
DeepSeek 发布 OCR-V2,这不是一次常规升级,而是一次架构级革新:彻底弃用 CLIP 视觉编码器,改用小型 LLM(Qwen2-0.5B)作为视觉编码器,并引入 “视觉因果流”(Visual Causal Flow)机制,让模型学会按人类阅读习惯处理文档——先看标题,再读正文,跳过页眉页脚,正确穿越双栏与表格。
- GitHub:https://github.com/deepseek-ai/DeepSeek-OCR-2
- 模型:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
这一设计解决了传统多模态模型在 OCR 任务中的根本缺陷:它们“看图”,但不会“读书”。
为什么 CLIP 不适合 OCR?
CLIP 是为“图文匹配”而生的——它把图像压缩成一个全局向量,用于回答“这张图是否包含狗?”这类问题。
但 OCR 需要的是顺序感知:必须知道“这句话在上一段之后”、“这个单元格属于左边那列”。
传统方法(包括 DeepSeek-OCR V1)将图像切成 16×16 的 patch,按光栅扫描顺序(从左到右、从上到下)拼接成 token 序列。
这在单栏文本中尚可,但在双栏论文、复杂表格、浮动公式面前彻底失效——同一语义单元被强行拆散,导致 LLM 无法还原正确阅读顺序。
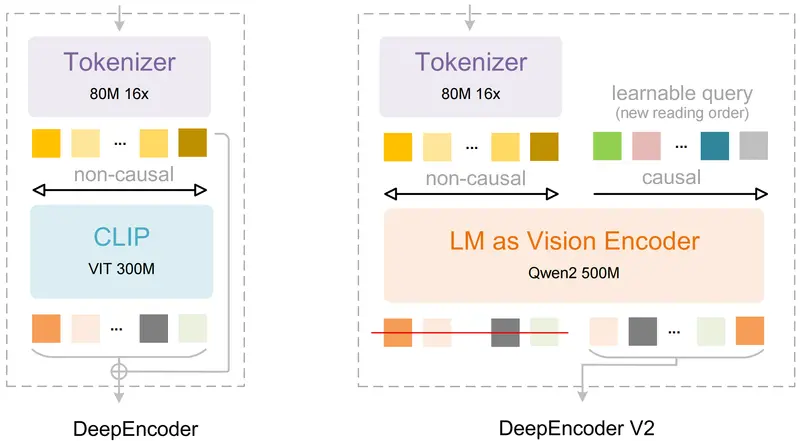
DeepSeek-OCR-V2 的核心创新:视觉因果流
架构概览
- 视觉编码器:Qwen2-0.5B(decoder-only LLM)
- 关键组件:可学习的 Causal Flow Query(因果流查询)
- 输出:一条语义连贯的 1D token 序列,顺序接近人类眼动轨迹
工作流程(三步流水线)
- Tokenizer(80M)
基于 SAM + 卷积,将图像下采样为 patch tokens(16× 分辨率) - DeepEncoder V2(0.5B)
- 先用双向注意力保留全局上下文
- 再引入等量 Causal Flow Query(数量 = patch 数)
- Query 通过因果注意力动态“阅读”patch,学习最优处理顺序
- 最终仅输出 已重排序的 Query tokens
- DeepSeek-MoE Decoder(3B,激活 0.5B)
接收排序后的 token,自回归生成 OCR 文本(支持 Markdown / LaTeX)
✅ 关键设计:Query 与 patch 一一对应,确保信息无损;因果注意力强制顺序决策,避免全局混淆。
性能提升:不只是精度,更是效率
在 OmniDocBench v1.5 基准上的表现
| 模型 | 视觉 Token 上限 | 综合错误率 | 阅读顺序错误 | 表格错误 | 公式错误 |
|---|---|---|---|---|---|
| DeepSeek-OCR (V1) | 1156 | 12.6% | 0.085 | 0.123 | 0.236 |
| DeepSeek-OCR-V2 | 1120 | 8.9% | 0.057 | 0.096 | 0.198 |
| Gemini-3 Pro | 1120 | 11.5% | 0.115 | — | — |
生产环境指标
- 重复字符率:从 6.25% → 4.17%(在线用户图片)
- 预训练数据质量:PDF 批处理重复率从 3.69% → 2.88%
- Token 压缩率:1024×1024 图像仅需 256–1120 token,比同类模型节省 30–70% 序列长度
三大工程优势
- 端到端文档理解
输入任意扫描件/PDF/手写笔记,直接输出带结构的文本(Markdown/LaTeX),无需后处理 - 阅读顺序恢复
自动识别标题、作者、双栏、表格、脚注,并按人类逻辑重组内容 - 生产级鲁棒性
低重复率、高容错性,已作为 DeepSeek 大模型预训练的数据管道,日处理千万页文档
典型应用场景
- LLM 的“眼睛”:为 DeepSeek-Chat、GPT 等提供高精度文档读取能力
- 学术工具:一键将双栏论文转为结构化 Markdown,保留公式与参考文献
- 企业 OCR:处理带印章遮挡的发票、财报、合同,准确恢复表格结构
- 多模态统一入口:同一套 LLM-style 编码器未来可扩展至音频、视频,实现“一个编码器,多种模态”
为什么用 LLM 做视觉编码器?
- 天然对齐:编码器与解码器同为 LLM 架构,token 语义空间一致
- 顺序建模强项:LLM 的因果注意力天生适合处理序列依赖
- 训练效率高:三阶段训练(先训编码器 → 联合 query → 只训解码器),效率翻倍
这不是“为了不同而不同”,而是针对 OCR 任务本质的精准设计。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











