在图形用户界面(GUI)自动化任务中,让多模态大语言模型(MLLM)准确执行自然语言指令,远不只是“点击坐标”那么简单。真正的挑战在于:既要精准定位界面上的元素(空间对齐),又要正确理解指令背后的意图(语义对齐)。
例如,当用户说“用相机搜索这个物体”,模型不仅要识别出“相机”图标的位置,还要判断哪个图标真正具备“图像搜索”功能——这可能不是最显眼的那个相机按钮,而是隐藏在输入框旁的小镜头图标。
现有方法如可验证奖励强化学习(RLVR)虽在提升空间定位精度方面取得进展,但在复杂语义场景下仍表现乏力。其核心瓶颈在于:探索效率低。模型容易陷入“信心陷阱”——反复尝试相似动作,却难以跳出已有认知去发现真正符合语义逻辑的操作路径。
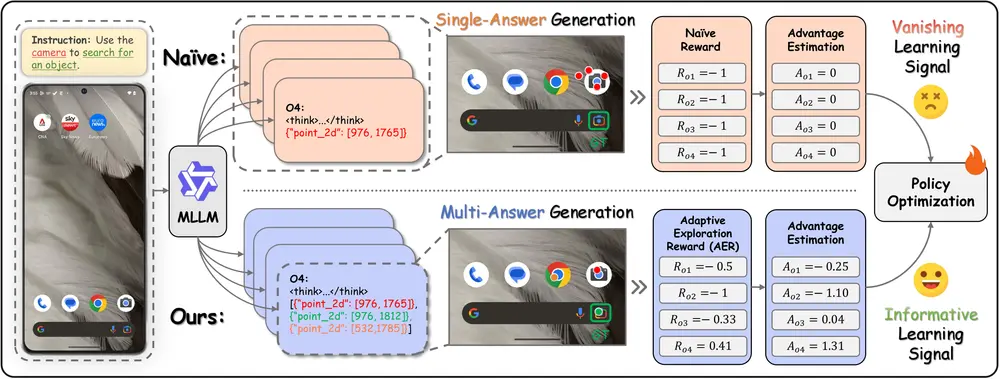
为突破这一限制,来自浙江大学、香港理工大学、InfiX.ai、芝加哥大学与亚马逊的研究团队联合提出 InfiGUI-G1 ——一个通过自适应探索策略优化(AEPO) 训练的新框架,显著提升了 MLLM 在 GUI 操作任务中的语义对齐能力。
- GitHub:https://github.com/InfiXAI/InfiGUI-G1
- InfiGUI-G1-3B:https://huggingface.co/InfiX-ai/InfiGUI-G1-3B
- InfiGUI-G1-7B:https://huggingface.co/InfiX-ai/InfiGUI-G1-7B
问题本质:为什么“找得到”不等于“做对了”?
GUI 操作任务可以形式化为:给定一张界面截图和一条自然语言指令,模型需输出一个动作(如点击坐标)。理想情况下,这个动作应同时满足:
- 空间对齐:点击位置精确对应目标控件;
- 语义对齐:所选控件功能上符合指令意图。
然而,现实中的界面设计多样,功能相同的控件可能形态各异(如“放大镜”图标 vs “搜索”文字按钮),而外观相似的控件功能却可能完全不同。这就要求模型具备更强的语义推理能力,而非依赖视觉匹配或固定模式。
传统强化学习方法依赖单一动作采样,在复杂语境下探索效率低下。一旦初始策略稍有偏差,后续训练容易陷入局部最优,无法覆盖潜在的正确动作路径。
解决方案:AEPO 框架如何提升探索效率?
InfiGUI-G1 的核心是 自适应探索策略优化(Adaptive Exploration Policy Optimization, AEPO),它从两个层面重构了模型的探索机制:
1. 多答案生成:一次前向传播,多个候选动作
不同于传统方法每次仅生成一个动作,AEPO 允许模型在单次前向传播中生成 N 个候选动作 $ \mathcal{A} = {p_1, p_2, ..., p_N} $。
这相当于让模型“多想几步”,在同一推理过程中尝试多种可能性,显著提高正确动作被采样的概率。实验表明,仅生成约 2 个候选动作,其覆盖率已超过基线模型 4 次独立采样的总和。
2. 自适应探索奖励(AER):动态平衡探索与利用
为了引导这种多样化探索,研究团队设计了 自适应探索奖励函数(Adaptive Exploration Reward, AER),其理论基础来自效率公式:
基于效率比率 (其中 是效用, 是成本)设计的奖励函数,动态调整探索和利用的平衡。
其中 U 表示动作带来的效用(是否成功), C 是探索成本(如动作数量或不确定性)。AER 根据该比率动态调整奖励信号:
- 当某候选动作成功时,给予高奖励,并适度抑制过度探索;
- 当所有动作均失败时,则鼓励更大范围的探索,避免陷入盲区。
这种机制使得模型能在“坚持已有经验”和“尝试新路径”之间实现动态平衡,有效缓解“信心陷阱”。
训练方法:RLOO + AEPO,高效优化策略
InfiGUI-G1 采用 Reinforce Leave-One-Out(RLOO) 算法进行策略优化。其核心思想是:
对于每组生成的多个候选动作,逐个将其排除,用其余动作作为对比基准,计算当前动作的相对优势。这种方式能更稳定地估计策略梯度,减少方差,提升训练效率。
结合 AEPO 的多动作生成与 AER 奖励机制,整个训练过程在有限数据下实现了更高的样本利用率。
性能表现:小数据,大提升
InfiGUI-G1 在多个主流 GUI 推理基准上进行了全面测试,结果展现出显著优势:
✅ 主流基准表现(部分)
| 基准 | 模型 | 准确率 |
|---|---|---|
| ScreenSpot-Pro | InfiGUI-G1-3B | 45.2% |
| Naive RLVR-3B | 40.4% | |
| InfiGUI-G1-7B | 51.9% | |
| Naive RLVR-7B | 46.5% | |
| UI-Vision | InfiGUI-G1-3B | 89.7% |
| InfiGUI-G1-7B | 87.4% |
注:UI-Vision 上的表现优于其他 SOTA 方法。
✅ 探索效率对比
- InfiGUI-G1 平均每轮生成约 2 个候选动作;
- 即使 Naive RLVR 进行 4 次独立尝试,其命中正确答案的概率仍低于 InfiGUI-G1 的单次多动作生成。
✅ 难样本上的突破
在 ScreenSpot-Pro 的“难样本”子集上(涉及复杂语义推理):
- Naive RLVR-7B 准确率为 10.8%
- InfiGUI-G1-7B 提升至 17.4%,相对提升超过 60%
这说明 AEPO 特别擅长处理语义模糊或视觉干扰较大的任务。
关键优势总结
| 特性 | 说明 |
|---|---|
| 语义对齐增强 | 通过多动作探索与 AER 引导,显著提升对指令意图的理解能力 |
| 探索效率高 | 单次推理生成多个候选,避免重复采样带来的资源浪费 |
| 数据效率优异 | 仅使用 44k 样本训练,远少于同类方法常见的百万级数据需求 |
| 可扩展性强 | 框架通用,适用于不同规模的 MLLM(3B / 7B 已验证) |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











