
ColQwen2.5-Omni 是基于 Qwen2.5-Omni-3B-Instruct 的新一代多模态检索模型。该模型采用 ColBERT 策略,支持从图像、音频等多模态内容中高效检索信息,是目前首个将 ColBERT 检索范式扩展至音频模态的开源模型。
项目亮点
- ✅ 多模态支持:支持图像、音频、文本混合检索
- ✅ ColBERT 索引策略:生成多向量表示,提升召回精度
- ✅ 动态分辨率处理:无需缩放图像,保留原始比例
- ✅ 零样本音频检索能力:无需音频训练数据,仍可实现音频内容检索
- ✅ 高性能检索器:适配ColPali范式,检索效率高
模型概述
ColQwen2.5-Omni 是 ColQwen 系列的最新演进版本,基于 Qwen2.5-Omni-3B-Instruct 构建,扩展了其在视觉与音频模态上的检索能力。它继承了 ColPali 的核心思想:将文档页面视为图像进行索引,从而跳过OCR等传统流程,直接通过视觉语言模型(VLM)生成向量表示。
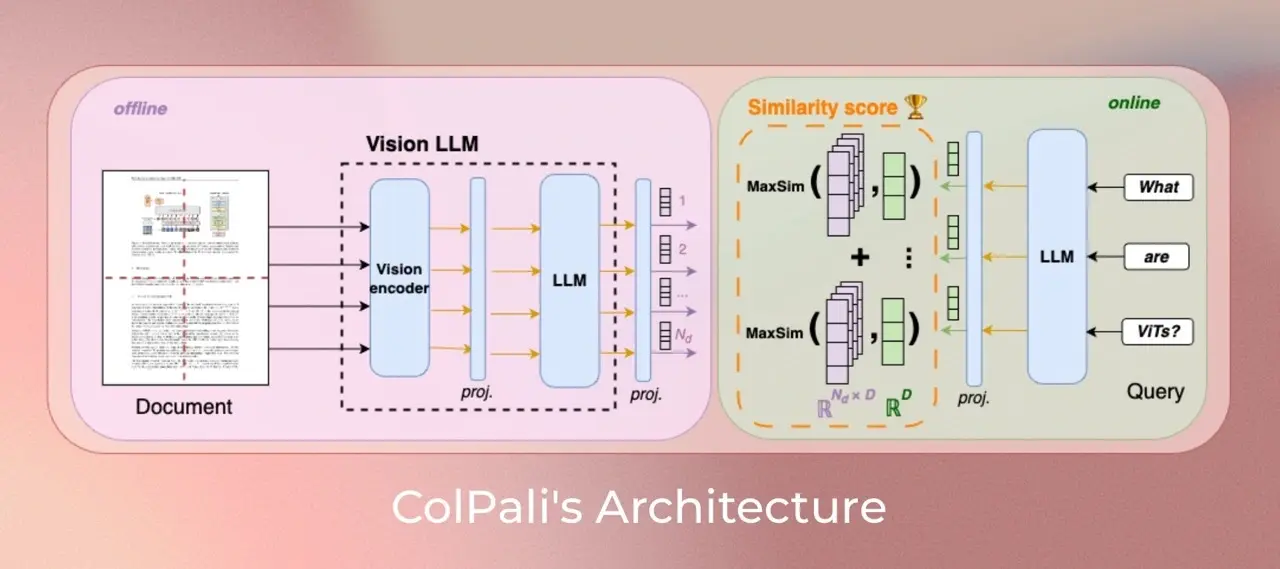
此次发布的版本不仅支持图像检索,还首次引入了对音频内容的零样本检索能力,为构建统一的多模态检索系统提供了新思路。
模型特性
支持动态图像分辨率输入
与 ColPali 一致,ColQwen2.5-Omni 支持动态图像分辨率输入,不进行图像缩放或裁剪,保持原始纵横比。图像最大分辨率支持生成最多 1024个图像块(patch),实验表明增加图像块数量可显著提升检索性能,但会带来更高的内存需求。
零样本音频检索能力
尽管训练数据仅包含图像-文本对,模型在未接触任何音频训练数据的情况下,仍具备对音频内容的检索能力。这一能力源于 Qwen2.5-Omni 模型本身具备的多模态理解能力,展示了其强大的泛化潜力。
训练策略与架构
- 使用 colpali-engine==0.3.11 进行训练
- 模型结构基于 Qwen2.5-Omni-3B-Instruct,扩展其多向量生成能力
- 使用 ColBERT 风格的多向量表示策略,提升检索精度
- 训练期间,音频和视觉塔冻结,仅微调语言模型部分
训练数据说明
本模型的训练数据集包含 127,460个查询-页面对,由以下两部分组成:
- 公开学术数据集(63%):涵盖多种文档结构和内容
- 合成数据集(37%):由网络爬取的PDF文档页面构成,通过 Claude-3 Sonnet 生成伪问题进行增强
训练集设计为全英文,以评估模型对非英语语言的零样本泛化能力。验证集占2%,用于调整超参数。训练过程中确保没有多页PDF文档同时出现在训练集和评估集(ViDoRe)中,避免数据泄露。
注意:尽管训练数据为英文,语言模型的预训练语料中可能包含多语言内容,因此模型在非英文场景中仍具备一定检索能力。
技术背景与演进
还记得 ColPali、ColQwen、DSE 吗?这些模型首次提出了视觉文档检索(Visual Document Retrieval)的新范式:不再依赖OCR提取文本,而是将文档页面直接作为图像输入,通过视觉语言模型(VLM)生成向量表示。
ColPali 证明了这种方法不仅更简单、更快,而且在检索性能上也优于传统方法。自发布以来,ColPali 和 ColQwen 系列已被下载数百万次,被誉为 2024年最具影响力的人工智能创新之一,并激发了大量后续研究。
如今,随着 Qwen-Omni 系列模型对音频、视频等模态的支持增强,我们开始思考:是否可以将 ColQwen 系列扩展到更多模态?VisionRAG 之后,AudioRAG 是否也可能实现?
ColQwen2.5-Omni 正是这一探索的成果。它不仅支持图像检索,还具备对音频内容的检索能力,真正实现了“嵌入你输入的任何内容”。
应用前景
ColQwen2.5-Omni 的发布为构建统一的多模态检索系统打开了新大门,适用于以下场景:
- 📚 文档检索:无需OCR,直接从PDF截图中检索信息
- 🎥 视频片段检索:结合视觉与文本提示,快速定位视频内容
- 🎧 音频内容检索:实现对语音、音乐、环境音等的语义检索
- 📈 多模态RAG系统:为RAG系统提供统一的向量表示接口
- 🧠 跨模态搜索:支持图像查文本、文本查音频、音频查视频等多组合检索
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











