
字节跳动Seed团队近日推出一款面向复杂操作任务的大规模机器人模型——Seed GR-3(Generalist Robot Model-3)。该模型具备良好的泛化能力,支持长序列任务执行与多模态指令理解,在真实环境中展现出对新物体、新环境和抽象指令的稳定应对能力。
与此同时,团队还发布了配套的双臂移动机器人平台 ByteMini,集成GR-3后可完成包括双手协同、底盘移动在内的多种高难度操作任务。这一组合为通用机器人系统的研发提供了新的技术路径。
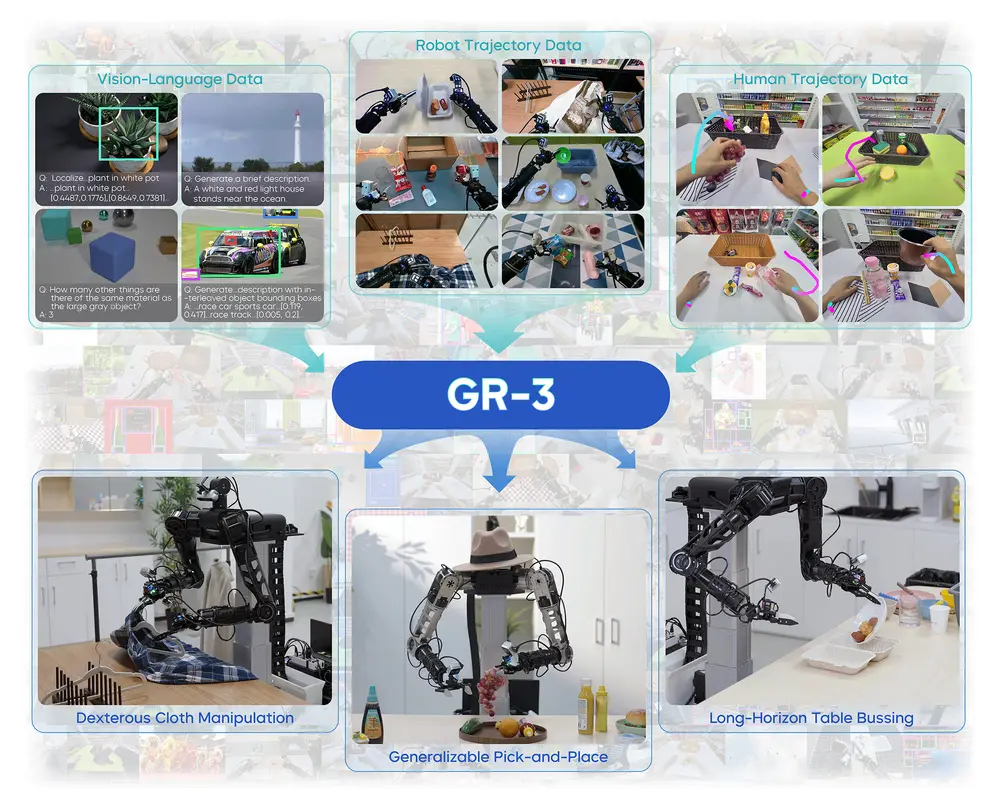
什么是Seed GR-3?
GR-3 是一个视觉-语言-动作(Vision-Language-Action, VLA)架构的大模型,旨在让机器人具备更强的理解力与执行力。它不仅能“看懂”环境、“听懂”指令,还能生成连贯、精准的动作序列。
其核心优势体现在三个方面:
- 强泛化能力:能处理训练中未见过的物体、环境和抽象指令;
- 高效微调机制:仅需少量人类操作轨迹即可快速适配新任务;
- 长周期任务稳定性:可连续执行包含多个子步骤的复杂任务,且响应准确。
这些能力的背后,是多元化的训练策略与高质量数据的融合。
如何训练?三种数据协同驱动
GR-3 的训练依托于三类关键数据源,形成从语义理解到动作生成的闭环学习体系:
- 大规模视觉-语言数据联合预训练
利用互联网级图像-文本对进行跨模态对齐训练,使模型建立物体外观与语言描述之间的深层关联。这是实现泛化能力的基础。 - VR采集的人类操作轨迹微调
通过用户授权的VR设备收集人类在虚拟环境中执行任务的动作轨迹,用于指导模型学习自然的操作逻辑。这类数据成本低、覆盖广,显著提升了模型对未知物体的适应能力。 - 真实机器人模仿学习
基于实际机器人在物理世界中执行任务的轨迹数据,进一步精调动作策略,确保输出动作符合动力学约束并具备实用性。
这种“先语义、再行为、最后落地”的分阶段训练方式,使得GR-3既拥有广泛的知识基础,又能转化为可靠的物理操作。
核心能力验证
1. 指令跟随与泛化能力测试
团队在典型的“拾取-放置”任务中设置了四项评估场景,检验模型在不同条件下的表现:
| 测试场景 | 内容说明 |
|---|---|
| 基础场景(Basic) | 环境与物品均为训练中已见 |
| 未知环境 | 在4个全新布局的空间中测试 |
| 未知指令 | 包含抽象概念的新指令,如“把看起来最旧的东西收起来” |
| 未知物品 | 使用45种训练未见的新物体 |
结果表明,GR-3 在所有场景下均优于基线模型,尤其在“未知指令”和“未知物品”任务中优势明显。移除视觉-语言预训练后,模型性能显著下降,证明该环节对泛化至关重要。
此外,加入人类轨迹数据微调后,即使每类物体仅有1条示范轨迹,模型也能提升对新物体的操作成功率;当数据增至10条/物体时,成功率持续上升,而对已有物体的表现几乎不受影响——显示出高效的增量学习潜力。
2. 长序列任务中的稳健表现
现实中的机器人任务往往是多步骤、长时间跨度的。为此,团队设计了“清理餐桌”任务作为测试基准:
- 长程模式(Flat):输入单一指令“清理餐桌”,要求模型自主分解并完成全过程;
- 指令遵循模式(Instruction Following):逐条下发子任务指令,如“把餐盒放进垃圾桶”“将筷子放入抽屉”,要求严格按序执行。
实验发现,GR-3 在两种模式下均表现良好,但在“指令遵循”任务中显著优于其他模型。这说明其不仅具备任务规划能力,还能准确跟踪动态变化的指令流,适用于需要人机协作或实时调整的场景。
3. 柔性物体操作:挑战传统难题
柔性物体(如衣物、绳索)因形变复杂、状态难以建模,一直是机器人操作的难点。为此,团队设置了“挂衣服”任务进行测试:
机器人需完成以下流程:
- 识别散乱堆放的衣服;
- 抓取衣架并穿入衣领;
- 将衣服平稳挂在指定晾衣杆上。
尽管训练数据中仅包含长袖衣物,GR-3 却能成功泛化至短袖、连帽衫等未见款式。即便衣物折叠、堆叠严重,模型仍能稳定完成操作,体现出较强的感知-动作耦合能力。
硬件载体:双臂移动机器人 ByteMini
为了验证GR-3在实体平台上的可行性,团队同步推出了 ByteMini ——一款集灵巧操作与移动能力于一体的双臂机器人。
主要特性包括:
- 双7自由度机械臂,支持精细抓取与双手协同;
- 全向移动底盘,适应家庭与办公环境;
- 多传感器融合系统(RGB-D相机、力控末端等),保障操作安全性;
- 模块化设计,便于部署与维护。
GR-3 作为其“大脑”,负责高层决策与动作生成;ByteMini 则作为执行终端,将模型输出转化为精确的物理动作。二者结合,实现了从算法到应用的完整闭环。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











