在人机交互日益复杂的今天,一个长期被忽视的问题是:
我们能让AI像人类一样“使用”计算机吗?
不是生成文本或识别图像,而是真正理解屏幕上的按钮、输入框、菜单,并通过点击、滑动、输入等动作完成任务——这正是 图形用户界面(GUI)自动化 的核心挑战。
Hugging Face 最近提出 Smol2Operator ——一套基于小型视觉-语言模型(VLM)的完整训练框架,将原本不具备 GUI 感知能力的模型,逐步训练成能够观察并操作桌面、移动端和网页界面的智能代理。
- GitHub:https://github.com/huggingface/smol2operator
- 模型:https://huggingface.co/collections/smolagents/smol2operator-release-68d288e87d3fa8f551d2ce2e
该项目不追求“SOTA性能”,而是聚焦于展示一条从数据处理到模型训练的完整技术路径,揭示如何系统性地为 VLM 注入 GUI grounding 能力。
其意义在于:
不再依赖大模型黑箱能力,而是构建可复现、可扩展、可定制的 GUI 智能体训练流程。
为什么GUI自动化如此困难?
GUI 自动化不同于传统任务,它要求模型具备多重能力:
- 感知能力:识别界面上的元素(按钮、文本框、图标)
- 定位能力:准确理解元素的位置与布局
- 语义理解:知道“搜索框”是用来输入关键词的
- 动作推理:决定下一步应执行“点击”还是“输入”
- 跨平台泛化:适应不同分辨率、操作系统和应用风格
而现有视觉-语言模型大多缺乏对 UI 元素的结构化理解,无法将“视觉区域”与“可执行动作”建立映射。
Smol2Operator 的目标,就是解决这一断层。
基础模型选择:SmolVLM2-2.2B-Instruct
项目选用 SmolVLM2-2.2B-Instruct 作为基础模型,原因明确:
- 参数量仅 22亿,轻量高效,适合边缘部署
- 初始状态下不具备任何GUI相关先验知识
- 支持多模态输入(图像 + 文本),具备基本推理能力
这个“白板”特性使其成为理想的实验对象——最终的能力提升,完全归功于训练策略本身,而非预训练偏见。
方法概览:两阶段训练,分步注入能力
Smol2Operator 采用 两阶段训练策略,逐步赋予模型 GUI 操作能力:
第一阶段:注入 Grounding 能力(感知与定位)
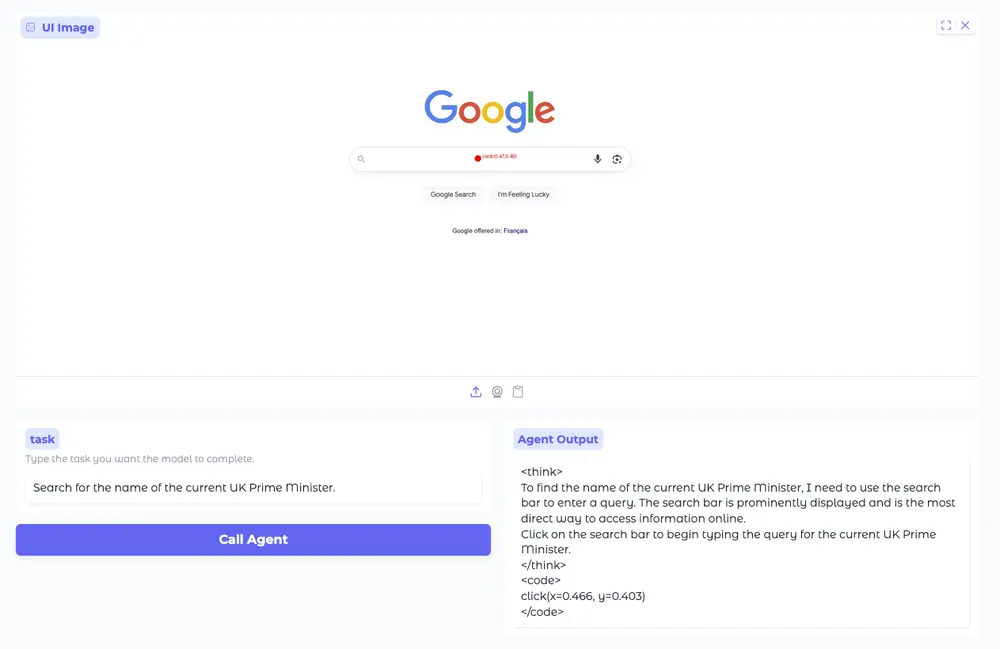
目标:让模型学会将自然语言指令与屏幕上具体区域关联起来。
- 输入:截图 + 指令(如“点击登录按钮”)
- 输出:标准化动作函数调用(如
click(x=0.45, y=0.78))
通过监督学习,模型掌握“哪里该点”“哪个区域对应什么功能”。
第二阶段:增强智能推理能力(决策与规划)
目标:使模型能处理更复杂任务,如多步操作、条件判断。
- 使用高质量 SFT(监督微调)数据
- 包含上下文记忆、错误恢复、状态追踪等高级行为
- 提升模型在真实场景中的鲁棒性与连贯性
这种分阶段设计避免了能力混淆,确保每一步训练都有明确目标。
关键创新:统一动作空间与归一化坐标
要训练通用 GUI 智能体,必须解决一个根本问题:
不同数据集的动作表示五花八门,难以合并训练。
例如:
tap(x=302, y=63)
click(element_id=12)
press("Search")
这些看似相似的操作,实则格式混乱、语义模糊。
为此,团队构建了一套完整的 数据转换流水线,实现三大统一:
1. 动作空间标准化
所有操作被映射为一组标准化函数,例如:
| 原始动作 | 统一后 |
|---|---|
| tap(x=302,y=63) | click(x=0.45,y=0.78) |
| type("hello") | input(text="hello") |
| swipe(left) | swipe(direction="left") |
并通过 preprocessing/action_conversion.py 实现自动转换。
2. 归一化坐标系统
不再使用原始像素值(易受分辨率影响),而是将所有坐标归一化到 [0,1] 区间:
x_norm = x_pixel / image_widthy_norm = y_pixel / image_height
这一改动使得模型输出与图像尺寸解耦,极大提升了跨设备泛化能力。
3. 灵活适配框架
提供工具 utils/action_space_converter.py,允许用户:
- 将标准动作空间转换为自己系统的 API 格式
- 分析现有数据集的动作分布
- 自定义函数签名与参数命名
真正实现“一次训练,多端适配”。
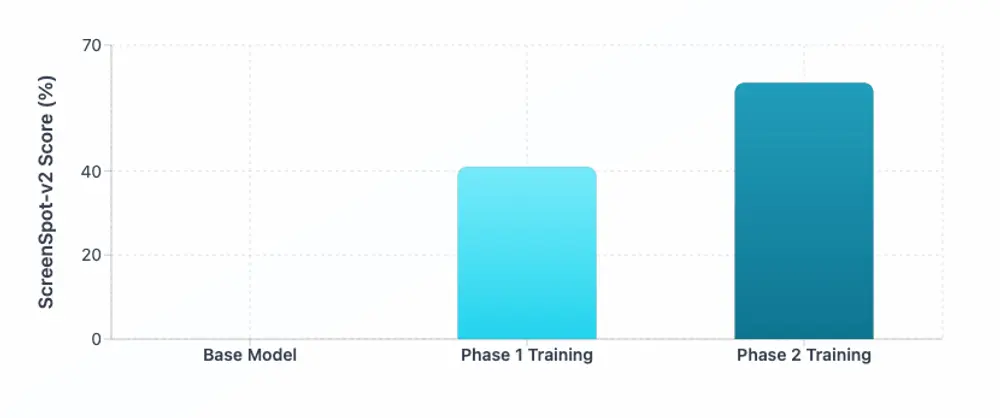
评估结果:在ScreenSpot-v2上验证grounding能力
项目在公认的 GUI 感知基准 ScreenSpot-v2 上进行评估,该任务要求模型根据指令精确定位界面上的目标元素。
结果显示,经过两阶段训练的 Smol2Operator 显著优于基线模型,在定位准确性与动作匹配度上均有明显提升。
更重要的是,模型展现出良好的零样本迁移能力,能在未见过的应用界面上做出合理推断。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











