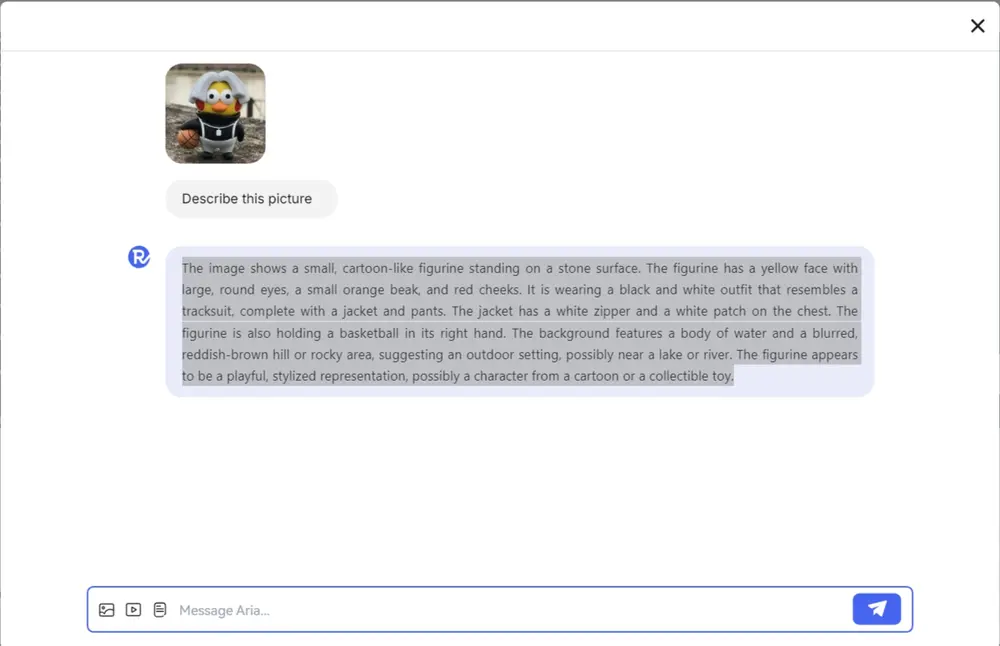
通义实验室正式推出 Qwen3-Omni——一款统一处理多模态输入并支持流式文本与语音输出的大语言模型。该模型已在 Qwen API 平台上线,开发者可通过接口体验其在音频对话、跨模态理解与指令执行方面的综合能力。
- GitHub:https://github.com/QwenLM/Qwen3-Omni
- API:https://help.aliyun.com/zh/model-studio/qwen-omni
- Hugging Face:https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
- 魔塔:https://modelscope.cn/collections/Qwen3-Omni-867aef131e7d4f
- Demo:https://modelscope.cn/studios/Qwen/Qwen3-Omni-Demo
Qwen3-Omni 的设计目标是构建一个真正端到端的多模态交互系统,不仅支持多种输入形式(文本、图像、音频、视频),还能以极低延迟生成自然语音和结构化文本响应,适用于智能助手、实时客服、教育辅助等复杂场景。

核心能力概览
| 能力 | 说明 |
|---|---|
| ✅ 多模态输入 | 支持文本、图像、音频、视频任意组合输入 |
| ✅ 双通道输出 | 实时生成文本 + 自然语音(流式) |
| ✅ 多语言支持 | 文本交互支持 119 种语言;语音理解支持 19 种语言;语音生成支持 10 种语言 |
| ✅ 高效响应 | 纯模型端到端延迟: • 音频对话:211ms • 视频对话:507ms |
| ✅ 长上下文音频理解 | 支持最长 30 分钟连续音频输入解析 |
| ✅ 工具调用 | 支持 function call,可集成外部服务或数据库查询 |
| ✅ 可定制化 | 支持通过 system prompt 调整回复风格、角色设定等行为特征 |
这一组合使其成为目前少数能实现“听-看-想-说”闭环的开源级多模态模型之一。
模型架构:Thinker-Talker 设计
Qwen3-Omni 采用创新的 Thinker-Talker 架构,将认知与表达解耦,提升效率与可控性:

1. Thinker(思考模块)
- 基于 MoE 架构,负责多模态信息融合与文本推理;
- 接收来自视觉编码器、音频编码器和文本嵌入的信息;
- 输出高层语义表征,作为 Talker 的输入。
2. Talker(表达模块)
- 同样基于 MoE 架构,专注于流式语音生成;
- 使用自回归方式预测多码本序列(multi-codebook autoregressive generation);
- 每步解码中,MTP 模块输出当前帧的残差码本,交由 Code2Wav 合成波形;
- 实现逐帧流式输出,首帧延迟极低。
该架构实现了从语义理解到语音合成的无缝衔接,无需后处理或额外TTS模型介入。
关键技术组件
AuT 音频编码器
- 基于 2000万小时 多样化音频数据训练;
- 具备强大的通用音频表征能力,涵盖语音、环境音、音乐等多种类型;
- 在 ASR、音频分类、说话人识别等任务中表现优异。
MoE 架构支撑高并发
- Thinker 与 Talker 均采用混合专家(MoE)结构;
- 动态激活部分参数,兼顾推理速度与模型容量;
- 适合大规模部署和服务扩展。
多码本流式生成
- Talker 每步生成一个编解码帧,同步输出剩余残差码本;
- 结合 Code2Wav 技术,直接合成高质量语音波形;
- 支持真正的端到端流式生成,而非“先出文本再转语音”。
训练策略:全模态协同优化
传统多模态模型常采用“单模态预训练 + 跨模态微调”的分阶段方式,易导致模态间能力失衡。Qwen3-Omni 则在早期预训练阶段即引入:
- 单模态任务(如纯文本生成、纯音频识别)
- 跨模态任务(如图文匹配、音文翻译)
通过合理配比,使各模态能力在训练过程中协同发展,避免因跨模态融合而导致某一模态性能下降。
性能表现:多项指标达到领先水平
在全面评估中,Qwen3-Omni 展现出强劲的综合能力:
| 类别 | 表现 |
|---|---|
| 音视频基准测试 | 在 36 项测试中,32 项取得开源模型最优成绩,其中 22 项达到整体 SOTA |
| 语音识别与理解 | 性能与 Gemini 2.5 Pro 相当,在噪声环境下仍保持高准确率 |
| 指令跟随能力 | 在复杂多轮对话中能准确理解意图并执行动作 |
| 图像与文本任务 | 与同尺寸 Qwen 单模态模型持平,未因多模态集成而牺牲基础能力 |
尤其在需要实时响应的语音交互任务中,其低延迟与高稳定性优于多数闭源方案。


开源发布:Qwen3-Omni-30B-A3B-Captioner
为推动社区发展,团队同步开源了 Qwen3-Omni-30B-A3B-Captioner——一个专注于音频描述生成的子模型。
特点包括:
- 低幻觉:生成内容忠实于原始音频;
- 细节丰富:可捕捉语气、背景音、情绪变化;
- 通用性强:适用于会议记录、播客摘要、无障碍字幕等场景。
未来方向
团队表示将持续优化以下方向:
- 多说话人语音识别(Diarization)
- 视频中的 OCR 与动态文字理解
- 音视频主动学习机制
- 更强的 Agent 工作流支持与函数调用能力
这些升级将进一步提升模型在真实复杂环境下的实用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











