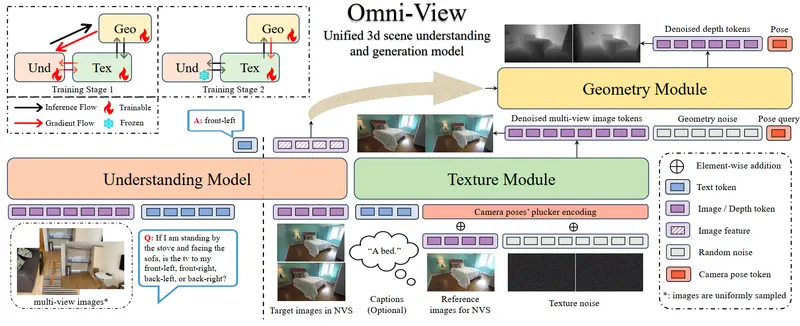
北京大学、阿里巴巴国际数字商业集团、中国科学院自动化研究所与 TeleAI 联合提出 Omni-View —— 一个面向多视角图像输入的统一3D场景理解与生成模型。该工作首次在端到端框架中系统性验证了 “生成促进理解”(Generation-Aided Understanding) 的有效性:即通过联合训练新视角合成与几何估计等生成任务,显著提升模型对3D场景的语义理解能力。
- 项目主页:https://jkhu29.github.io/omni_view
- GitHub:https://github.com/AIDC-AI/Omni-View
- 模型:https://huggingface.co/AIDC-AI/Omni-View
在标准基准 VSI-Bench 上,Omni-View 取得 55.4 分,超越多个专用3D理解模型;同时在 Re10k 等数据集的新视角合成任务中,也在 PSNR、SSIM 和 LPIPS 等指标上达到领先水平。
核心理念:生成即理解
传统3D理解模型通常仅聚焦于语义解析(如问答、物体定位),而 Omni-View 认为:要真正“理解”一个3D场景,模型必须有能力“重建”它。
通过迫使模型从有限视角生成新视图并估计几何结构,其对空间布局、物体遮挡、材质连续性等隐含关系的建模能力被显著强化,进而反哺高层语义理解。
模型架构:三位一体的协同设计
Omni-View 基于 Bagel 架构扩展,由三个核心组件构成:
| 模块 | 功能 | 技术特点 |
|---|---|---|
| 理解模型 | 接收多视角图像,回答关于场景的语义问题(如“桌子左边有什么?”) | 基于多视图视觉-语言对齐,输出结构化文本响应 |
| 纹理模块 | 生成目标视角下的逼真图像(新视角合成) | 利用时空注意力机制建模外观一致性 |
| 几何模块 | 估计深度图与相机姿态,提供显式3D几何约束 | 与纹理模块协同,确保生成视图的几何合理性 |
三个模块共享视觉特征,但任务解耦:理解模型关注“是什么”,生成模块关注“如何呈现”和“空间关系如何”。
两阶段训练策略
为平衡理解与生成性能,Omni-View 采用分阶段优化:
- 联合预训练阶段
- 同时训练理解、纹理、几何三个模块
- 通过几何重建损失(如深度一致性)和自回归图像生成损失,驱动模型学习3D结构先验
- 此阶段重点提升理解能力,生成任务作为正则化手段
- 生成微调阶段
- 冻结理解模型参数
- 仅优化纹理与几何模块,提升新视角合成的图像质量与细节保真度
- 确保最终输出可用于高质量3D内容生成
实验结果
✅ 3D场景理解(VSI-Bench)
- 得分:55.4,显著优于纯理解模型(如 3D-LLM、VISTA 等)
- 尤其在涉及空间推理(“物体A是否在B后面?”)和跨视角一致性(“从另一角度看,椅子还在吗?”)的问题上优势明显
✅ 新视角合成(Re10k 数据集)
| 方法 | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| Omni-View | 28.7 | 0.92 | 0.08 |
| Instant-NGP | 27.1 | 0.89 | 0.11 |
| MVSNeRF | 26.5 | 0.87 | 0.13 |
数值表明 Omni-View 在图像保真度与感知自然度上均领先。
意义与影响
- 验证“生成促进理解”范式:为多模态具身智能提供新思路——理解不必孤立进行,可借力生成任务的结构约束
- 统一框架的实用性:单一模型同时支持问答、重建、编辑,降低部署复杂度
- 推动3D基础模型发展:为未来支持文本/语音/多模态输入的3D智能体奠定技术基础
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...