
现有的基于指令的图像编辑方法通常依赖于监督学习,需要包含输入图像、编辑图像和编辑指令的三元组数据集。这些数据集通常通过现有编辑方法或人工标注生成,引入了偏差并限制了模型的泛化能力。为了克服这些挑战,苏黎世联邦理工学院、慕尼黑工业大学和谷歌的研究人员提出了一种全新的无监督指令驱动图像编辑框架——UIP2P(Unsupervised Instruction-based Image Editing)。
该模型消除了对真实编辑图像的需求,通过引入一种称为 循环编辑一致性(Cycle Edit Consistency, CEC) 的新机制,在训练过程中强制正向和反向编辑的一致性。该框架能够在不需要真实编辑图像数据集的情况下,根据文本指令对图像进行编辑。例如,给定一张图片和一条指令“让鸟变成黄色”,UIP2P能够自动编辑图片,将鸟的颜色改变为黄色,同时保持场景的其他部分不变。

主要功能:
- 无监督学习: 无需成对的输入图像和编辑后的图像,减少对标注数据的依赖。
- 指令驱动的编辑: 根据用户提供的文本指令对图像进行精确编辑。
- 循环编辑一致性(CEC): 通过正向和反向编辑确保编辑的一致性和可逆性。
主要特点:
- 高保真度和精确度: 实验表明,UIP2P在多种编辑任务上的性能优于或媲美现有的监督学习方法。
- 广泛的适用性: 能够处理各种真实图像数据集,扩展了指令驱动图像编辑的应用范围。
- 高效的计算性能: 与需要大型语言模型(LLMs)参与推理的方法相比,UIP2P在推理时更加高效。
工作原理
UIP2P的工作原理基于以下几个关键组件:
- 文本和图像方向一致性: 利用CLIP嵌入空间对文本指令和图像修改进行语义对齐。
- 注意力图一致性: 确保在正向和反向编辑过程中,模型对图像的同一区域保持关注。
- 重建一致性: 通过最小化重建图像和原始输入图像之间的差异,确保编辑可以被准确撤销。
- 统一预测与变化扩散步骤: 在不同的扩散步骤中独立预测噪声,然后将其应用于正向和反向过程中,以重建图像。
通过这些组件,UIP2P能够在保持原始内容完整性的同时进行精确修改,并且通过循环编辑一致性(CEC)确保正向和反向编辑之间的一致性。
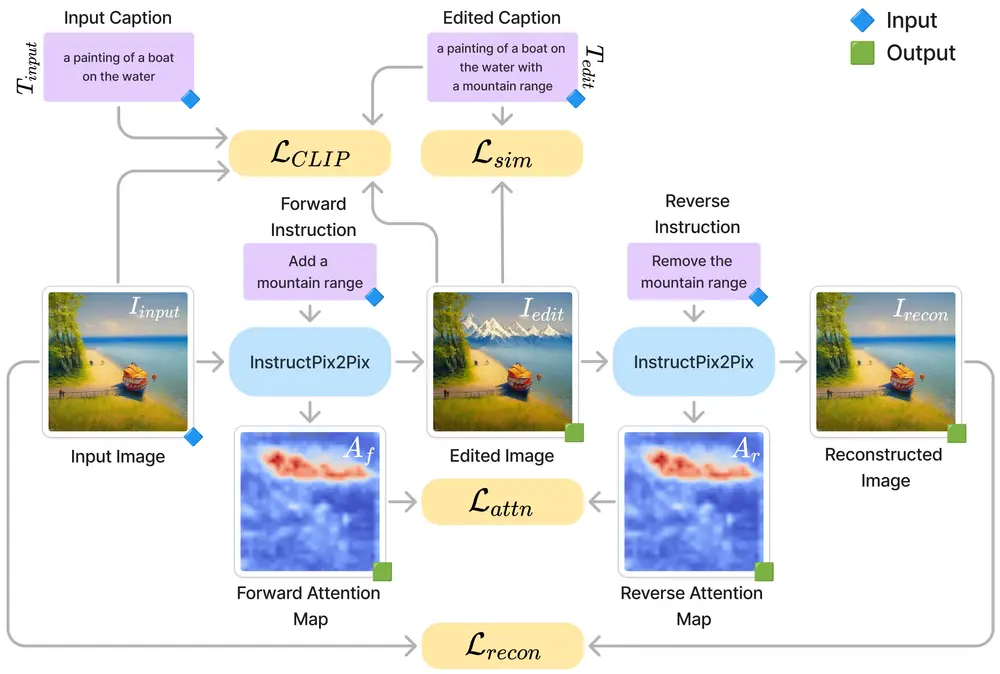
模型架构
UIP2P 的架构基于 IP2P 模型,但引入了 CEC 机制来增强其无监督学习能力。具体来说,UIP2P 包括以下组件:
- 图像编码器:用于将输入图像 编码为潜在表示。
- 指令编码器:用于将编辑指令 和 编码为文本嵌入。
- 生成器:根据输入图像和编辑指令生成编辑后的图像。
- 判别器:用于区分真实图像和生成的编辑图像,确保生成的图像具有高保真度。
实验结果
研究人员通过大量实验验证了 UIP2P 的有效性和优越性。实验结果表明,UIP2P 在多种编辑任务和数据集上表现出色,特别是在以下方面:
- 更高的保真度和精度:UIP2P 能够准确地应用请求的编辑,并保持图像的视觉一致性。与现有的监督方法相比,UIP2P 生成的图像在细节和整体质量上更具优势。
- 更广泛的编辑范围:由于消除了对真实编辑图像的需求,UIP2P 可以处理更广泛的编辑任务,而不会受到特定数据集的限制。这使得模型能够更好地泛化到新的编辑指令和图像类型。
- 减少偏差:传统的监督方法依赖于人工标注或现有编辑方法生成的数据集,容易引入偏差。UIP2P 通过无监督学习避免了这些问题,减少了与监督方法相关的偏差。
- 定性比较:研究人员将 UIP2P 与多个现有的基于指令的图像编辑模型(如 InstructPix2Pix、MagicBrush、HIVE、MGIE 和 SmartEdit)进行了定性比较。结果显示,UIP2P 在准确应用请求的编辑并保持视觉一致性方面表现出相当或更优的结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











