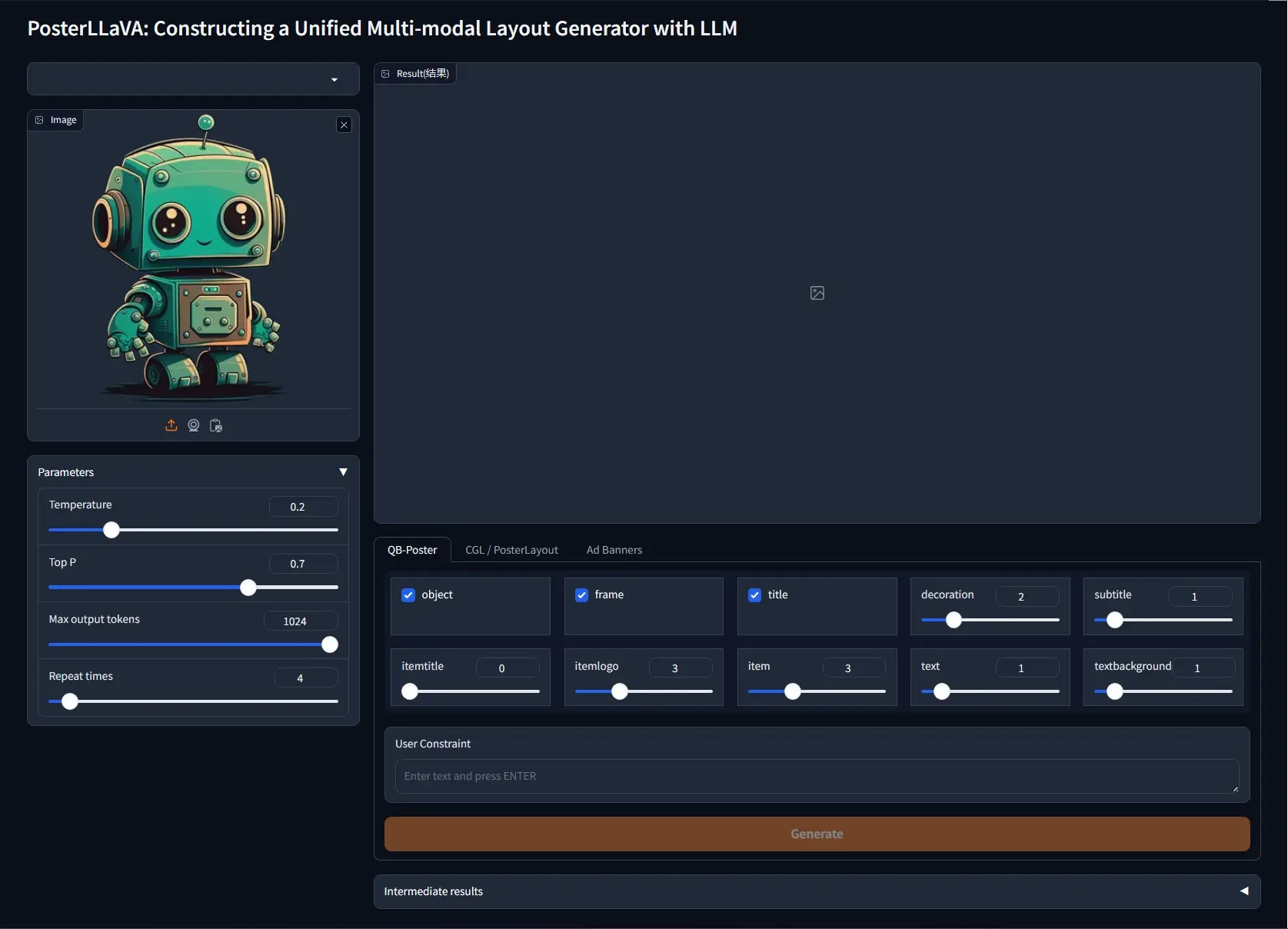
主要功能:
- 自动化布局生成:PosterLLaVa能够自动生成各种图形设计的布局,包括商业海报、移动应用界面、网页、视频缩略图等。
- 多模态设计元素处理:系统能够处理包括文本、图片、背景等在内的多种设计元素。
- 用户定义约束:用户可以通过自然语言描述特定的设计要求,系统会遵循这些要求来生成布局。
主要特点:
- 统一框架:提供了一个适用于不同设计场景的统一布局生成方法。
- 数据驱动方法:采用结构化文本(JSON格式)和视觉指令调整,以生成满足特定视觉和文本约束的布局。
- 高效率和灵活性:与以往的方法相比,PosterLLaVa在大规模应用中更高效,同时能够灵活适应不同的设计需求。
工作原理:
- 多模态LLM:系统使用预训练的多模态大型语言模型(MLLM),该模型能够处理多种视觉-语言任务。
- 结构化文本表示:布局信息通过JSON格式的结构化文本自然表示,使得模型能够理解和生成布局。
- 视觉指令调整:使用预训练的视觉头部将视觉信息转换为文本领域,并微调LLM以解释和生成布局数据。
- 端到端框架:可以直接将自然语言指令翻译成所需的布局,无需额外的网络模块或损失函数。
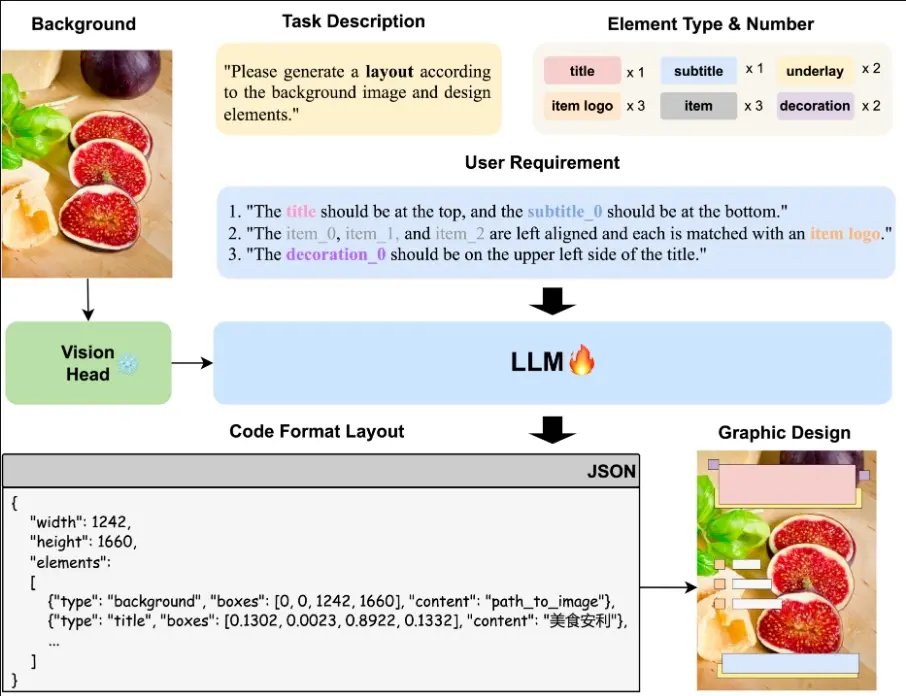
具体应用场景:
- 商业海报设计:为商业广告、促销活动等设计吸引人的海报。
- 移动应用和网页界面设计:自动化生成用户界面布局,提高设计效率。
- 视频内容缩略图:为视频内容创建引人注目的缩略图,以提高点击率。
- 社交媒体视觉内容:为社交媒体平台自动生成视觉吸引人的内容布局。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











