
你是否曾希望有一个 AI 助手,能像你一样操作电脑——打开浏览器查资料、在 Excel 中整理数据、切换应用完成多步骤任务?如今,这类被称为“计算机使用智能体”(Computer Use Agents, CUA)的系统正逐步成为现实。
然而,尽管部分商业产品已展示出强大能力,其核心技术细节却普遍闭源。这不仅限制了学术研究,也带来了透明度、安全性与公平评估的隐患。
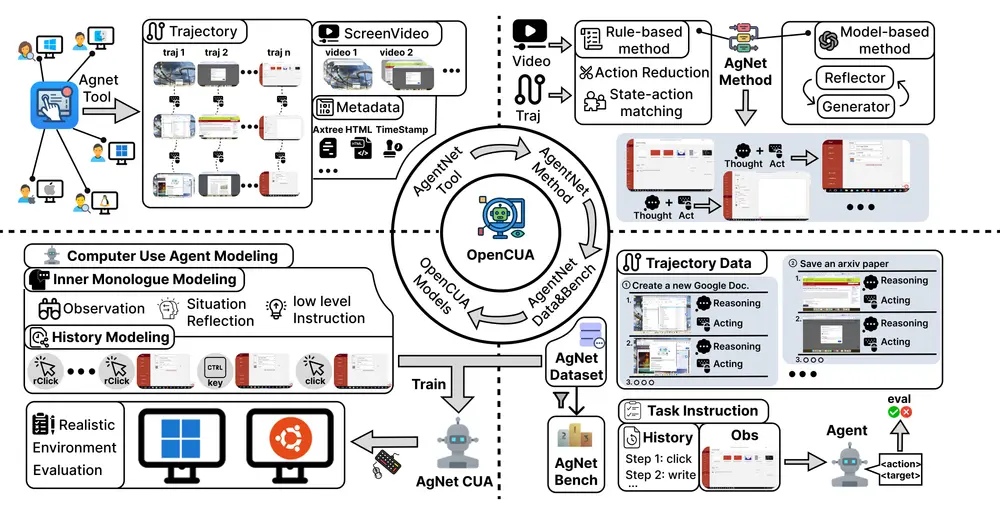
为打破这一壁垒,香港大学 XLANG 实验室、月之暗面、斯坦福大学、滑铁卢大学与卡内基梅隆大学联合推出 OpenCUA ——一个全面开源的计算机使用智能体框架。
- 项目主页:https://opencua.xlang.ai
- GitHub:https://github.com/xlang-ai/OpenCUA
- 模型:https://huggingface.co/collections/xlangai/opencua-open-foundations-for-computer-use-agents-6882014ebecdbbe46074a68d
- Demo:https://huggingface.co/spaces/xlangai/OpenCUA-demo
它包含从数据采集、标注、处理到模型训练的完整链条,旨在为研究社区提供可复现、可扩展、可审计的 CUA 基础设施。
为什么需要开源的 CUA 框架?
当前最先进的 CUA 系统多由大公司开发,其能力令人印象深刻,但存在三大问题:
- 黑箱化严重:缺乏公开数据与训练方法,难以分析其真实能力边界;
- 评估不统一:不同系统在不同环境测试,无法横向比较;
- 泛化能力存疑:多数系统仅在特定应用或操作系统中验证,难以判断跨平台适应性。
随着 CUA 开始介入金融操作、办公自动化、个人数据管理等敏感场景,我们不能再依赖“能力强大但不可见”的系统。
OpenCUA 的目标正是构建一个开放、透明、可验证的研究生态。
OpenCUA 框架三大核心组件
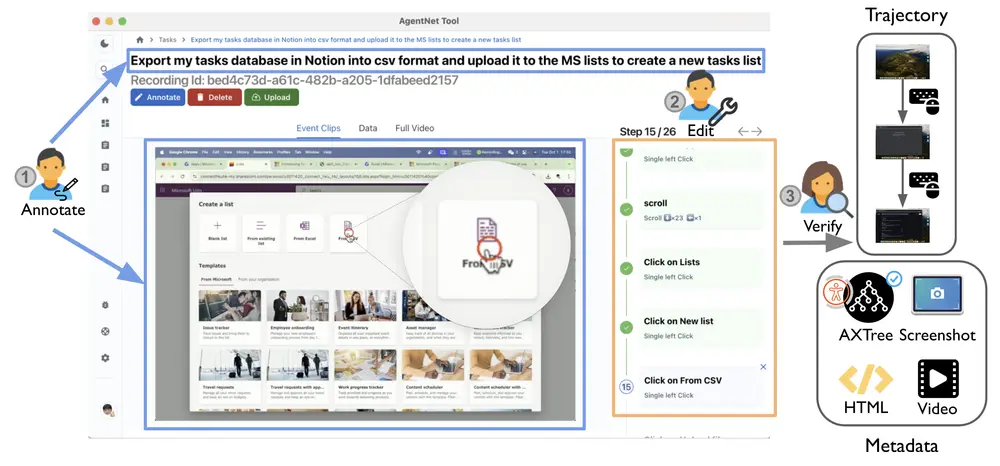
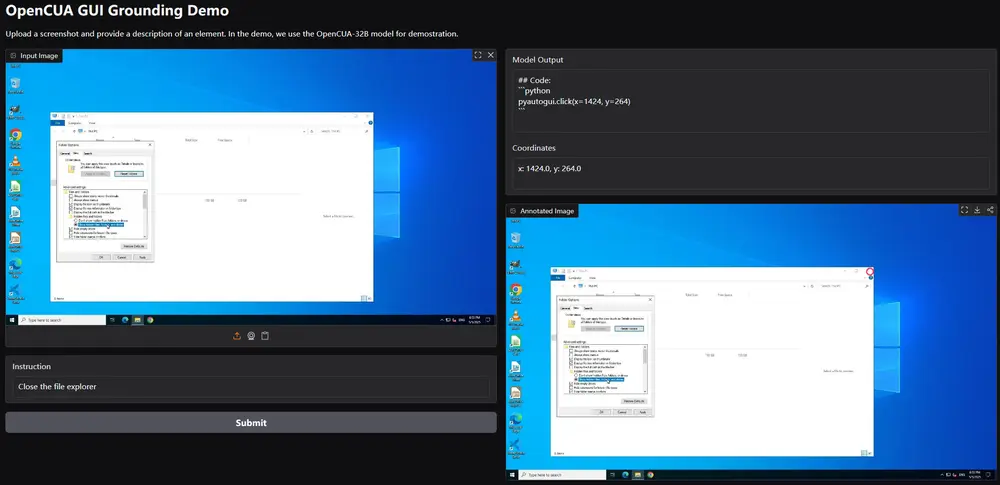
1. AgentNetTool:跨平台标注工具
要训练能操作电脑的 AI,首先需要高质量的人类操作数据。
为此,团队开发了 AgentNetTool ——一款轻量级、跨平台的标注应用,支持 Windows、macOS 和 Ubuntu:
- 自动录制屏幕视频;
- 捕获鼠标/键盘事件;
- 提取无障碍树(Axtree)结构,便于模型理解界面语义;
- 支持后台运行,不影响用户正常工作。
该工具使非技术用户也能自然地完成任务演示,极大提升了数据采集效率与真实性。
2. AgentNet:大规模真实任务数据集
基于 AgentNetTool,团队构建了 AgentNet ——目前最大规模的计算机使用任务数据集:
| 指标 | 数据 |
|---|---|
| 任务数量 | 22.5K |
| 操作系统 | Windows (12K), macOS (5K), Ubuntu (5K) |
| 覆盖应用 | 140+ 桌面应用(如 Word、Photoshop) |
| 覆盖网站 | 190+ 网站(如 Gmail、Notion、GitHub) |
这些任务高度真实,常见于日常办公、学习与开发场景,例如:
- “在 Google Docs 中插入表格并共享给同事”
- “使用 VS Code 打开项目,查找并修改某函数”
- “在 macOS 上设置定时提醒,并同步到 iPhone”
与以往 GUI 数据集不同,AgentNet 提供的是完整的状态-动作轨迹,而非孤立截图或指令。
3. 反思性长链思考(Reflective Chain-of-Thought)流水线
原始操作记录是“怎么做”,但模型需要知道“为什么这么做”。
为此,团队设计了一套自动化流水线,将原始轨迹转化为包含推理过程的训练样本:
- 对每一步操作生成“内心独白”式思考(如“当前页面没有搜索框,应切换到顶部导航栏”);
- 引入“生成器-反思器”机制:先生成推理,再由另一模型验证其合理性;
- 迭代优化,确保推理与动作一致。
这种方式显著提升了模型在复杂任务中的规划能力。
AgentNetBench:离线评估新标准
传统 CUA 评估依赖真实环境执行,耗时且不稳定。
为此,团队提出 AgentNetBench ——一个离线评估基准,包含从 AgentNet 中精选的 100 个代表性任务,特点包括:
- 每个任务提供清晰目标与上下文;
- 每步操作标注多个合法动作选项(因 GUI 操作常有多解);
- 支持快速、可复现的模型打分,无需实际运行软件。
这为公平比较不同模型提供了统一平台。
OpenCUA 模型:开源也能达到 SOTA
团队在多个视觉-语言模型基础上进行监督微调(SFT),推出系列 OpenCUA 模型:
- OpenCUA-A3B
- OpenCUA-Qwen2-7B
- OpenCUA-7B
- OpenCUA-32B
其中,OpenCUA-32B 在 OSWorld-Verified 基准测试中表现尤为突出:
| 指标 | OpenCUA-32B |
|---|---|
| 平均成功率 | 34.8% |
| 开源模型排名 | 第一(SOTA) |
| 对比 GPT-4o | 超越 OpenAI CUA |
这是首个在主流 CUA 基准上超越闭源系统的开源模型。
此外,OpenCUA-7B 在测试时通过增加推理路径(Pass@N)即可显著提升性能,显示出强大的扩展潜力。
泛化能力与测试时计算优势
研究还发现:
- 模型在未见应用和跨操作系统任务中表现稳定,具备良好泛化性;
- 随着训练数据规模增加,性能持续提升,验证了数据驱动的有效性;
- 在测试阶段引入更多候选路径(test-time scaling),可进一步提升成功率,说明模型具备“深思熟虑”的能力。
与 OSWorld-Verified 的关系
OpenCUA 使用 OSWorld-Verified 作为主要评估基准。该基准由 OSWorld 团队对原始 OSWorld 任务进行全面审查与修复,解决了过时依赖、评估错误和指令模糊等问题,是当前最可靠的 CUA 测试环境之一。
团队在此特别致谢 OSWorld 团队的工程贡献。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











