想象一下这个场景:你正在看一部长达两小时的电影直播,中途你指着屏幕对 AI 助手说:“记住那个穿红衣服的女孩,她叫小红。”
十分钟后,你问:“小红现在在干嘛?” AI 立刻回答:“她在厨房切菜。”
半小时后,你又问:“刚才小红进门时穿的是什么鞋子?” AI 迅速回溯画面:“她穿的是白色运动鞋。”
这听起来像是一个拥有完美记忆的人类朋友在陪你看片,但对现有的 AI 来说,这几乎是不可能完成的任务。目前的 AI 要么只能处理静态图片,要么必须把整个视频看完才能回答问题,更无法做到“边看边学、即时记忆”。
- GitHub:https://github.com/Yuanhong-Zheng/PEARL
由北京大学、Adobe、CASIA、Stepfun、中山大学及中关村学院联合推出的 PEARL 框架,正式打破了这一僵局。它提出了全新的“个性化流式视频理解”(PSVU)任务,让 AI 首次具备了像人类一样实时识别新概念、持续记忆并精准回溯的能力。
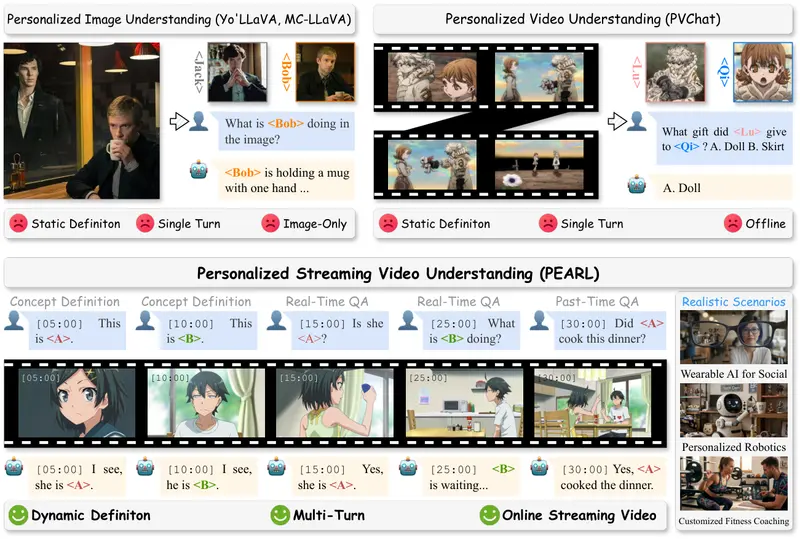
核心突破:从“离线阅卷”到“实时陪看”
传统的视频 AI 像是“考完试再阅卷”的学生——必须看完整个视频文件,才能开始分析问题。而 PEARL 则像是一个坐在你身边的“实时解说员”:
- 流式输入:视频数据像水流一样源源不断进入,AI 同步处理,无需等待视频结束。
- 即时注册:用户随时可以定义新概念(人名、物体、动作),AI 立即“记在小本本上”。
- 双向问答:既能回答“现在发生了什么”(实时),也能回答“刚才发生了什么”(回溯)。
PEARL 是如何做到的?三大黑科技
PEARL 之所以能实现这一壮举,且无需重新训练模型(即插即用),得益于其巧妙的三大核心设计:
1. 双粒度记忆系统:分开记“人”和“事”
PEARL 没有把所有信息混在一起,而是建立了两个独立的“档案库”:
- 概念记忆(Concept Memory):专门存“名片”。当你说“这是小红”时,AI 提取她的核心特征(如“黑发、圆脸”),忽略易变细节(如衣服颜色),生成一张文字 + 图片的“名片”存起来。
- 流式记忆(Streaming Memory):专门存“编年史”。视频被自动切割成一个个场景片段,压缩成数字指纹,按时间顺序存入档案柜。
优势:这种分离让检索极快。问“小红刚才在干嘛”时,AI 先查“名片库”确认小红长啥样,再去“编年史”里找匹配的画面,效率倍增。
2. 概念感知检索:把“人名”翻译成“描述”
AI 底层其实不懂“小红”这个名字,它只懂视觉特征。PEARL 拥有一个智能查询改写器:
- 用户问:“小红在做什么?”
- AI 内部转化:“那个年轻女性、黑色长发、圆脸的人在做什么?”
- 执行:用这段描述去视频流中检索匹配的画面。
这种机制确保了即使视频里出现了十个不同的人,AI 也能精准锁定你定义的“小红”,而不会张冠李戴。
3. 即插即用架构:无需训练,兼容性强
PEARL 不是一个需要海量数据训练的庞大模型,而是一个轻量级框架。
- 零参数更新:不需要微调基础模型,直接在推理阶段挂载记忆和检索模块即可。
- 广泛兼容:论文测试了 LLaVA、Qwen2-VL、Qwen3-VL 等多种主流视觉语言模型,接入 PEARL 后性能均大幅提升。
实测表现:碾压现有方案
研究团队构建了首个专用基准测试 PEARL-Bench(包含 132 个视频、2173 个精细标注问题),结果令人震惊:
- 超越离线模型:在传统离线模型上应用 PEARL,准确率从 32.7% 飙升至 52.2%,提升近 20 个百分点,甚至超越了谷歌最新的 Gemini 3 Pro。
- 领跑在线模型:相比其他流式视频模型,PEARL 领先幅度高达 17%。
- 通用性验证:无论底层换哪个模型,PEARL 都能带来显著增益(最高提升 23.5%)。
- 动作识别也精通:不仅能认人,还能学习自定义动作(如“旋转跳跃”),在该任务上准确率高达 48.4%,远超竞品。
应用场景:未来已来
PEARL 的出现将彻底改变人机交互的形态:
- 智能直播助手:实时识别主播提到的商品、人物,回答观众关于历史片段的提问。
- 家庭监控伴侣:“刚才那个穿蓝衣服的人进过客厅吗?”“宝宝上次哭是什么时候?”
- 视频会议秘书:自动记录参会者发言,会后随时查询“王总刚才对预算说了什么?”
- 沉浸式教育:在看教学视频时,随时定义实验步骤或化学试剂,AI 实时追踪并解答。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











