字节跳动与香港大学联合发布 Mini-o3 ——一个具备强大图像理解与长程多轮交互能力的开源多模态模型。该模型能够生成类似 OpenAI o3 风格的代理行为轨迹,在复杂视觉搜索任务中实现数十轮持续推理,显著超越现有开源方案。
- 项目主页:https://mini-o3.github.io
- GitHub:https://github.com/Mini-o3/Mini-o3
- 模型:https://huggingface.co/Mini-o3/models
更重要的是,研究团队已将 完整训练配方、代码、模型权重与数据集全面开源,为社区提供了一套可复现、可扩展的视觉智能体构建范式。
背景:现有开源模型的局限
近年来,大型多模态模型在结合图像工具与强化学习后,已在视觉问题解决方面取得显著进展。然而,大多数开源方法存在两大瓶颈:
- 推理模式单一:多为线性或浅层推理,缺乏探索性思维(如试错、回溯)
- 交互轮次受限:通常仅支持 3–6 轮交互,难以应对需要长期规划与动态调整的复杂任务
这使得它们在真实场景中的应用受限,尤其是在高分辨率图像中定位微小目标、排除干扰项等挑战性任务上表现不佳。
Mini-o3 正是为突破这些限制而设计。
核心目标:打造可扩展的视觉推理智能体
Mini-o3 的目标不是简单模仿 OpenAI o3,而是构建一个具备深度思考能力、推理路径可自然扩展的开源替代方案。其核心理念是:
“让模型像人类一样,在面对复杂图像时,通过多轮缩放、观察、假设与验证,逐步逼近答案。”
为此,团队从数据、训练策略到测试机制进行了系统性设计。

关键技术突破
1. Visual Probe 数据集:专为探索性推理设计
团队构建了 Visual Probe——一个包含数千个高难度视觉搜索问题的数据集,特点包括:
- 图像分辨率高,目标微小且隐蔽
- 干扰对象众多,需精细辨别
- 任务需通过多步操作(如放大、移动视野)完成
- 强调“试错+反馈”机制,模拟真实探索过程
该数据集成为训练和评估深度推理能力的基础。
2. 多样化冷启动轨迹:激发丰富推理模式
为避免模型陷入固定思维路径,团队开发了一套迭代式数据收集管道,生成多样化的初始推理轨迹,涵盖多种策略:
- 深度优先搜索(DFS):逐层深入特定区域
- 试错探索:随机采样不同区域并根据反馈调整
- 目标维护:持续追踪潜在目标,防止偏离主任务
这些轨迹作为监督微调(SFT)阶段的高质量种子数据,帮助模型建立多元化的决策习惯。
3. 两阶段训练流程
Mini-o3 采用标准但高效的两阶段训练框架:
| 阶段 | 方法 | 目标 |
|---|---|---|
| 第一阶段:监督微调(SFT) | 使用冷启动轨迹进行有监督训练 | 让模型学会基本交互与推理模式 |
| 第二阶段:强化学习(RL) | 采用 GRPO 算法,外部 LLM 作为奖励模型 | 优化长期决策质量,鼓励成功路径 |
其中,奖励信号由外部大语言模型(LLM)评判生成轨迹的质量,确保反馈与任务目标一致。
4. “超轮次掩码”策略:实现测试时可扩展性
这是 Mini-o3 最具创新性的设计之一。
传统做法在训练中设定最大交互轮次(如 6 轮),并对超出部分施加惩罚,导致模型在测试时无法自然扩展。
Mini-o3 提出 “超轮次掩码(Over-Round Masking)”策略:
- 训练时仍以 6 轮为上限,保证效率
- 但对超过轮次的部分不进行负向惩罚
- 模型在测试时可自由延续推理,最多扩展至 32 轮以上
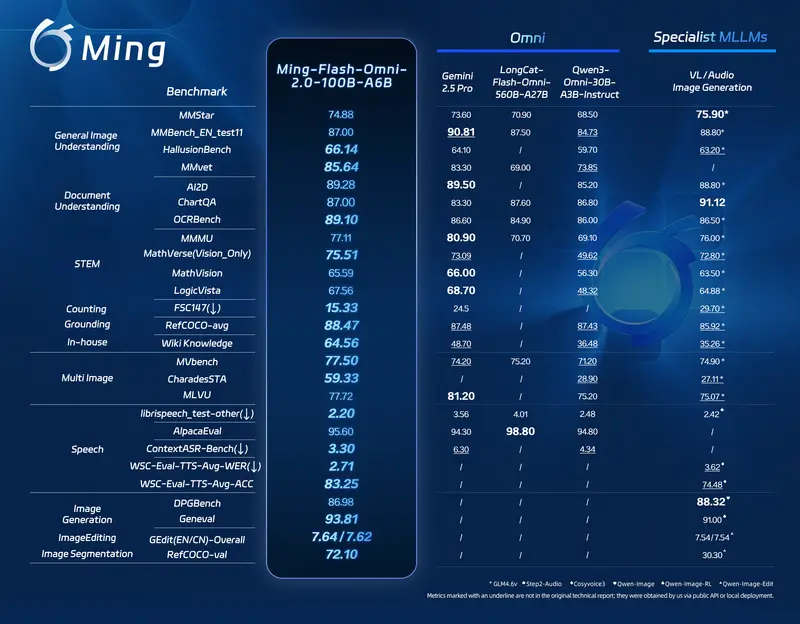
结果表明:随着轮次增加,准确率稳步上升,证明模型真正掌握了“越想越清楚”的能力。
性能表现:多项基准领先
在多个权威视觉任务基准上的实验显示,Mini-o3 表现出色:
| 基准 | 准确率 | 对比优势 |
|---|---|---|
| VisualProbe-Hard | 48.0% | 显著高于其他开源模型 |
| V* Bench | SOTA | 在复杂导航任务中排名第一 |
| HR-Bench | SOTA | 高分辨率目标搜索表现优异 |
| MME-Realworld | 高分 | 真实世界图像理解能力强 |
更关键的是:
- 从 4 轮 → 32 轮,准确率从 35.1% 提升至 48.0%
- 推理路径展现出复杂的思维链:回溯、对比、假设验证等行为频繁出现
- 成功解决诸如“在卫星图中找特定车辆”“在显微图像中识别病变细胞”等极端任务
主要特点总结
| 特性 | 说明 |
|---|---|
| 深度多轮推理 | 支持长达数十轮的连续交互,适合复杂探索任务 |
| 多样化推理模式 | 可自发采用 DFS、试错、目标保持等多种策略 |
| 测试时可扩展 | 尽管训练限6轮,推理可自然延展,无硬性截断 |
| 开源完整配方 | 包括数据集、代码、训练脚本、模型权重全部公开 |
| 轻量高效架构 | 相较闭源系统更易部署与二次开发 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











