
在人工智能迈向“通用智能”的征途中,如何处理文本、图像、语音等多种模态数据,一直是业界最大的挑战之一。传统方案往往需要为不同模态设计独立的编码器,或采用复杂的跨模态对齐机制,导致模型架构臃肿、训练困难且推理效率低下。
今日,美团正式发布了重磅成果——LongCat-Next。这是一个原生多模态大模型,它提出了一种颠覆性的架构理念:将所有物理信号(文字、图片、声音)统一映射为同源的离散 Token,并仅通过纯粹的下一个 Token 预测(Next Token Prediction, NTP) 范式,实现了对多模态信号的统一建模、理解与生成。
- 项目主页:https://longcat.chat/longcat-next/intro
- GitHub:https://github.com/meituan-longcat/LongCat-Next
- 模型:https://huggingface.co/meituan-longcat/LongCat-Next
- Demo:https://longcat.chat/longcat-next/
更令人振奋的是,美团宣布将 LongCat-Next 模型及其核心离散分词器全部开源,推动社区构建真正能感知、理解并作用于真实世界的 AI。
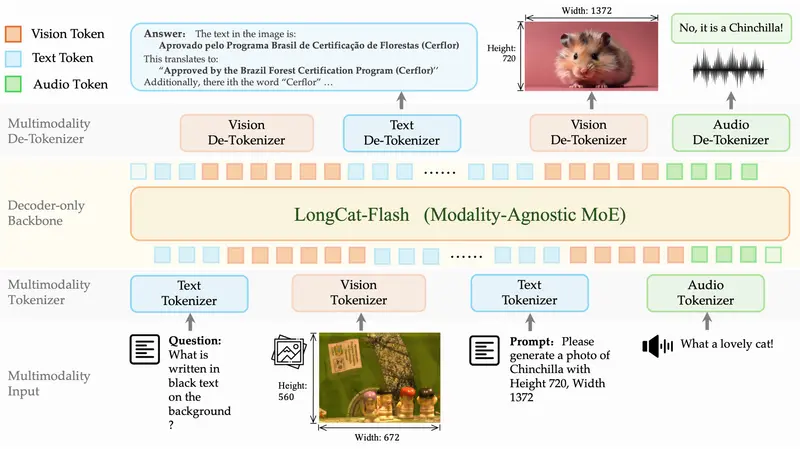
核心突破:DiNA 架构,万物皆 Token
LongCat-Next 的核心在于其独创的 DiNA (Discrete Native Autoregressive) 离散原生自回归架构。
1. 统一范式:打破模态壁垒
在传统模型中,看图、听音、读文是三种不同的任务,需要不同的处理模块。而在 LongCat-Next 眼中,世界万物皆可被量化为离散 ID。
- 文本 离散 Token
- 图像→ 离散 Token (通过 dNaViT 提取)
- 语音 离散 Token (通过声学编码器提取)
无论输入是什么,对模型而言,任务只有一个:预测下一个 Token 是什么。这种极致的简化,消除了模态间的隔阂,让模型能在一个共享的语义空间中自由穿梭。
2. 语义完备的离散表示
如何让离散的 Token 既保留细节又具备语义?美团提出了创新方案:
- 分层离散化:结合语义对齐编码器与残差向量量化(RVQ),生成分层级的离散 Token。
- 双重保留:既保留了高层的语义抽象(理解“这是一只猫”),又保留了底层的细粒度视觉/听觉细节(猫的毛发纹理、叫声频率)。
- dNaViT 接口:推出了离散原生分辨率视觉 Transformer (dNaViT),作为灵活的视觉接口,支持动态 Tokenization,确保与大语言模型无缝集成且性能无损。
3. 高效基座:MoE 架构
LongCat-Next 基于 LongCat-Flash-Lite MoE 构建:
- 总参数量:68.5B (685 亿)
- 激活参数量:仅 3B (30 亿)
- 优势:得益于稀疏混合专家(MoE)机制,模型在保持巨大容量的同时,推理速度极快,部署成本极低。实验显示,其 MoE 路由在训练中自动出现了模态专精化,不同专家自动分工处理文本、图像或语音任务。
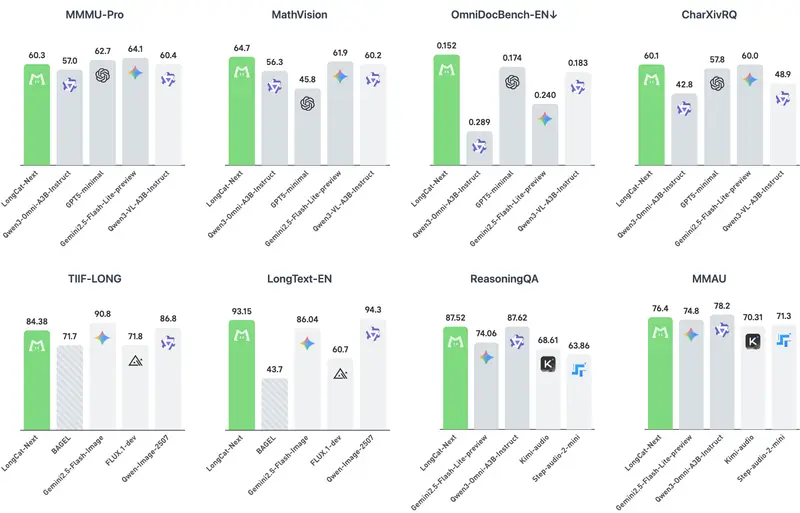
性能实测:全能选手,多项 SOTA
美团官方测试数据显示,LongCat-Next 在统一架构下,不仅没有牺牲单一模态的性能,反而在多个维度达到了专用模型甚至超越专用模型的水平:
视觉能力:理解与生成的完美统一
- 文档理解 (OmniDocBench):得分 0.226,超越 Qwen3-Omni 及专用视觉模型 Qwen3-VL,擅长处理复杂财报、论文和表格。
- 数学推理 (MathVista):得分 83.1,达到领先水平。
- 图像生成 (LongText-Bench):英文渲染得分 93.15,在高达 28 倍压缩率 下仍保持高质量生成,尤其在文字渲染上表现卓越。
- 损耗极低:统一模型的理解损失仅比纯理解模型高 0.006,生成损失甚至比纯生成模型低 0.02。
语音能力:自然交互与克隆
- 语音合成 (TTS):在 SeedTTS 基准上,中英文词错误率 (WER) 分别低至 1.90 和 1.89,音质清晰自然。
- 音频理解:MMAU 得分 76.40,TUT2017 得分 43.09,均达先进水平。
- 特色功能:支持低延迟并行生成(边说边想)和可定制语音克隆,让语音交互更具个性化。
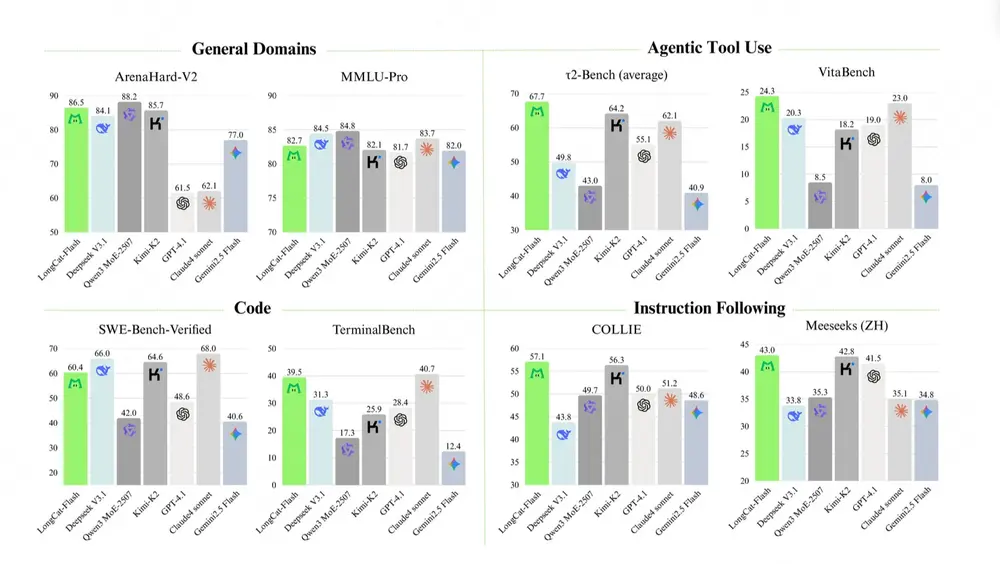
文本与智能体:基石稳固,执行强力
- 纯文本能力:MMLU-Pro 77.02,C-Eval 86.80,证明多模态训练未削弱语言核心能力,反而有所增强。
- 工具调用 (τ²-Bench):零售场景得分 73.68,大幅领先 Qwen3-Next-80B-A3B-Instruct (57.3)。
- 代码能力 (SWE-Bench):得分 43.0,超越同类模型,具备强大的软件工程解决能力。
开源意义:构建真实世界的 AI
美团此次开源不仅仅是释放权重,更是开放了一套完整的原生多模态方法论:
- 模型权重:LongCat-Next (MoE 68.5B/3B) 完整参数。
- 核心组件:DiNA 架构代码、离散分词器 (Tokenizer/Detokenizer)、dNaViT 视觉接口。
- 训练范式:验证了“离散 Token 统一多模态”的可行性,为社区提供了新的研究基线。
这一举措将极大降低多模态 AI 的开发门槛。开发者无需再纠结于复杂的跨模态对齐算法,只需基于统一的 Token 流,即可构建能看、能听、能说、能做的全能智能体。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











