
由百度 AI 云团队研发,Qianfan-VL 是一系列参数规模从 3B 到 70B 的多模态大语言模型(MLLM),专注于提升企业在文档理解、OCR识别和数学推理等高频场景下的自动化能力。
- 项目主页:https://baidubce.github.io/Qianfan-VL
- GitHub:https://github.com/baidubce/Qianfan-VL
- HuggingFace:https://huggingface.co/collections/baidu/qianfan-vl-68d0b9b0be8575c17267c85c
- ModelScope:https://modelscope.cn/organization/baidu-qianfan
该系列通过创新的四阶段训练策略,在保持通用多模态理解能力的同时,显著增强了特定领域的表现力。目前,Qianfan-VL 已在多个权威基准测试中达到领先水平,并支持从端侧到云端的多样化部署。
为什么需要产业级多模态模型?
当前主流多模态模型多以通用能力为导向,但在真实企业场景中,往往面临以下挑战:
- 文档版面复杂(如表格嵌套、公式混排),传统OCR难以准确解析;
- 手写体、低质量图像导致文本识别率下降;
- 数学题或图表题需结合视觉与逻辑推理,普通模型易出错。
Qianfan-VL 的设计目标正是解决这些问题——它不是“全能型选手”,而是在关键业务场景上深度优化的专业工具。
核心能力概览
✅ 多尺寸覆盖,适配不同部署环境
| 模型 | 参数量 | 上下文长度 | 支持思维链 | 适用场景 |
|---|---|---|---|---|
| Qianfan-VL-3B | 3B | 32k | ❌ | 端侧实时OCR、轻量级交互 |
| Qianfan-VL-8B | 8B | 32k | ✅ | 服务端通用任务、微调定制 |
| Qianfan-VL-70B | 70B | 32k | ✅ | 复杂推理、离线数据合成 |
三种规格满足从移动端设备到大规模服务器集群的不同需求,所有模型均已开源,可通过 HuggingFace 或 ModelScope 下载使用。
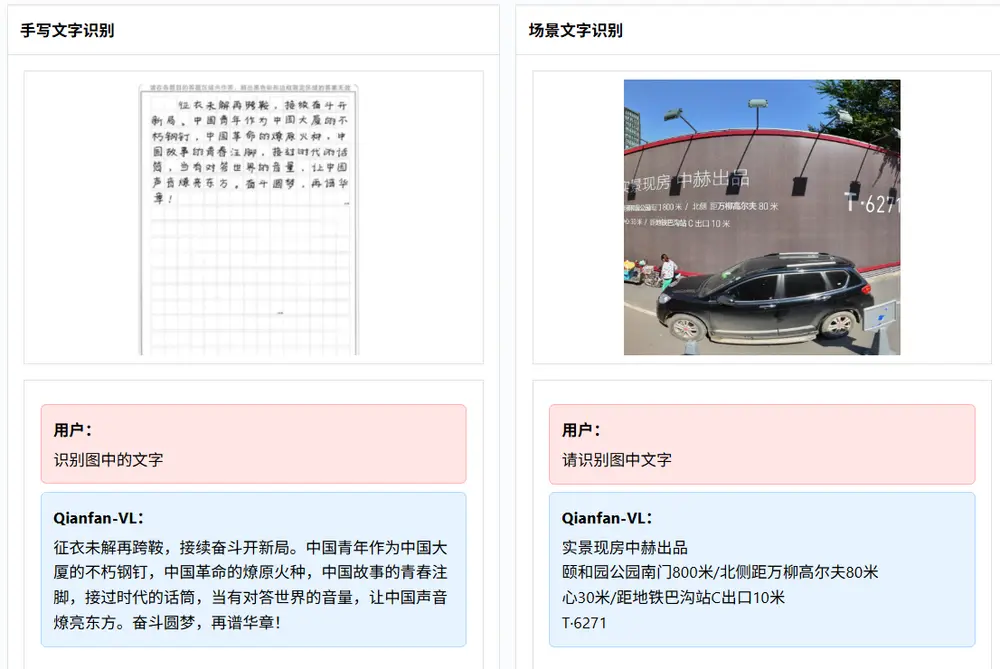
✅ OCR 与文档理解增强
针对企业文档处理中的典型痛点,Qianfan-VL 提供全栈式支持:
- 文字识别:支持印刷体、手写体、自然场景文字、数学公式等多种形式;
- 版面分析:可精准解析复杂表格结构、图表标题、段落层级;
- 结构化输出:将非结构化文档转化为 JSON 或 Markdown 格式,便于下游系统接入;
- 多语言兼容:中英文混合文档处理能力强,适用于跨国业务场景。
✅ 思维链推理能力(Chain-of-Thought)
8B 和 70B 版本支持长链推理,在涉及多步计算或逻辑推导的任务中表现优异,例如:
- 拍照解题:输入一张数学试卷图片,模型逐步推导并给出答案;
- 自动判题:判断学生解题过程是否合理,指出错误步骤;
- 图表分析:结合柱状图与问题描述,进行趋势预测与归因分析。
这一能力使其在教育辅助、金融报告解读等领域具备实际落地潜力。
技术实现路径
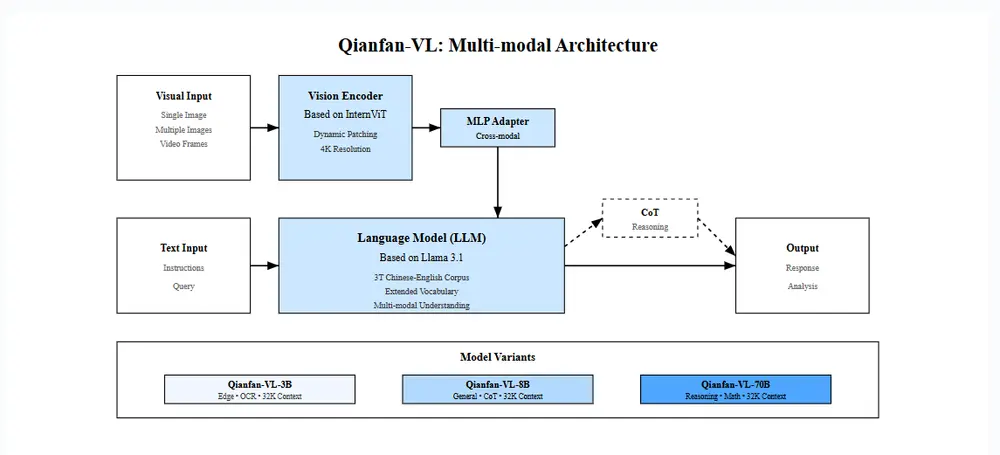
1. 模型架构设计
Qianfan-VL 采用模块化架构:
- 视觉编码器:基于 InternViT,提取图像特征;
- 语言模型:主干使用 Llama 3.1 或 Qwen2.5 架构;
- 跨模态连接:通过 MLP 适配器对齐视觉与文本空间。
该设计兼顾性能与灵活性,便于后续扩展。
2. 四阶段渐进式训练
为平衡通用性与专业性,团队提出分阶段训练流程:
| 阶段 | 目标 |
|---|---|
| ① 跨模态对齐 | 使用图像-标题对、VQA 数据建立基础视觉语言关联 |
| ② 通用知识注入 | 引入大规模开放数据集,提升常识与科学理解能力 |
| ③ 域增强预训练 | 针对文档、数学、图表等任务注入领域知识 |
| ④ 指令微调 | 训练模型遵循复杂指令,提升可控性与响应质量 |
各阶段数据配比经过精细调优,确保专项能力提升不牺牲通用能力。
3. 高质量合成数据构建
真实标注数据成本高且覆盖有限。为此,团队构建了一套多任务数据合成管线,覆盖:
- 文档 OCR(含模糊、倾斜、遮挡模拟)
- 数学题目生成(代数、几何、应用题)
- 表格重建与语义还原
- 公式识别与 LaTeX 对齐
- 图表问答(折线图、饼图、热力图)
合成方法结合传统 CV 模型(如 PaddleOCR)与程序化生成逻辑,中间过程可追溯,保证数据一致性与多样性。
4. 昆仑芯大规模训练基础设施
全部模型均在百度自研 昆仑芯 P800 芯片上完成训练,依托超 5000 张加速卡组成的分布式系统,采用:
- 3D 并行策略(数据 + 张量 + 流水线并行)
- 通信-计算融合技术
实现超过 90% 的集群扩展效率,高效处理 3T tokens 的训练数据总量,验证了国产 AI 硬件在大模型时代的支撑能力。
性能表现:关键指标对标领先
1. 通用多模态理解能力
在 ScienceQA、A-Bench、SEEDBench 等综合评测中,Qianfan-VL-70B 表现稳定居前:
| 基准测试 | Qianfan-VL-70B | 最佳竞品 |
|---|---|---|
| ScienceQA_TEST | 98.76 | 97.97 (InternVL3-8B) |
| ScienceQA_VAL | 98.81 | 97.81 (InternVL3-8B) |
| MTVQA_TEST | 32.18 | 30.30 (InternVL3-8B) |
| RefCOCO (Avg) | 91.01 | 91.40 (InternVL3-78B) |
尤其在科学推理任务上优势明显。
2. OCR 与文档理解
| 基准测试 | Qianfan-VL-70B | 表现 |
|---|---|---|
| OCRBench | 873 | 接近 SOTA |
| DocVQA_VAL | 94.75% | 仅次于 Qwen2.5-VL-72B |
| ChartQA_TEST | 89.6 | 显著优于多数基线 |
| TextVQA_VAL | 84.48 | 属第一梯队 |
在 DocVQA(文档视觉问答)任务中,能准确回答“合同第5条约定的违约金是多少?”这类结构化查询。
3. 数学推理能力
| 基准测试 | Qianfan-VL-8B | Qianfan-VL-70B | 当前最优 |
|---|---|---|---|
| MathVista-mini | 69.19 | 78.60 | 71.1 (InternVL3-78B) |
| MathVerse | 48.40 | 61.04 | 49.26 (Qwen2.5-VL-72B) |
| InHouse Dataset B | 61.33 | 75.60 | - |
Qianfan-VL-70B 在内部测试集上的表现远超同类模型,显示其在实际业务场景中的强泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











