Google DeepMind 正式推出 T5Gemma 2——新一代基于 Gemma 3 架构的编码器-解码器(Encoder-Decoder)模型系列。它不仅继承了 Gemma 3 的先进特性,更首次在该家族中引入多模态理解与超长上下文支持,同时通过架构优化显著提升参数效率,适用于研究与设备端部署。
- 官方介绍:https://blog.google/technology/developers/t5gemma-2/
- 模型:https://huggingface.co/collections/google/t5gemma-2
核心定位:高效、多模态、长上下文
T5Gemma 2 并非简单重训,而是对 T5Gemma 的全面升级:
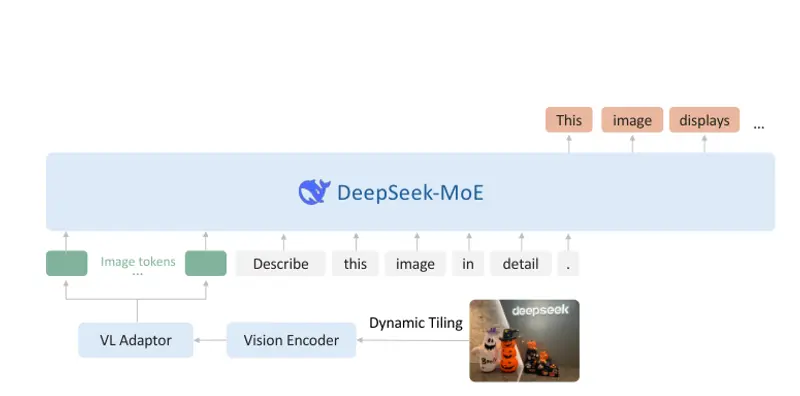
- 多模态能力:支持图像与文本联合理解;
- 128K 令牌上下文窗口:可处理超长文档或复杂视觉-语言任务;
- 紧凑参数规模:提供三档配置,兼顾性能与部署成本:
- 270M-270M(总计约 3.7 亿参数)
- 1B-1B(约 17 亿)
- 4B-4B(约 70 亿)
所有版本均不含视觉编码器参数,视觉部分需额外集成(如 SigLIP、PaliGemma 编码器)。

架构创新:更少参数,更强能力
为在小规模下最大化效率,T5Gemma 2 引入两项关键改进:
1. 绑定词嵌入(Tied Embeddings)
编码器与解码器共享词表嵌入矩阵,显著减少参数量,尤其提升 270M 等小模型的内存效率。
2. 合并注意力机制(Merged Attention)
将解码器中的自注意力与交叉注意力融合为单一注意力层:
- 降低模型深度与计算开销;
- 改善模型并行化效率;
- 加速推理,适合设备端部署。
这些设计使 T5Gemma 2 在相同硬件上可承载更复杂的任务逻辑。
能力升级:源自 Gemma 3 的新一代特性
T5Gemma 2 全面继承 Gemma 3 的核心技术:
| 能力 | 说明 |
|---|---|
| 多模态理解 | 通过高效视觉编码器(如 SigLIP)接入,支持视觉问答、图文推理等任务 |
| 128K 上下文 | 基于 Gemma 3 的交替局部-全局注意力机制,有效建模长距离依赖 |
| 140+ 语言支持 | 在更广泛、多样化的多语言语料上预训练,开箱即用 |
性能表现
在多项基准测试中,T5Gemma 2 显著超越前代 T5Gemma 与 Gemma 3(同参数量仅解码器版本):
- 多模态任务:在视觉问答(VQA)、图文匹配等指标上优于纯文本 Gemma 3;
- 长上下文处理:得益于独立编码器,对长文档摘要、跨段落推理表现更优;
- 通用能力:在代码生成、逻辑推理、多语言翻译等任务中普遍领先。
注:当前发布版本为预训练检查点,未包含指令微调或 RLHF 模型。官方鼓励社区基于此进行后训练以适配具体任务。
适用场景
- 学术研究:探索高效编码器-解码器架构、多模态对齐、长上下文建模;
- 设备端 AI:270M/1B 版本适合手机、嵌入式设备部署;
- 定制化应用:作为基础模型,微调用于文档摘要、多模态客服、跨模态检索等场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...