
蚂蚁集团 inclusionAI 项目组 正式发布 M2-Reasoning-7B,一个在通用推理与空间推理领域表现卓越的多模态大语言模型(MLLM)。该模型基于 70 亿参数架构,通过创新的数据生成流水线和动态多任务训练策略,在 8 个主流基准测试中创下新的技术领先(SOTA),展现了其在复杂推理任务上的强大能力。
- GitHub:https://github.com/inclusionAI/M2-Reasoning
- 模型:https://huggingface.co/inclusionAI/M2-Reasoning
模型亮点
- ✅ 通用推理能力领先:在数学、逻辑等抽象任务中表现出色
- ✅ 空间推理能力突破:理解物体关系、方向、运动与物理交互
- ✅ 多模态融合能力:结合视觉与语言信息,解决复杂视觉-语言任务
- ✅ 高质量数据驱动:构建 294.2K 高质量样本数据集,支持冷启动与强化学习阶段训练
- ✅ 开源可复现:训练流程与数据构建策略公开,便于研究与优化
模型概述
尽管当前多模态大语言模型(MLLM)在语言理解和视觉生成方面取得了显著进展,但在处理动态空间推理任务(如物体关系理解、空间感知、物理模拟)方面仍存在明显短板。
M2-Reasoning-7B 通过以下两大核心创新,突破了这一瓶颈:
创新一:高质量推理数据流水线
我们构建了一个多阶段数据合成与筛选系统,共生成:
- 168K 数据样本用于冷启动微调
- 126.2K 数据样本用于强化学习(RLVR)阶段
这些数据具有逻辑一致的推理轨迹,涵盖数学、逻辑、视觉问答、空间推理等多种任务,并经过全面评估,确保其质量与多样性。
创新二:动态多任务训练策略
为缓解不同任务之间的数据冲突,我们提出:
- 逐步动态优化机制:分阶段训练,逐步提升模型能力
- 任务特定奖励机制:为不同任务设计定制化激励信号,提升训练效率与模型表现
主要功能
M2-Reasoning-7B 支持以下核心功能:
- 通用推理任务:
- 解决数学问题(如代数、几何、概率)
- 执行逻辑推理(如命题逻辑、推理链)
- 空间推理任务:
- 理解物体位置、方向、运动轨迹
- 推理房间大小、物体相对距离、空间关系
- 多模态任务处理:
- 视觉问答(VQA)
- 图像描述生成
- 多模态推理与决策
工作原理
M2-Reasoning-7B 的训练流程分为以下几个关键阶段:
- 数据合成与筛选
使用自动化问题生成器和推理轨迹模拟器,构建大量逻辑一致的推理样本。 - 冷启动阶段(SFT)
使用监督微调(SFT)激活模型的基本推理能力,并统一输出格式。 - 强化学习阶段(RLVR)
使用可验证奖励的强化学习(RLVR),优化推理路径,提高泛化能力。 - 任务特定奖励机制
为不同任务设计不同的奖励函数,尤其是空间推理任务,引导模型学习更准确的推理路径。
模型评估
我们在多个权威基准测试中对 M2-Reasoning-7B 进行了全面评估,覆盖通用推理与空间推理两个核心方向。
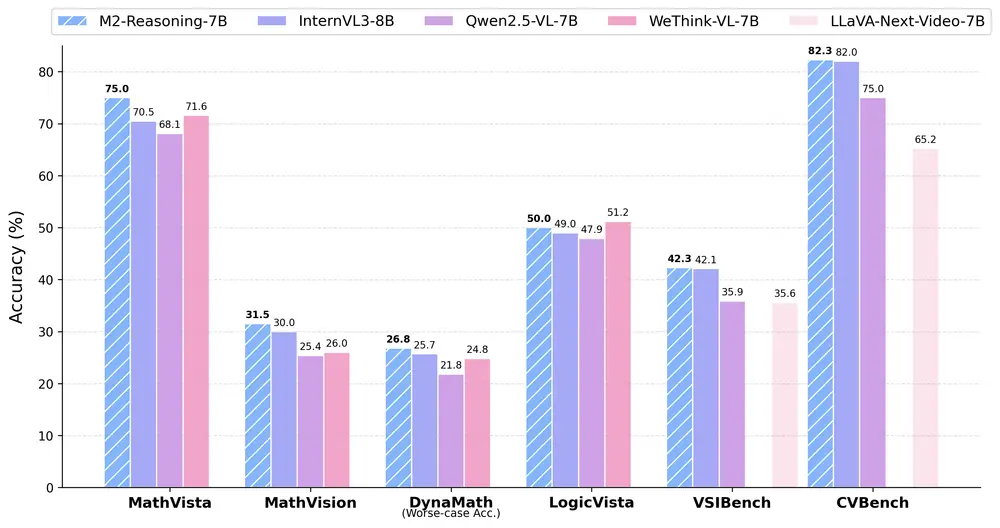
通用推理性能(数学与逻辑)
| 模型 | MathVista | MathVision | MathVerse | DynaMath | WeMath | LogicVista | 平均值 |
|---|---|---|---|---|---|---|---|
| InternVL3-8B | 70.5 | 30.0 | 38.5 | 25.7 | 39.5 | 44.5 | 41.4 |
| Qwen2.5-VL-7B | 68.1 | 25.4 | 41.1 | 21.8 | 36.2 | 47.9 | 40.1 |
| WeThink-VL-7B | 71.6 | 26.0 | 44.2 | 24.8 | 48.0 | 51.2 | 44.3 |
| M2-Reasoning-7B | 75.0 | 31.5 | 44.7 | 26.8 | 41.8 | 50.0 | 45.0 |
M2-Reasoning-7B 在所有任务上均表现优异,平均得分领先其他模型 9.5 分。
🌍 空间推理性能
CV-Bench 结果
| 模型 | 计数 | 关系 | 深度 | 距离 | 平均值 |
|---|---|---|---|---|---|
| GPT-4O | 65.9 | 85.7 | 87.8 | 78.2 | 78.9 |
| Gemini-1.5-pro | 70.4 | 85.2 | 82.4 | 72.8 | 77.4 |
| InternVL3-8B | 74.0 | 90.6 | 84.3 | 81.0 | 82.0 |
| M2-Reasoning-7B | 66.6 | 92.8 | 89.3 | 84.3 | 82.3 |
VSI-Bench 结果
| 模型 | 平均值 |
|---|---|
| Gemini-1.5-pro | 45.4 |
| InternVL3-8B | 42.1 |
| M2-Reasoning-7B | 42.3 |
M2-Reasoning-7B 在空间推理任务中表现突出,尤其在 CV-Bench 上达到 82.3 分,超越 Gemini-1.5-pro 和 InternVL3-8B。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











