
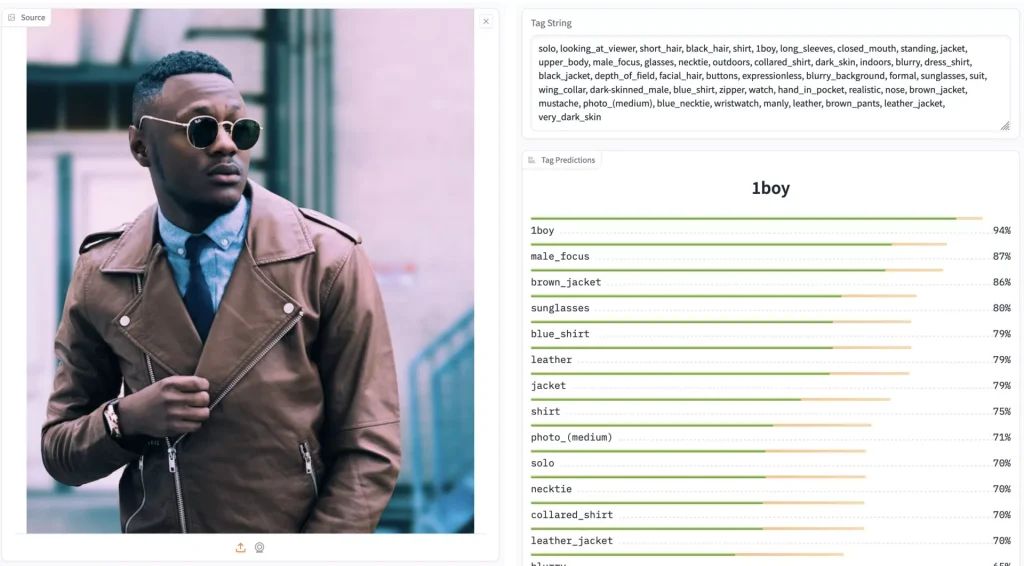
JoyTag是一个机器学习研究者推出的开源图像标注模型,该模型是在Danbooru 2021 + 手动标记的图像数据集上训练的,对训练的内容和标签没有任何过滤和审查,适用于从手绘到摄影的各种图像,在处理多样化和包容性方面表现更好。
只需将图像输入其中,它便能预测出超过5000个不同的标签。可以为SD模型微调提供标注图像,使得微调后的模型能够生成更精确、多样化的图像内容。比如应用在SD webUI中图生图及WD标签器反推等。

这位研究者花费了一年的时间从零开始构建这个基于ViT-B/16,输入尺寸为448x448x3,拥有9100万参数的机器视觉模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











