
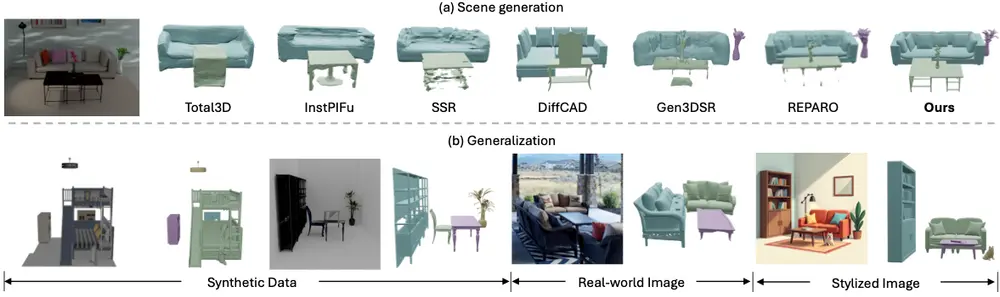
北京航空航天大学、VAST、清华大学和香港大学的研究人员推出新型框架MIDI(Multi-Instance Diffusion),它用于从单张图片生成3D场景。这项技术的核心在于将预训练的图像到3D对象生成模型扩展到多实例扩散模型,同时引入了一种新颖的多实例注意力机制,这使得模型能够直接在生成过程中捕捉到对象间的交互和空间一致性。例如,你有一张包含客厅的图片,客厅里有沙发、茶几和盆栽。MIDI能够从这张2D图片中生成一个3D场景,不仅能够重现沙发、茶几和盆栽的3D模型,还能准确地表现出它们在空间中的相对位置和相互关系。
主要功能和特点
- 多实例生成:MIDI能够同时生成多个3D实例,并且保持它们之间准确的空间关系。
- 高泛化能力:通过在合成数据、真实世界图像和风格化图像上的评估,MIDI展现了强大的泛化能力。
- 端到端流程:MIDI避免了复杂的多步生成流程,提供了一种端到端的3D场景生成方法。
工作原理
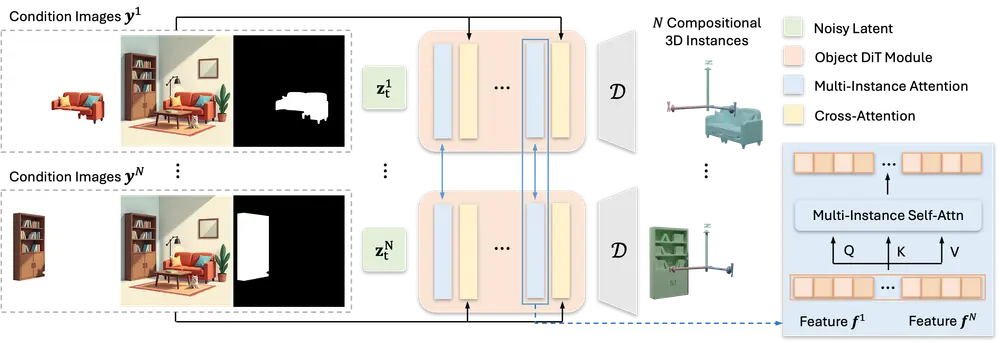
- 多实例扩散模型:MIDI基于预训练的3D对象生成模型,通过扩散过程同时去噪多个3D实例的潜在表示。
- 多实例注意力机制:这一机制允许模型在特征空间中模拟跨实例的交互,从而捕捉对象间的关系和空间依赖。
- 图像条件编码:MIDI使用基于ViT的图像编码器来编码全局场景信息和局部实例细节,并利用交叉注意力层整合这些图像特征。
具体应用场景
- 虚拟现实和增强现实:MIDI可以用于从2D图片创建3D环境,增强用户的沉浸感。
- 游戏开发:快速从概念艺术或截图生成3D游戏环境。
- 电影和动画制作:从静态图像生成3D场景,用于预可视化或作为建模的起点。
- 室内设计:根据平面图或照片生成3D室内设计方案,帮助客户更直观地理解设计效果。
- 教育和培训:创建历史遗迹或复杂结构的3D模型,用于教育目的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











