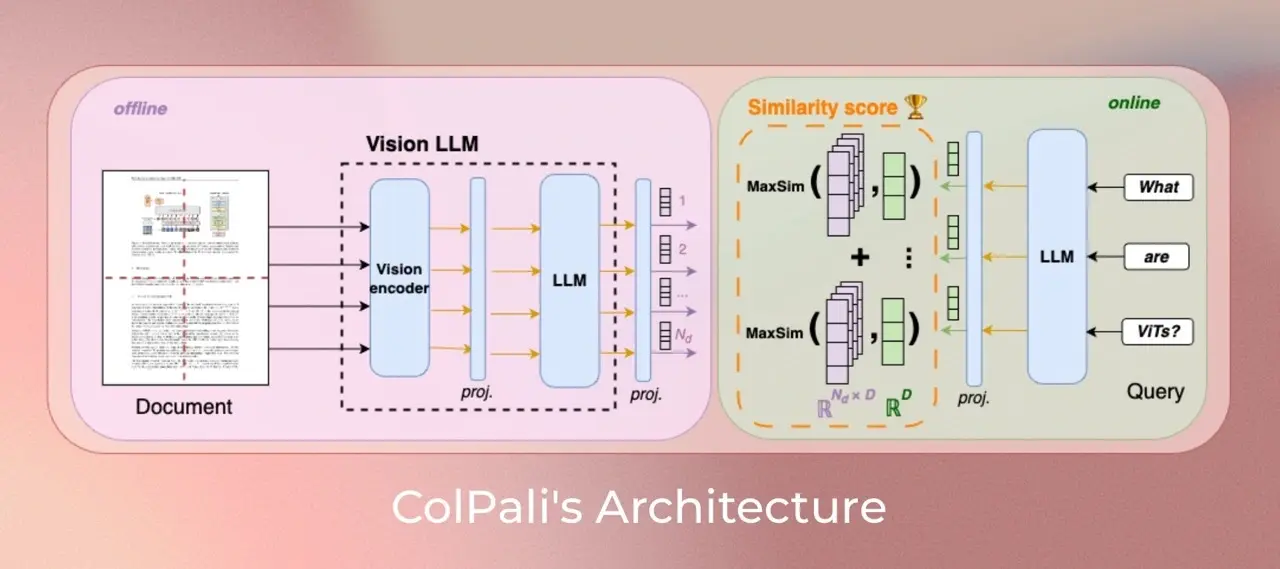
由 Illuin科技、Equall.ai、巴黎-萨克雷大学和苏黎世联邦理工学院 联合提出,ColPali 是一种基于视觉语言模型(VLMs)的文档检索模型,能够直接从文档图像中提取信息,实现快速、准确、多语言支持的文档检索。
- GitHub:https://github.com/illuin-tech/colpali
- 模型:https://huggingface.co/collections/vidore/colpali-models-673a5676abddf84949ce3180
与传统依赖OCR和布局识别的文档检索系统不同,ColPali 利用现代视觉语言模型,同时捕捉文档的视觉和文本内容(如图表、表格、排版、字体等),从而更贴近人类对文档的理解方式。
为什么需要 ColPali?
传统文档检索系统通常依赖于文本内容,例如通过关键词匹配来查找文档。然而,许多重要文档(如学术论文、商业报告、政府文件)不仅包含文字,还包含大量视觉元素,例如:
- 图表(展示实验结果、财务趋势)
- 表格(汇总关键数据)
- 图片(辅助说明)
- 排版(结构化信息)
这些元素对理解文档内容至关重要,但传统系统往往无法有效利用。ColPali 的出现,正是为了解决这一问题。
ColPali 的核心技术亮点
✅ 多向量嵌入(Multi-vector Embeddings)
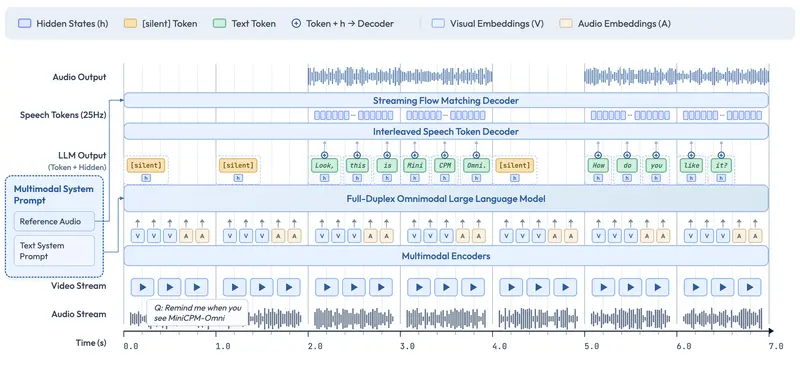
ColPali 基于 ColBERT 检索策略,将文档页面图像输入视觉语言模型(如 PaliGemma、Qwen2-VL),提取图像块(image patches),并通过线性投影生成多向量表示。这种表示方式能够:
- 同时捕捉文本内容与视觉结构
- 提高检索的细粒度匹配能力
✅ 延迟交互匹配机制(Late Interaction Matching)
在检索过程中,ColPali 使用 延迟交互机制,即在查询和文档嵌入之间进行细粒度相似度计算,从而提升匹配精度。
✅ 高效流程,无需OCR
ColPali 无需依赖OCR、PDF解析或复杂布局识别流程,仅需输入文档图像即可完成检索,大大简化了处理流程,提高了系统鲁棒性。
支持的模型列表(截至当前)
| 模型名称 | ViDoRe得分 | 许可证 | 备注 | 当前支持 |
|---|---|---|---|---|
| vidore/colpali | 81.3 | Gemma | 基于 google/paligemma-3b-mix-448,论文原始模型 | ❌ |
| vidore/colpali-v1.1 | 81.5 | Gemma | 修复查询右侧填充 | ✅ |
| vidore/colpali-v1.2 | 83.9 | Gemma | 类似 v1.1 | ✅ |
| vidore/colpali-v1.3 | 84.8 | Gemma | 更大批次训练 | ✅ |
| vidore/colqwen2-v0.1 | 87.3 | Apache 2.0 | 基于 Qwen2-VL-2B-Instruct,支持动态分辨率 | ✅ |
| vidore/colqwen2-v1.0 | 89.3 | Apache 2.0 | 更大批次训练 | ✅ |
| vidore/colqwen2.5-v0.1 | 88.8 | Apache 2.0 | 基于 Qwen2.5-VL-3B-Instruct | ✅ |
| vidore/colqwen2.5-v0.2 | 89.4 | Apache 2.0 | 微调超参数版本 | ✅ |
| vidore/colSmol-256M | 80.1 | Apache 2.0 | 基于 SmolVLM-256M-Instruct | ✅ |
| vidore/colSmol-500M | 82.3 | Apache 2.0 | 基于 SmolVLM-500M-Instruct | ✅ |
主要功能与特点
🚀 高效性
- 无需OCR或PDF解析:直接处理文档图像,流程更简单
- 检索速度快:在线查询延迟仅为 30ms,与传统模型相当但性能更优
🔍 高准确性
- 融合视觉与文本信息:支持图表、表格等视觉元素检索
- 多向量表示 + 延迟交互机制:显著提升匹配精度
🌍 多语言支持
- 模型在法语等非英语文档上也表现优异
- 可用于跨语言文档检索任务
🔧 可扩展性强
- 支持大规模文档集合
- 可结合向量数据库(如 FAISS)进行高效索引
- 可通过硬件加速与压缩技术进一步优化性能
工作原理简述
ColPali 的工作流程主要包括以下几个步骤:
- 图像嵌入生成
使用视觉语言模型(如 Qwen2-VL)从文档图像中提取图像块,并生成多向量嵌入。 - 查询嵌入匹配
用户输入查询文本,模型生成对应的查询嵌入。 - 延迟交互计算
在查询与文档嵌入之间进行细粒度相似度计算,提升匹配精度。 - 高效检索
利用向量相似度计算与索引技术,在大规模文档集合中快速定位匹配文档。
测试结果与性能表现
在多个基准测试中,ColPali 展现出显著优势:
- ViDoRe基准得分:最高达 89.4
- nDCG@5 平均值:达到 81.3
- 在线查询延迟:仅 30ms
- 多语言表现:在法语文档检索中同样表现优异
与基于 BM25 的文本检索、基于 SigLIP 的视觉检索方法相比,ColPali 在准确性和效率上均有显著提升。
应用场景
ColPali 可广泛应用于以下场景:
- 📚 学术论文检索:支持图表、公式、排版等复杂结构检索
- 💼 商业报告分析:从大量文档中快速定位关键数据图表
- 📄 政府文件管理:高效检索含图像与表格的政策文件
- 📊 企业知识库构建:无需OCR即可构建多模态文档索引
- 🌐 跨语言信息检索:支持多语言文档的统一检索系统
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











