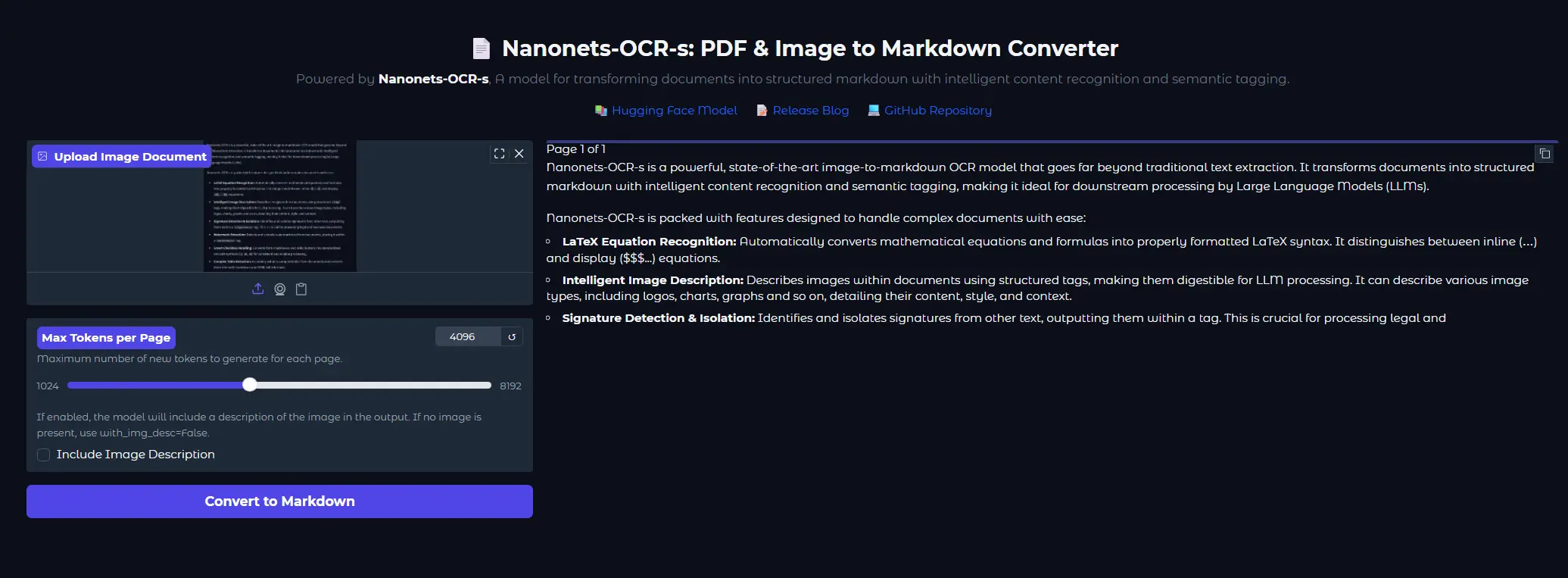
苹果发布多模态统一模型Manzano,它能够同时理解和生成视觉内容。该模型通过结合一个混合图像标记化器和精心设计的训练方案,显著减少了在理解和生成能力之间的性能权衡。Manzano 在统一模型中实现了对图像和文本的双向处理,展现出强大的多模态交互能力。

主要功能
- 图像理解:Manzano 能够理解图像内容并回答与图像相关的问题。
- 文本到图像生成:Manzano 可以根据文本描述生成相应的图像。
- 图像编辑:Manzano 支持基于文本指令的图像编辑,如风格转换、图像修复等。
主要特点
- 混合图像标记化器:Manzano 使用了一个统一的视觉编码器,通过两个轻量级适配器分别生成用于理解任务的连续嵌入和用于生成任务的离散标记。
- 联合训练方案:Manzano 在理解与生成数据上进行了联合训练,使得模型在两种任务上都能取得优秀的性能。
- 扩散解码器:Manzano 采用了扩散解码器将生成的图像标记转换为像素,提升了生成图像的质量。
工作原理
Manzano 的架构包括三个核心组件:
- 混合图像标记化器:由标准的视觉变换器(ViT)作为视觉骨干,连续适配器和离散适配器分别负责生成连续和离散的图像特征。
- 统一的自回归语言模型(LLM)解码器:接受文本标记和/或连续图像嵌入,并自回归地预测下一个离散图像或文本标记。
- 图像解码器:将预测的图像标记渲染为图像像素。
训练过程分为三个阶段:
- 预训练:在大规模文本、图像理解及生成数据上进行预训练。
- 持续预训练:在高质量的图像理解与生成数据上进一步训练。
- 监督微调(SFT):使用精心策划的文本、图像理解及生成指令数据进行微调,以增强指令遵循能力和提升两种任务的性能。
测试结果
Manzano 在多个图像理解和生成基准测试中取得了出色的成绩:
- 在图像理解任务中,Manzano 在多个基准测试中超过了现有的统一模型,并在文本丰富的任务上与专门的模型相媲美。
- 在图像生成任务中,Manzano 在 GenEval 和 WISE 基准测试中取得了与专用模型相当的性能。
- 在模型扩展行为的研究中,随着 LLM 解码器和图像解码器规模的增加,Manzano 在理解与生成任务上的性能均得到了显著提升,这验证了其架构和训练方案的有效性和可扩展性。
应用场景
Manzano 的应用前景非常广泛,包括但不限于以下领域:
- 内容创作:用于生成创意图像和视频,支持广告、游戏和影视行业的内容创作。
- 教育和研究:帮助学生和研究人员更好地理解和使用多模态数据,促进跨学科的研究。
- 人机交互:提升智能系统对人类语言和视觉的综合理解,增强交互体验。
- 医疗和健康:辅助医学图像分析和诊断,提供更准确的视觉信息解读。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











