阿里通义实验室推出多模态深度研究智能体WebWatcher,通过结合视觉和语言推理能力,解决复杂的多模态信息检索问题。
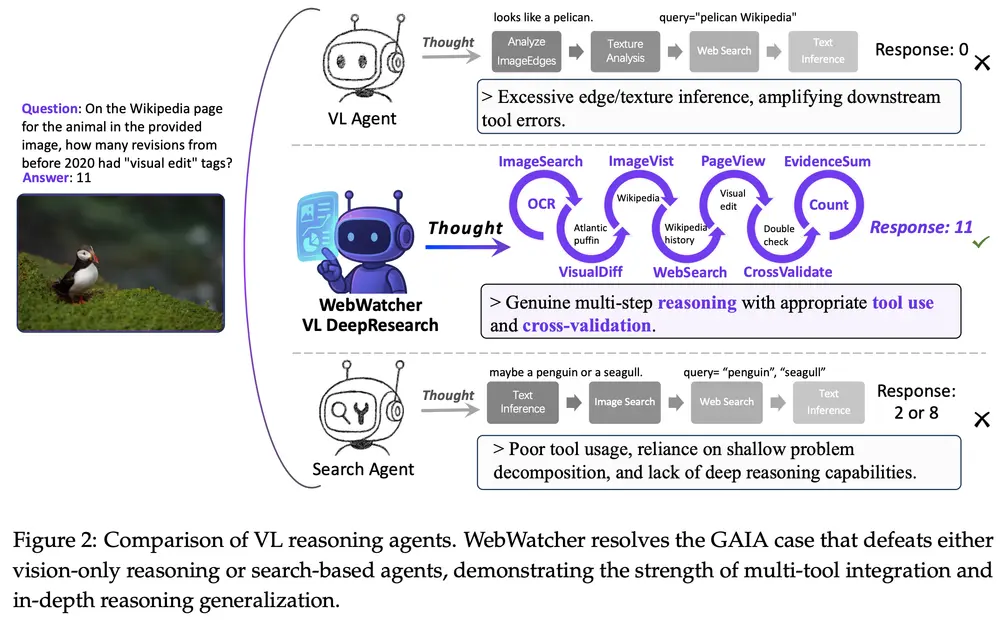
WebWatcher 具备强大的视觉和语言推理能力,能够解决高度复杂的视觉-语言(Vision-Language,VL)任务。例如,它可以处理科学图表分析、图形分析以及视觉丰富的网页界面导航等任务。这些任务不仅需要视觉感知能力,还需要跨模态推理和复杂的逻辑推理能力。

主要功能
- 多模态推理:WebWatcher 能够处理包含视觉和文本信息的任务,例如从图像中提取信息并结合文本内容进行推理。
- 工具使用:它能够调用多种外部工具,如网页搜索、图像搜索、网页浏览、代码解释器和内部OCR工具,以增强其推理能力。
- 复杂任务解决:WebWatcher 能够解决需要多步推理和规划的复杂任务,例如在多页面网页浏览中进行信息检索和视觉定位。
主要特点
- 多模态数据生成:通过将复杂的文本问答转换为视觉问答(VQA)任务,WebWatcher 生成了高质量的多模态训练数据。
- 自动化轨迹生成:WebWatcher 使用自动化管道生成推理轨迹,这些轨迹基于实际工具使用行为,反映了复杂的推理需求。
- 强化学习优化:通过强化学习算法(如GRPO)进一步优化模型的决策过程,提高工具使用效率和推理能力。
工作原理
- 数据生成:首先从权威知识源(如arXiv、GitHub和Wikipedia)收集多跳推理和知识密集型问题,然后通过随机游走生成复杂的问答对。接着,将这些文本问答对转换为视觉问答任务,通过图像检索和实体掩码技术增强视觉上下文。
- 轨迹生成:使用GPT-4o自动生成工具使用轨迹,这些轨迹模拟了人类在解决问题时的逐步推理过程。通过多阶段过滤确保轨迹的质量和清晰度。
- 模型训练:使用监督微调(SFT)作为冷启动,教授智能体工具增强推理。然后通过强化学习(如GRPO)进一步优化决策过程。
测试结果
- 基准测试:WebWatcher 在多个基准测试中表现出色,包括 BrowseComp-VL、Humanity's Last Exam (HLE-VL)、LiveVQA、SimpleVQA 和 MMSearch。
- 性能提升:WebWatcher-32B 在 HLE-VL 上达到了18.2%的平均准确率,显著超过了现有的开源多模态研究智能体和专有系统。在 BrowseComp-VL 上,WebWatcher-32B 的准确率达到了28.4%,在 LiveVQA 上达到了58.7%,在 MMSearch 上达到了55.3%。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











